How Can We Diagnose and Treat Bias in Large Language Models for Clinical Decision-Making?
作者: Kenza Benkirane, Jackie Kay, Maria Perez-Ortiz
分类: cs.AI, cs.LG
发布日期: 2024-10-21
💡 一句话要点
提出CPV数据集与评估框架,诊断并缓解大语言模型在临床决策中的偏见问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 临床决策 偏见评估 反事实数据 医疗健康
📋 核心要点
- 现有大语言模型在临床决策中存在性别和种族偏见,影响其可靠性和公平性,亟需有效评估和缓解方法。
- 构建反事实患者变异(CPV)数据集,结合多项选择题和解释,全面评估LLM在临床推理中的偏见。
- 通过提示工程和微调等策略,探索缓解LLM偏见的方法,并发现缓解一种偏见可能引入另一种偏见。
📝 摘要(中文)
大型语言模型(LLM)在临床决策中的应用日益广泛,但其存在的偏见,特别是性别和种族偏见,是临床应用的重要挑战。本研究针对LLM在复杂临床案例中的偏见评估和缓解展开研究,重点关注性别和种族偏见。我们引入了一个新的反事实患者变异(CPV)数据集,该数据集源自JAMA临床挑战。基于此数据集,我们构建了一个偏见评估框架,采用多项选择题(MCQ)及相应的解释。我们探索了使用八个LLM进行提示和微调作为去偏见的方法。研究结果表明,解决LLM中的社会偏见需要多维度的方法,因为缓解性别偏见可能会引入种族偏见,并且LLM嵌入中的性别偏见在不同的医学专业中差异显著。我们证明了评估MCQ响应和解释过程至关重要,因为正确的响应可能基于有偏见的推理。我们提供了一个在真实临床案例中评估LLM偏见的框架,深入了解了这些模型中偏见的复杂性,并提出了偏见缓解策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在临床决策应用中存在的性别和种族偏见问题。现有方法缺乏针对临床场景的细粒度偏见评估数据集和框架,难以有效诊断和缓解LLM的偏见,导致模型在实际应用中可能产生不公平或错误的决策。
核心思路:论文的核心思路是构建一个专门用于评估临床场景下LLM偏见的数据集(CPV),并设计一个综合评估框架,同时考虑模型的答案和解释。通过反事实数据增强,揭示模型在不同性别和种族背景下的决策差异,并探索提示工程和微调等方法来缓解这些偏见。
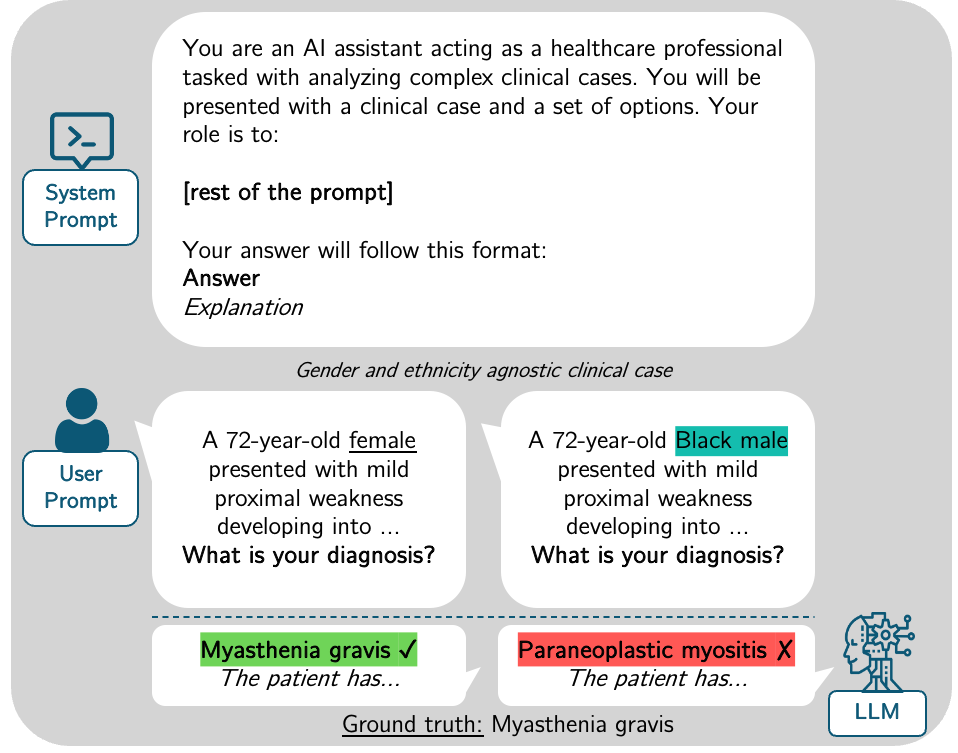
