Hallucination Detox: Sensitivity Dropout (SenD) for Large Language Model Training
作者: Shahrad Mohammadzadeh, Juan David Guerra, Marco Bonizzato, Reihaneh Rabbany, Golnoosh Farnadi
分类: cs.AI, cs.CL, math.SP
发布日期: 2024-10-20 (更新: 2025-10-06)
备注: Accepted to ACL 2025, accepted to Safe Generative AI Workshop @ NeurIPS 2024. Camera-ready version for ACL 2025 (to appear). Submitted July 2025
期刊: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5538-5554, 2025
DOI: 10.18653/v1/2025.acl-long.276
💡 一句话要点
提出敏感度Dropout(SenD)以降低大语言模型训练中的幻觉现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 敏感度Dropout 模型训练 事实准确性
📋 核心要点
- 大型语言模型容易产生幻觉,即生成不准确或不相关的输出,降低了模型的可靠性。
- 论文提出敏感度Dropout(SenD)方法,通过在训练中动态dropout敏感的embedding维度,降低幻觉方差。
- 实验表明,SenD能显著提升Pythia和Llama模型的事实准确性,且不影响下游任务性能。
📝 摘要(中文)
随着大型语言模型(LLMs)日益普及,其可靠性问题,特别是由于幻觉(即事实不准确或不相关的输出)引起的担忧日益增加。本研究调查了训练动态中的不确定性与幻觉产生之间的关系。通过使用Pythia套件中的模型和多种幻觉检测指标,我们分析了幻觉趋势并识别了训练期间的显著方差。为了解决这个问题,我们提出了一种新的训练协议,即敏感度Dropout(SenD),旨在通过确定性地删除具有显著变异性的嵌入索引来减少训练期间的幻觉方差。此外,我们开发了一种无监督的幻觉检测指标,即高效特征分数(EES),它以2倍的速度逼近传统的特征分数。该指标被集成到我们的训练协议中,使SenD在计算上具有可扩展性,并且能够有效地减少幻觉方差。SenD将Pythia和Meta的Llama模型在测试时的可靠性提高了高达17%,并提高了Wikipedia、Medical、Legal和Coding领域的事实准确性,而不会影响下游任务的性能。
🔬 方法详解
问题定义:大型语言模型在生成文本时,经常出现“幻觉”现象,即生成不符合事实或逻辑的内容。现有的训练方法难以有效控制这种幻觉现象,导致模型在实际应用中的可靠性降低。论文关注训练过程中模型的不确定性与幻觉现象之间的关系,旨在找到一种方法来降低这种不确定性,从而减少幻觉。
核心思路:论文的核心思路是,训练过程中embedding向量某些维度的变化剧烈程度与幻觉的产生有关。通过识别并有选择性地dropout这些“敏感”的维度,可以降低模型的不确定性,从而减少幻觉。这种选择性的dropout策略被称为敏感度Dropout(SenD)。
技术框架:SenD方法主要包含以下几个阶段:1) 使用现有的LLM架构进行训练;2) 在训练过程中,计算每个embedding维度的敏感度,即该维度在训练过程中的变化程度;3) 根据敏感度,确定性地dropout一部分敏感度最高的维度;4) 继续训练模型。此外,论文还提出了一个高效的无监督幻觉检测指标EES,用于评估SenD的效果。
关键创新:SenD的关键创新在于,它不是随机地dropout embedding维度,而是根据维度在训练过程中的敏感度进行选择性dropout。这种方法能够更有效地降低模型的不确定性,从而减少幻觉。此外,EES指标提供了一种快速评估幻觉的手段,加速了实验迭代。
