AutoTrain: No-code training for state-of-the-art models
作者: Abhishek Thakur
分类: cs.AI
发布日期: 2024-10-21
🔗 代码/项目: GITHUB
💡 一句话要点
AutoTrain:一个无需代码即可训练先进模型的工具
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动化机器学习 无需代码 模型训练 Hugging Face 多模态学习
📋 核心要点
- 现有模型训练工具难以统一处理不同模态和任务,缺乏通用性和易用性。
- AutoTrain 旨在提供一个无需代码的通用平台,支持多种任务的模型训练和微调。
- AutoTrain Advanced 库提供了在自定义数据集上训练模型的最佳实践,支持本地和云端部署。
📝 摘要(中文)
随着开源模型的进步,在自定义数据集上训练(或微调)模型已成为开发针对特定工业或开源应用程序的解决方案的关键部分。然而,目前还没有一个工具可以简化跨不同类型模态或任务的训练过程。我们推出了 AutoTrain (又名 AutoTrain Advanced)——一个开源、无需代码的工具/库,可用于训练(或微调)用于不同类型任务的模型,例如:大型语言模型 (LLM) 微调、文本分类/回归、token 分类、序列到序列任务、句子转换器微调、视觉语言模型 (VLM) 微调、图像分类/回归,甚至表格数据上的分类和回归任务。AutoTrain Advanced 是一个开源库,提供在自定义数据集上训练模型的最佳实践。该库可在 https://github.com/huggingface/autotrain-advanced 获得。AutoTrain 可以在完全本地模式或云机器上使用,并且可以与 Hugging Face Hub 上共享的数万个模型及其变体一起使用。
🔬 方法详解
问题定义:现有模型训练流程复杂,需要大量专业知识和手动配置,难以满足不同模态和任务的需求。缺乏一个统一的、易于使用的工具,使得在自定义数据集上训练先进模型变得困难。
核心思路:AutoTrain 的核心思路是提供一个无需代码的自动化训练平台,通过预定义的最佳实践和简化的用户界面,降低模型训练的门槛,使得非专业人士也能轻松训练出高性能的模型。
技术框架:AutoTrain 的整体架构包含以下几个主要模块:数据预处理模块、模型选择模块、训练配置模块、训练执行模块和模型评估模块。用户只需提供数据集和选择任务类型,AutoTrain 即可自动完成模型训练的整个流程。该框架支持多种模态的数据,包括文本、图像和表格数据。
关键创新:AutoTrain 的关键创新在于其无需代码的特性和对多种任务类型的支持。它通过预定义的最佳实践和自动化流程,简化了模型训练的过程,降低了对专业知识的需求。此外,AutoTrain 还支持与 Hugging Face Hub 的集成,方便用户使用和分享模型。
关键设计:AutoTrain 的关键设计包括:自动数据预处理流程,根据任务类型自动选择合适的模型架构,基于最佳实践的训练配置,以及自动化的模型评估和性能报告生成。具体参数设置和损失函数等细节会根据任务类型和模型架构进行自动调整,用户无需手动干预。
🖼️ 关键图片

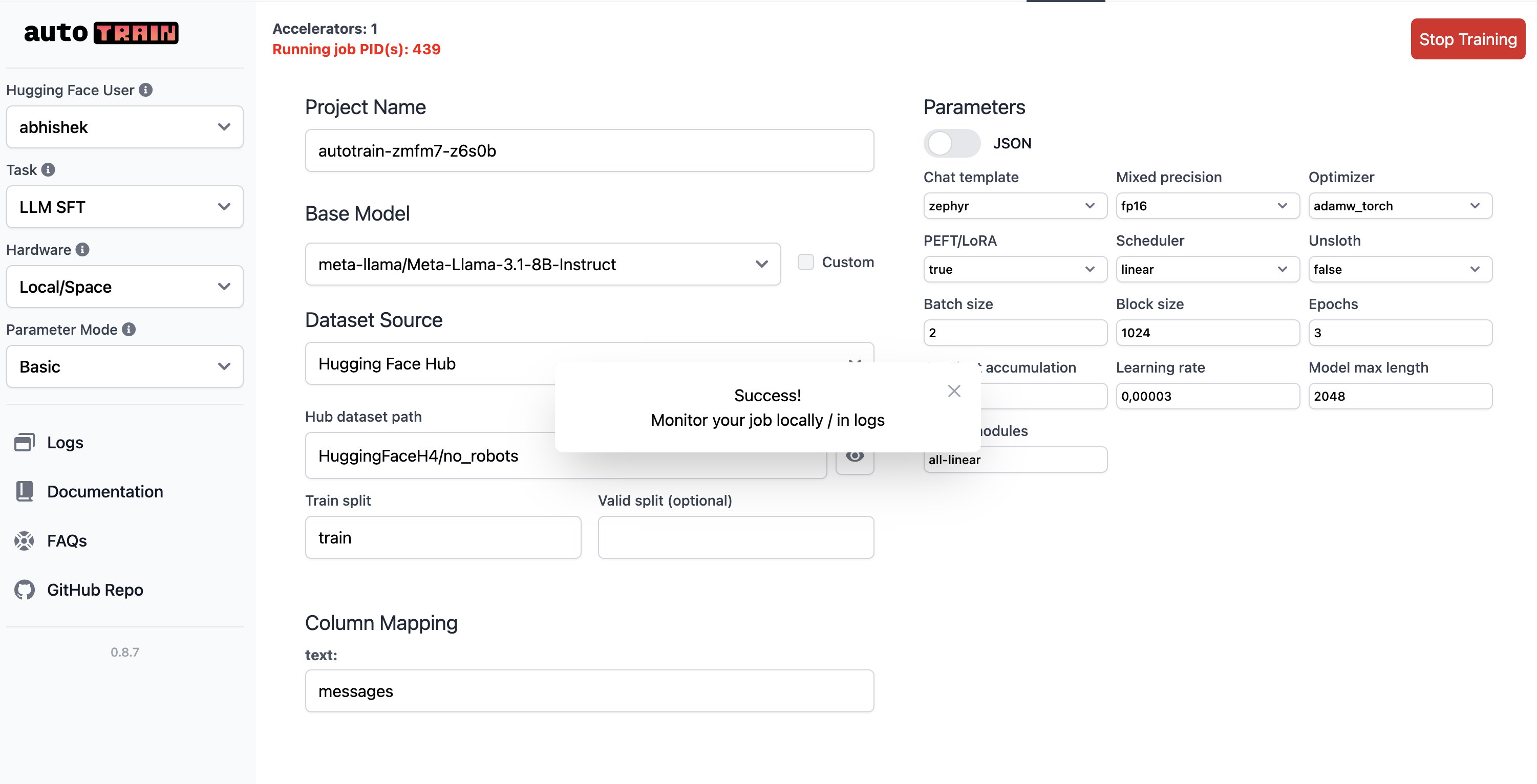
📊 实验亮点