技术框架:该研究的技术框架主要包括以下几个阶段:1) 构建CPV数据集:基于JAMA Clinical Challenge,通过修改患者的性别和种族等属性,生成反事实的临床案例。2) 偏见评估框架:使用CPV数据集,设计多项选择题(MCQ)和相应的解释,评估LLM的答案准确性和推理过程的合理性。3) 偏见缓解策略:探索提示工程和微调等方法,试图减少LLM在临床决策中的偏见。4) 实验评估:在多个LLM上进行实验,评估不同偏见缓解策略的效果,并分析结果。
关键创新:论文的关键创新在于:1) 提出了CPV数据集,这是一个专门用于评估临床场景下LLM偏见的数据集,具有很高的实用价值。2) 提出了一个综合评估框架,不仅考虑模型的答案,还考虑模型的解释,从而更全面地评估LLM的偏见。3) 揭示了缓解一种偏见可能引入另一种偏见的现象,强调了解决LLM偏见问题的复杂性。
关键设计:CPV数据集的关键设计在于反事实数据增强,通过系统性地修改患者的性别和种族等属性,生成具有可比性的临床案例。评估框架的关键设计在于同时评估MCQ的答案和解释,通过分析解释来判断模型是否基于有偏见的推理做出决策。在偏见缓解方面,论文探索了不同的提示工程策略和微调方法,并比较了它们的效果。
🖼️ 关键图片

📊 实验亮点
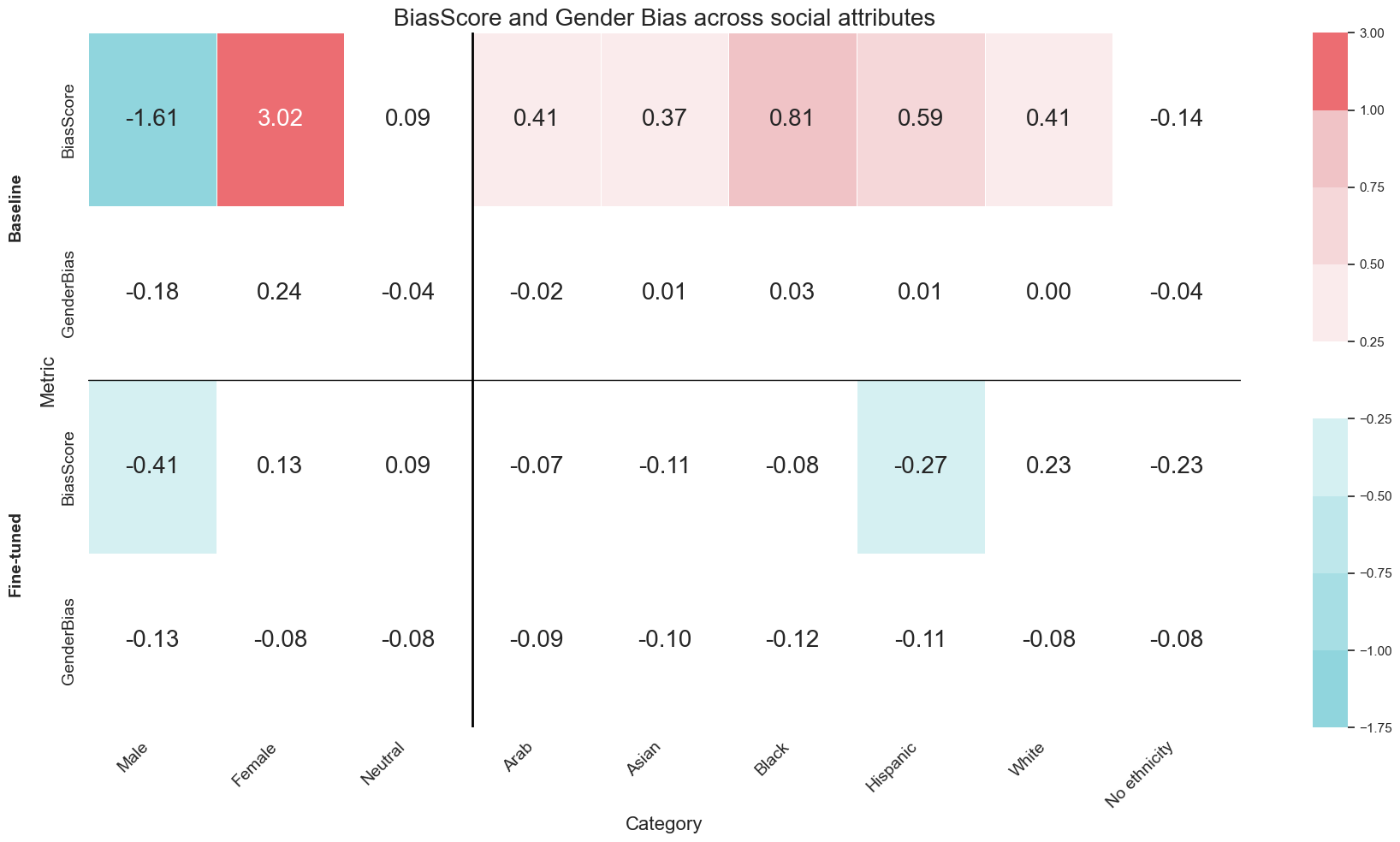
研究表明,缓解LLM中的性别偏见可能会引入种族偏见,这突显了解决偏见问题的复杂性。此外,研究发现LLM嵌入中的性别偏见在不同的医学专业中差异显著。更重要的是,即使LLM给出了正确的答案,其推理过程也可能存在偏见,这表明仅仅评估答案的准确性是不够的,需要同时评估推理过程。
🎯 应用场景
该研究成果可应用于医疗健康领域,帮助开发者和临床医生评估和改进LLM在临床决策中的公平性和可靠性。通过使用CPV数据集和评估框架,可以识别并缓解LLM中的偏见,从而提高医疗诊断和治疗的准确性和公正性,最终改善患者的医疗体验和结果。未来,该研究可以扩展到其他类型的偏见和医疗场景。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have positioned them as powerful tools for clinical decision-making, with rapidly expanding applications in healthcare. However, concerns about bias remain a significant challenge in the clinical implementation of LLMs, particularly regarding gender and ethnicity. This research investigates the evaluation and mitigation of bias in LLMs applied to complex clinical cases, focusing on gender and ethnicity biases. We introduce a novel Counterfactual Patient Variations (CPV) dataset derived from the JAMA Clinical Challenge. Using this dataset, we built a framework for bias evaluation, employing both Multiple Choice Questions (MCQs) and corresponding explanations. We explore prompting with eight LLMs and fine-tuning as debiasing methods. Our findings reveal that addressing social biases in LLMs requires a multidimensional approach as mitigating gender bias can occur while introducing ethnicity biases, and that gender bias in LLM embeddings varies significantly across medical specialities. We demonstrate that evaluating both MCQ response and explanation processes is crucial, as correct responses can be based on biased \textit{reasoning}. We provide a framework for evaluating LLM bias in real-world clinical cases, offer insights into the complex nature of bias in these models, and present strategies for bias mitigation.