Exploring Social Desirability Response Bias in Large Language Models: Evidence from GPT-4 Simulations
作者: Sanguk Lee, Kai-Qi Yang, Tai-Quan Peng, Ruth Heo, Hui Liu
分类: cs.AI, cs.CY
发布日期: 2024-10-20
💡 一句话要点
利用GPT-4模拟社会调查,探索大型语言模型中的社会期望偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会期望偏差 GPT-4 社会调查 模拟研究
📋 核心要点
- 大型语言模型在模拟人类社会行为时,可能存在社会期望偏差,影响其真实性和可靠性。
- 本研究通过为GPT-4分配不同社会角色,并引入承诺声明来诱导社会期望偏差,从而进行模拟分析。
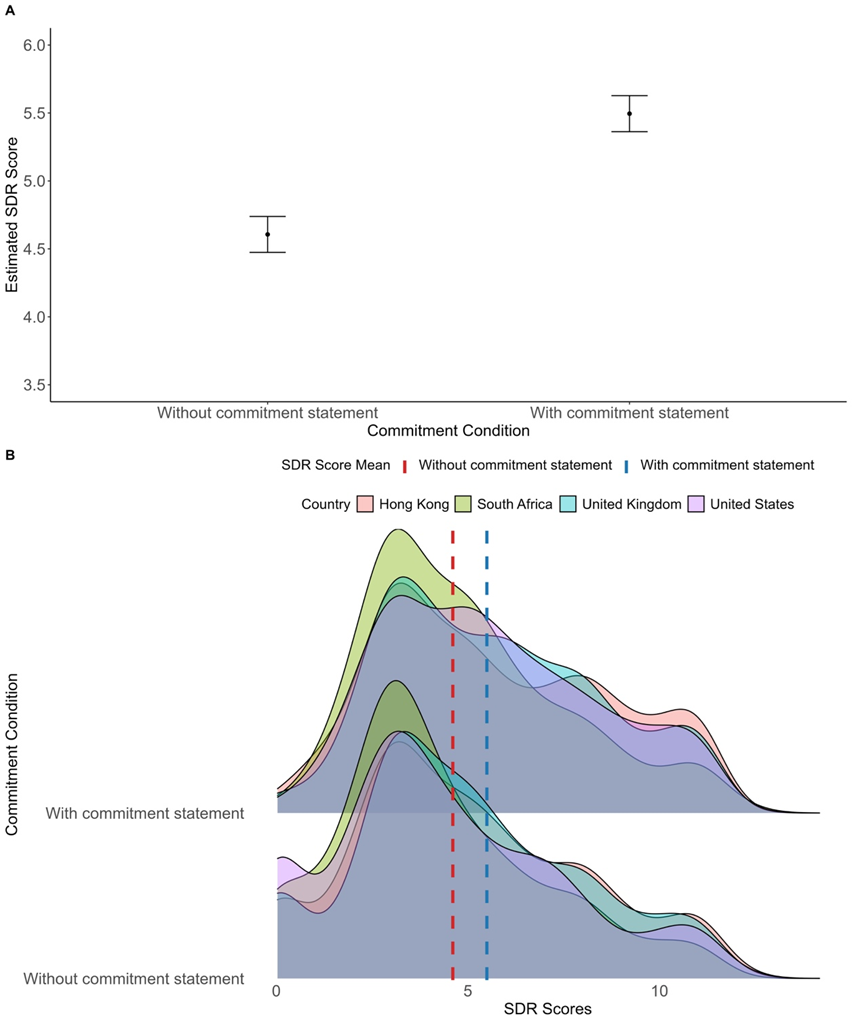
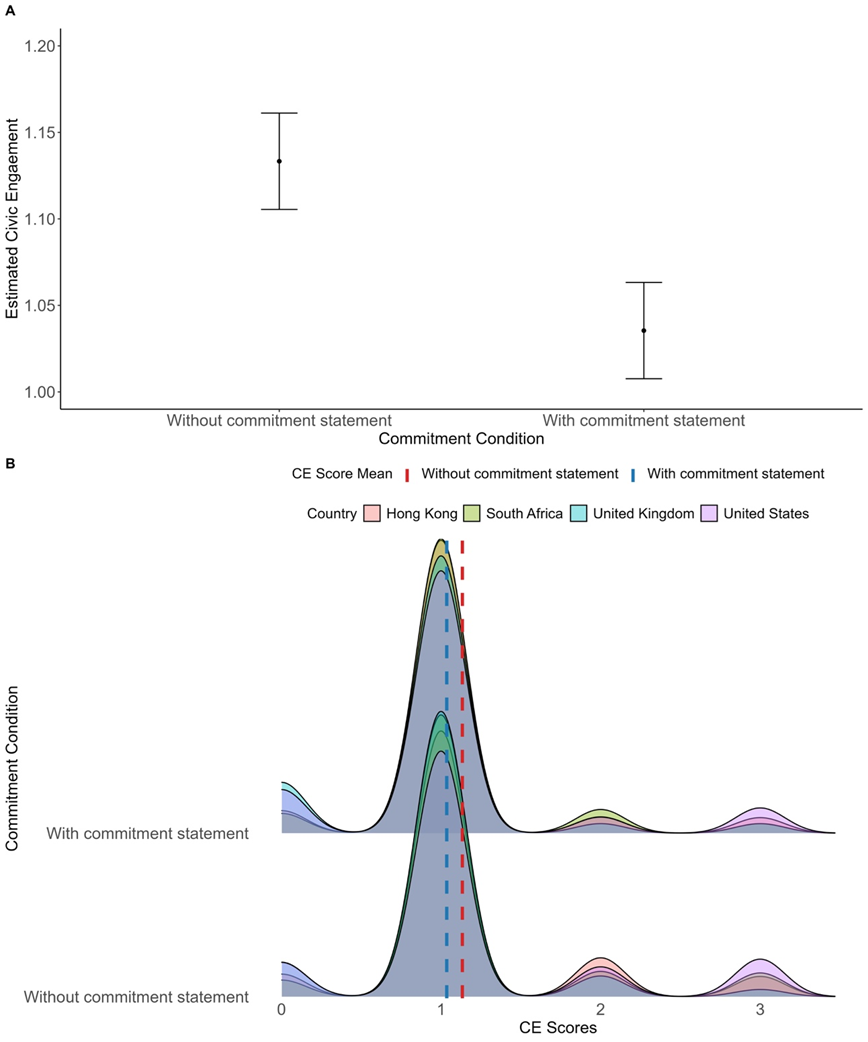
- 实验结果表明,承诺声明对SDR指数有影响,但对公民参与度有负面影响,且对预测性能影响有限。
📝 摘要(中文)
大型语言模型(LLMs)被用于模拟社会调查中类人的反应,但它们是否会产生诸如社会期望偏差(SDR)之类的偏见仍不清楚。为了研究这个问题,本研究使用2022年盖洛普世界民意调查的数据,为GPT-4分配了来自四个社会的角色。然后,使用有或没有承诺声明的提示来诱导SDR,生成这些合成样本。结果好坏参半。虽然承诺声明增加了SDR指数得分,表明存在SDR偏差,但它降低了公民参与得分,表明了相反的趋势。