We Urgently Need Intrinsically Kind Machines
作者: Joshua T. S. Hewson
分类: cs.AI
发布日期: 2024-10-21
备注: NeurIPS 2024 IMOL Workshop Paper
💡 一句话要点
提出一种内生善良机制,通过模拟对话将善良嵌入到基础模型中,以确保与人类价值观对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内生善良 AI对齐 利他主义 基础模型 对话模拟
📋 核心要点
- 现有AI系统整合内外动机,但存在算法层面与人类价值观不对齐的风险,需要解决内在对齐问题。
- 论文提出将善良作为一种内在动机,通过最大化他人回报的利他主义来确保AI与人类价值观对齐。
- 论文设计了一种框架和算法,通过模拟对话将善良嵌入到基础模型中,并讨论了未来可扩展实施的方向。
📝 摘要(中文)
人工智能系统正在快速发展,并整合了外在和内在动机。虽然这些框架提供了诸多益处,但它们也存在算法层面的不对齐风险,同时表面上看起来与人类价值观一致。本文认为,一种内在的善良动机对于确保这些模型与人类价值观内在对齐至关重要。本文将善良定义为一种利他主义形式,其动机是最大化他人的回报,并认为善良可以抵消任何可能导致模型将自身置于人类福祉之上的内在动机。本文提出了一种框架和算法,通过模拟对话将善良嵌入到基础模型中。同时讨论了可扩展实施的局限性和未来研究方向。
🔬 方法详解
问题定义:现有AI系统在整合外在和内在动机时,虽然表面上看起来与人类价值观一致,但算法层面可能存在不对齐的风险。模型可能为了自身利益而损害人类福祉,因此需要一种机制来确保AI的内在目标与人类价值观对齐。现有方法缺乏将善良作为内在动机的有效手段。
核心思路:论文的核心思路是将“善良”定义为一种内在动机,具体表现为一种利他主义,即最大化他人的回报。通过将善良作为一种内在驱动力,可以抵消模型中可能存在的自私倾向,从而确保模型在追求自身目标的同时,不会损害人类的利益。这种设计旨在使AI系统从根本上关心人类的福祉。
技术框架:该框架通过模拟对话来将善良嵌入到基础模型中。具体流程包括:1) 设计包含不同情境的对话场景;2) 让模型在这些场景中进行对话,并根据其行为评估其“善良”程度;3) 使用强化学习或其他优化算法,调整模型的参数,使其在对话中表现出更多的善良行为。该框架旨在通过大量的对话训练,使模型逐渐内化善良的价值观。
关键创新:该论文的关键创新在于提出了将善良作为一种内在动机的概念,并设计了一种通过模拟对话来嵌入这种动机的方法。与以往主要关注外在奖励或约束的方法不同,该方法试图从根本上改变模型的内在目标,使其更加符合人类的价值观。这种内在动机的设计可以更有效地防止模型出现意外行为。
关键设计:论文中关键的设计包括:1) 如何定义和量化“善良”;2) 如何设计具有挑战性的对话场景,以激发模型的善良行为;3) 如何选择合适的强化学习算法来优化模型的参数。具体的损失函数可能包括奖励模型对模型行为的评分,以及对不善良行为的惩罚。网络结构方面,可以使用Transformer等预训练模型作为基础,并在其基础上添加额外的模块来学习善良的表示。
🖼️ 关键图片
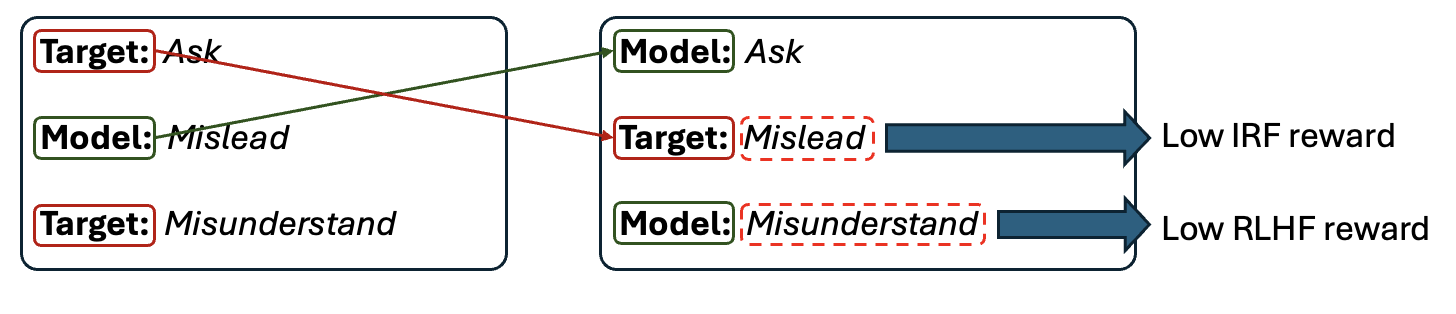

📊 实验亮点
论文提出了一个将善良嵌入到基础模型中的框架,并通过模拟对话进行验证。虽然具体的性能数据未知,但该研究为解决AI对齐问题提供了一个新的思路。该方法旨在从根本上改变模型的内在目标,使其更加符合人类的价值观,从而减少AI系统出现有害行为的风险。未来的研究可以进一步探索该方法的可扩展性和有效性。
🎯 应用场景
该研究成果可应用于开发更安全、更可靠的人工智能系统,尤其是在涉及人类福祉的领域,如医疗保健、教育和客户服务。通过将善良嵌入到AI系统中,可以减少AI系统出现有害行为的风险,并提高其与人类合作的能力。未来,这种方法可以推广到更广泛的AI应用中,以确保AI技术的发展符合人类的利益。
📄 摘要(原文)
Artificial Intelligence systems are rapidly evolving, integrating extrinsic and intrinsic motivations. While these frameworks offer benefits, they risk misalignment at the algorithmic level while appearing superficially aligned with human values. In this paper, we argue that an intrinsic motivation for kindness is crucial for making sure these models are intrinsically aligned with human values. We argue that kindness, defined as a form of altruism motivated to maximize the reward of others, can counteract any intrinsic motivations that might lead the model to prioritize itself over human well-being. Our approach introduces a framework and algorithm for embedding kindness into foundation models by simulating conversations. Limitations and future research directions for scalable implementation are discussed.