InternLM2.5-StepProver: Advancing Automated Theorem Proving via Critic-Guided Search
作者: Zijian Wu, Suozhi Huang, Zhejian Zhou, Huaiyuan Ying, Zheng Yuan, Wenwei Zhang, Dahua Lin, Kai Chen
分类: cs.AI, cs.CL
发布日期: 2024-10-21 (更新: 2025-10-21)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
InternLM2.5-StepProver:通过评论家引导搜索提升自动定理证明能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动定理证明 大型语言模型 专家迭代 评论家模型 LEAN 形式化验证 强化学习
📋 核心要点
- 现有基于LLM的定理证明方法忽略了策略轨迹中的偏好信息,限制了搜索效率和证明深度。
- 提出一种证明器-评论家框架,利用评论家模型捕获偏好信息,指导证明器搜索,提升证明性能。
- 通过大规模专家迭代训练,InternLM2.5-StepProver的评论家显著提升了证明器性能,达到65.9%的证明成功率。
📝 摘要(中文)
大型语言模型(LLMs)已成为数学定理证明的强大工具,尤其是在使用LEAN等形式化语言时。一种常见的证明方法是LLM证明器迭代地构建证明策略,通常遵循最佳优先搜索方案。然而,这种方法常常忽略现有策略轨迹中的关键偏好信息,阻碍了对更深层证明的搜索。我们提出了一种直观而有效的方法,该方法利用评论家模型来捕获偏好信息,并在运行时指导证明器模型的搜索。在证明器-评论家框架下,应用超过20,000个CPU日的大规模专家迭代来进一步微调证明器和评论家。训练后的InternLM2.5-StepProver评论家显著提高了证明器模型的性能(从59.4%到65.9%)。我们还分析了评论家在专家迭代期间对定理证明过程各个方面的影响,从而深入了解其有效性。我们开源了我们的模型和搜索到的证明,可在https://github.com/InternLM/InternLM-Math 和 https://huggingface.co/datasets/internlm/Lean-Workbook 获取。
🔬 方法详解
问题定义:论文旨在解决自动定理证明中,大型语言模型在搜索证明策略时效率不高的问题。现有方法,如最佳优先搜索,通常忽略了已探索策略轨迹中的关键偏好信息,导致搜索过程缺乏方向性,难以找到更深层的证明。这种盲目搜索浪费了计算资源,并限制了证明的成功率。
核心思路:论文的核心思路是引入一个“评论家”模型,该模型能够学习并捕捉现有策略轨迹中的偏好信息。评论家模型通过分析已尝试的策略及其结果,学习哪些策略更有可能导向成功的证明。然后,评论家模型将这些偏好信息反馈给“证明器”模型,引导其在搜索过程中优先探索更有希望的策略。
技术框架:整体框架是一个证明器-评论家循环。首先,证明器模型生成一系列可能的证明策略。然后,这些策略被提交给环境(例如,LEAN证明系统)执行,并获得相应的反馈(例如,证明成功或失败)。接下来,评论家模型分析这些策略及其反馈,学习策略的优劣。评论家模型的输出被用作证明器模型的搜索指导,使其能够更有效地探索证明空间。这个过程通过大规模专家迭代进行训练,不断提升证明器和评论家模型的性能。
关键创新:最关键的创新点在于引入了评论家模型来显式地建模和利用策略偏好信息。与传统的盲目搜索方法相比,这种方法能够更有效地利用已有的搜索经验,从而提高搜索效率和证明成功率。评论家模型充当了一个“智能导航器”,引导证明器模型朝着更有希望的方向前进。
关键设计:论文中关键的设计包括:1) 评论家模型的训练方式,需要设计合适的损失函数来鼓励评论家模型准确地预测策略的优劣;2) 证明器模型如何有效地利用评论家模型的输出,例如,可以通过调整搜索算法的优先级或引入新的策略生成机制;3) 大规模专家迭代的训练策略,需要平衡探索和利用,以避免陷入局部最优解。
🖼️ 关键图片


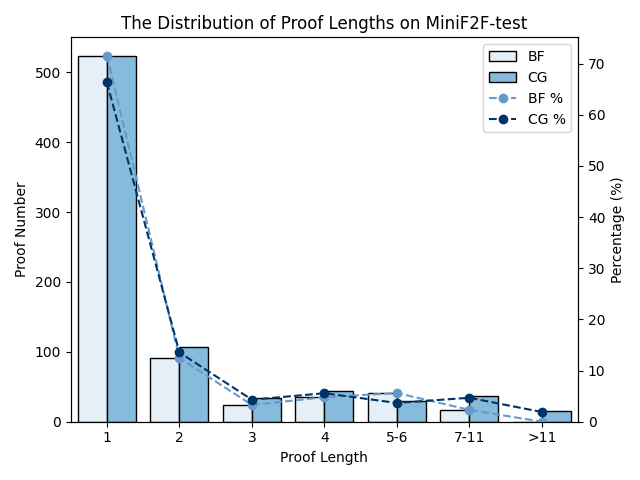
📊 实验亮点
实验结果表明,引入评论家模型后,证明器模型的性能显著提升,证明成功率从59.4%提高到65.9%。这表明评论家模型能够有效地指导证明器模型的搜索,提高证明效率。此外,论文还分析了评论家模型在专家迭代过程中对定理证明过程各个方面的影响,提供了有价值的见解。
🎯 应用场景
该研究成果可应用于自动化数学定理证明、程序验证、AI安全等领域。通过提升自动定理证明的能力,可以加速数学研究和软件开发,提高软件的可靠性和安全性。未来,该方法有望扩展到更复杂的推理任务,例如自然语言理解和知识图谱推理。
📄 摘要(原文)
Large Language Models (LLMs) have emerged as powerful tools in mathematical theorem proving, particularly when utilizing formal languages such as LEAN. A prevalent proof method involves the LLM prover iteratively constructing the proof tactic by tactic, typically following a best-first search scheme. However, this method often ignores the critical preference information inside the existing tactic trajectories, hindering the search for deeper proofs. We propose an intuitive yet effective method, which utilizes a critic model to capture the preference information and to guide the search of the prover model at runtime. Given the prover-critic framework, a large-scale expert iteration with more than 20,000 CPU days is then applied to further fine-tune the prover and the critic. The trained InternLM2.5-StepProver critic significantly boosts the performance of the prover model (59.4% to 65.9%). We also analyze the impact of the critic on various aspects of the theorem proving process during expert iteration, providing insights into its effectiveness. We open-source our models and searched proofs at https://github.com/InternLM/InternLM-Math and https://huggingface.co/datasets/internlm/Lean-Workbook.