论文介绍了 AutoTrain 的基本功能和架构,并展示了其在不同任务上的应用。虽然没有提供具体的性能数据和对比基线,但强调了 AutoTrain 在简化模型训练流程和降低使用门槛方面的优势。AutoTrain 通过无需代码的方式,使得更多的人能够参与到模型训练中来,从而加速了人工智能技术的发展。
🎯 应用场景
AutoTrain 具有广泛的应用前景,可用于各种需要定制化模型训练的场景,例如:自然语言处理、计算机视觉、推荐系统等。它可以帮助企业和研究人员快速构建针对特定任务的高性能模型,加速人工智能应用的开发和部署。未来,AutoTrain 有望成为一个重要的模型训练平台,推动人工智能技术的普及和发展。
📄 摘要(原文)
With the advancements in open-source models, training (or finetuning) models on custom datasets has become a crucial part of developing solutions which are tailored to specific industrial or open-source applications. Yet, there is no single tool which simplifies the process of training across different types of modalities or tasks. We introduce AutoTrain (aka AutoTrain Advanced) -- an open-source, no code tool/library which can be used to train (or finetune) models for different kinds of tasks such as: large language model (LLM) finetuning, text classification/regression, token classification, sequence-to-sequence task, finetuning of sentence transformers, visual language model (VLM) finetuning, image classification/regression and even classification and regression tasks on tabular data. AutoTrain Advanced is an open-source library providing best practices for training models on custom datasets. The library is available at https://github.com/huggingface/autotrain-advanced. AutoTrain can be used in fully local mode or on cloud machines and works with tens of thousands of models shared on Hugging Face Hub and their variations.