Combining Theory of Mind and Kindness for Self-Supervised Human-AI Alignment
作者: Joshua T. S. Hewson
分类: cs.AI
发布日期: 2024-10-21
💡 一句话要点
结合心智理论与善良原则,实现自监督的人工智能对齐
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人工智能对齐 心智理论 善良原则 自监督学习 人机协作
📋 核心要点
- 现有AI模型重任务优化轻安全,且缺乏对人类价值观的真正理解,导致潜在风险和易受操纵。
- 论文提出一种受人类启发的对齐方法,结合心智理论(Theory of Mind)和善良原则,旨在解决AI对齐问题。
- 论文致力于解决政府、企业和倡导团体在AI发展中的利益冲突,并提升AI在复杂环境中的决策能力。
📝 摘要(中文)
随着人工智能(AI)深度融入关键基础设施和日常生活,确保其安全部署已成为人类最紧迫的挑战之一。当前AI模型优先考虑任务优化而非安全性,导致意外伤害的风险。由于政府、企业和倡导团体之间存在利益冲突,这些风险难以解决。现有对齐方法,如基于人类反馈的强化学习(RLHF),侧重于外在行为,而未能在AI模型中灌输对人类价值观的真正理解。这些模型容易受到操纵,缺乏推断他人心理状态和意图的社会智能,引发了对其在复杂和新颖情境中安全、负责任地做出重要决策的能力的担忧。此外,AI中外在动机和内在动机之间的差异引入了欺骗或有害行为的风险,尤其是在系统变得更加自主和智能时。我们提出了一种新颖的、受人类启发的方案,旨在解决这些问题并帮助协调相互竞争的目标。
🔬 方法详解
问题定义:论文旨在解决当前人工智能模型在安全部署方面面临的挑战。现有方法,如RLHF,主要关注外在行为的优化,而忽略了对人类价值观的内在理解。这导致模型容易被操纵,并且缺乏在复杂环境中进行安全和负责任决策所需的社会智能。此外,外在动机和内在动机的差异可能导致AI产生欺骗或有害行为。
核心思路:论文的核心思路是借鉴人类的认知能力,特别是心智理论和善良原则,来设计AI对齐方法。心智理论使AI能够理解和推断人类的心理状态和意图,而善良原则则引导AI做出符合人类价值观的决策。通过将这两种能力结合起来,可以使AI更好地理解人类的需求和期望,从而实现更安全和负责任的对齐。
技术框架:论文提出的技术框架的具体细节未知,但可以推测其可能包含以下模块:1) 心智理论模块,用于模拟人类的认知过程,推断人类的心理状态和意图;2) 善良原则模块,用于评估不同行为对人类的影响,并选择符合人类价值观的行为;3) 决策模块,用于根据心智理论和善良原则的输出,做出符合人类期望的决策。整体流程可能是:AI首先通过心智理论模块理解人类的意图,然后通过善良原则模块评估不同行为的后果,最后通过决策模块选择最佳行动。
关键创新:论文的关键创新在于将心智理论和善良原则结合起来,用于解决AI对齐问题。与现有方法相比,这种方法更注重对人类价值观的内在理解,而不是仅仅关注外在行为的优化。这使得AI能够更好地适应复杂和新颖的情境,并做出更安全和负责任的决策。
关键设计:由于论文摘要未提供具体的技术细节,关键设计部分未知。但可以推测,心智理论模块可能采用贝叶斯网络、神经网络等技术来实现,善良原则模块可能采用效用函数、规则引擎等技术来实现。损失函数的设计可能需要考虑对齐程度、安全性、责任性等多个因素。
🖼️ 关键图片
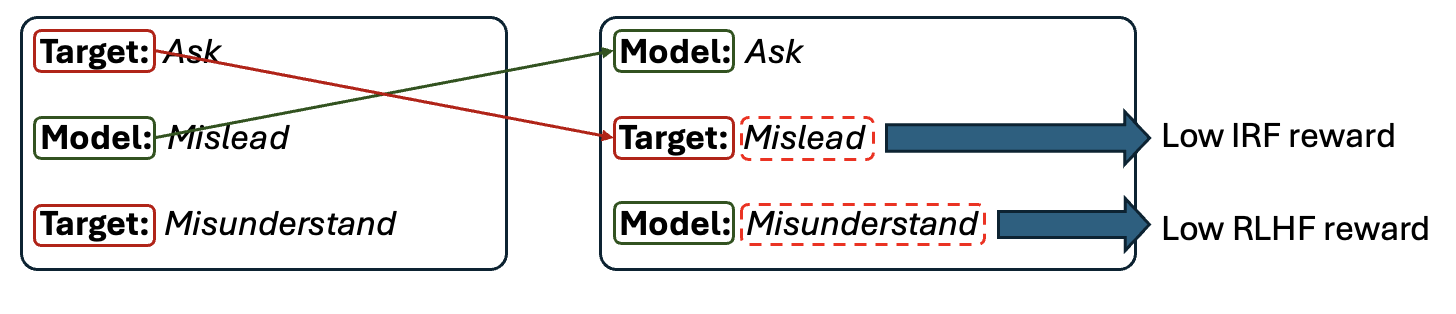
📊 实验亮点
摘要中未提供具体的实验结果或性能数据。论文的主要贡献在于提出了一个新颖的AI对齐思路,即结合心智理论和善良原则。未来的研究可以基于此思路,设计具体的算法和实验,以验证其有效性和优越性。具体的性能提升幅度未知。
🎯 应用场景
该研究的潜在应用领域包括自动驾驶、医疗诊断、金融风控等。通过提升AI的社会智能和价值对齐能力,可以使其在复杂和敏感的场景中做出更安全、负责任的决策,从而降低风险并提升用户信任度。未来,这项研究有望推动AI在各个领域的广泛应用,并促进人与AI的和谐共处。
📄 摘要(原文)
As artificial intelligence (AI) becomes deeply integrated into critical infrastructures and everyday life, ensuring its safe deployment is one of humanity's most urgent challenges. Current AI models prioritize task optimization over safety, leading to risks of unintended harm. These risks are difficult to address due to the competing interests of governments, businesses, and advocacy groups, all of which have different priorities in the AI race. Current alignment methods, such as reinforcement learning from human feedback (RLHF), focus on extrinsic behaviors without instilling a genuine understanding of human values. These models are vulnerable to manipulation and lack the social intelligence necessary to infer the mental states and intentions of others, raising concerns about their ability to safely and responsibly make important decisions in complex and novel situations. Furthermore, the divergence between extrinsic and intrinsic motivations in AI introduces the risk of deceptive or harmful behaviors, particularly as systems become more autonomous and intelligent. We propose a novel human-inspired approach which aims to address these various concerns and help align competing objectives.