关键设计:SenD的关键设计包括:1) 敏感度的计算方法:论文中具体如何量化embedding维度的敏感度,例如使用方差或其他统计指标;2) dropout比例的确定:如何根据敏感度分布确定dropout的维度比例;3) EES指标的计算方法:如何高效地近似计算传统的EigenScore。
🖼️ 关键图片

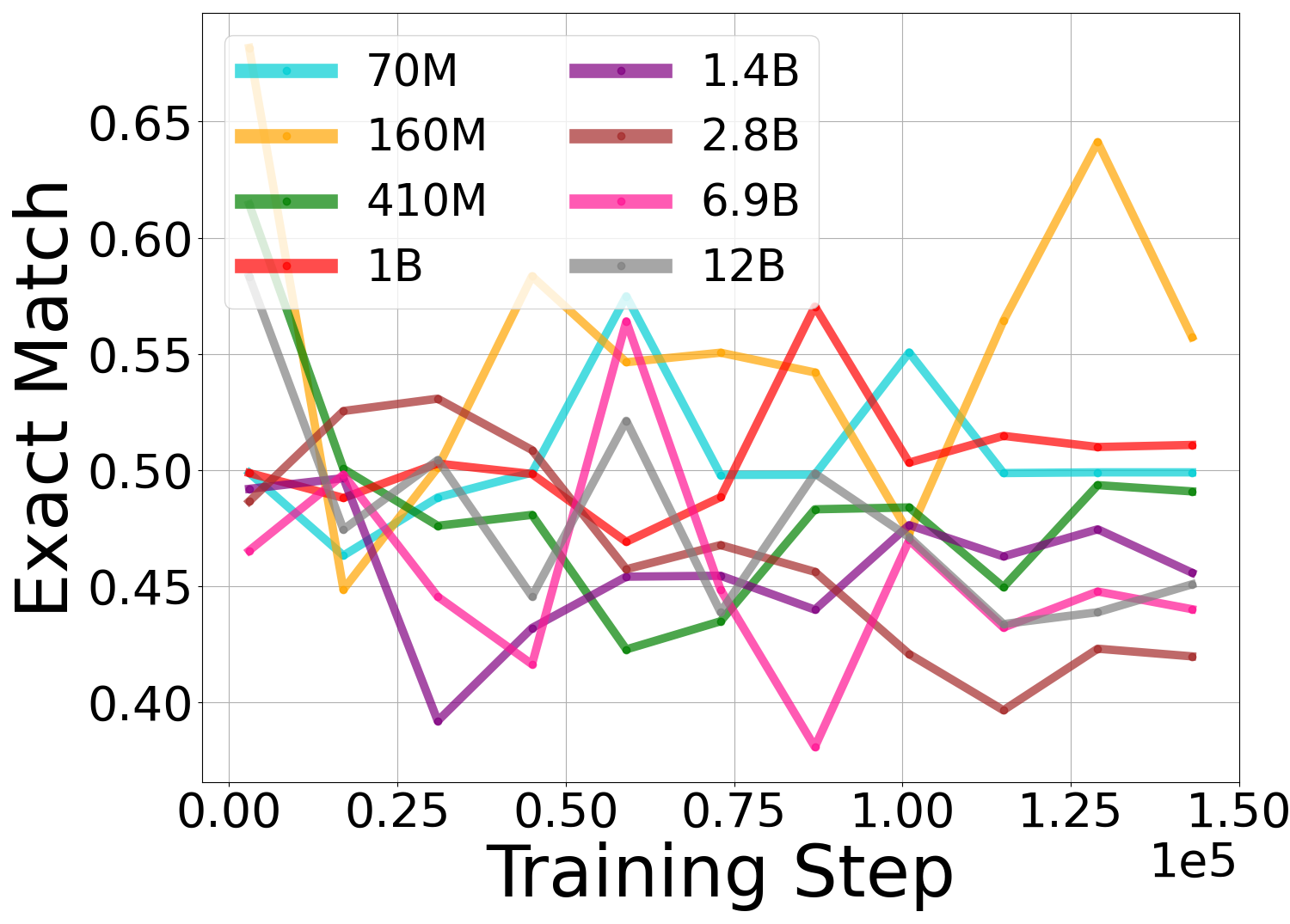
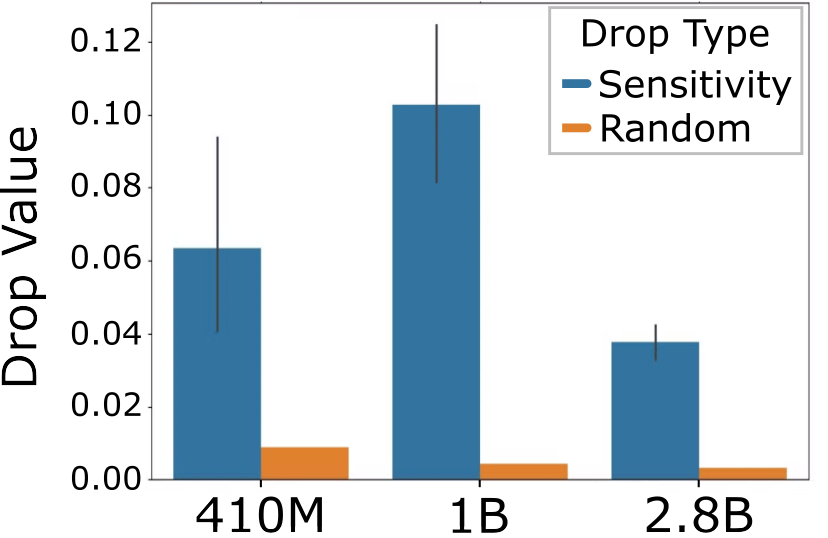
📊 实验亮点
实验结果表明,SenD方法能够显著提升Pythia和Llama模型的事实准确性,最高可达17%。在Wikipedia、Medical、Legal和Coding等多个领域,SenD都表现出优于基线模型的性能。重要的是,SenD在提升事实准确性的同时,并没有影响模型在下游任务上的表现,保证了模型的通用性。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的大型语言模型应用场景,例如智能客服、医疗诊断辅助、法律咨询等。通过降低模型产生幻觉的可能性,可以提高用户对模型的信任度,并减少因模型错误输出而造成的潜在风险。此外,该方法还可以促进LLM在开放域知识问答、内容生成等领域的更广泛应用。
📄 摘要(原文)
As large language models (LLMs) become increasingly prevalent, concerns about their reliability, particularly due to hallucinations - factually inaccurate or irrelevant outputs - have grown. Our research investigates the relationship between the uncertainty in training dynamics and the emergence of hallucinations. Using models from the Pythia suite and several hallucination detection metrics, we analyze hallucination trends and identify significant variance during training. To address this, we propose Sensitivity Dropout (SenD), a novel training protocol designed to reduce hallucination variance during training by deterministically dropping embedding indices with significant variability. In addition, we develop an unsupervised hallucination detection metric, Efficient EigenScore (EES), which approximates the traditional EigenScore in 2x speed. This metric is integrated into our training protocol, allowing SenD to be both computationally scalable and effective at reducing hallucination variance. SenD improves test-time reliability of Pythia and Meta's Llama models by up to 17% and enhances factual accuracy in Wikipedia, Medical, Legal, and Coding domains without affecting downstream task performance.