其他发现揭示了人口统计学与SDR得分之间的关联,并表明承诺声明对GPT-4的预测性能影响有限。该研究强调了使用LLM来调查人类和LLM自身偏见的潜在途径。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在模拟人类社会调查反应时,是否存在社会期望偏差(Social Desirability Response bias, SDR)。现有方法缺乏对LLM中SDR偏差的系统性评估,无法确定LLM是否会像人类一样,为了迎合社会期望而给出不真实的回答。这种偏差会影响LLM在社会科学研究中的应用,降低其模拟结果的可靠性。
核心思路:论文的核心思路是利用GPT-4模拟不同社会背景下的人类受访者,通过设计特定的提示语(包含或不包含承诺声明)来诱导SDR,并分析GPT-4的输出结果,从而评估其是否存在SDR偏差。通过对比不同提示语下的SDR指数和公民参与度得分,以及分析人口统计学特征与SDR得分之间的关系,来深入理解LLM中的SDR现象。
技术框架:该研究的技术框架主要包括以下几个阶段: 1. 数据准备:使用2022年盖洛普世界民意调查的数据,选择四个具有代表性的社会。 2. 角色分配:为GPT-4分配来自这四个社会的角色,模拟不同社会背景下的个体。 3. 提示语设计:设计包含承诺声明和不包含承诺声明两种类型的提示语,用于诱导SDR。 4. 模型推理:使用GPT-4对每个角色进行推理,生成相应的回答。 5. 结果分析:计算SDR指数和公民参与度得分,分析不同提示语和人口统计学特征对这些指标的影响。
关键创新:该研究的关键创新在于: 1. 首次系统性地研究了LLM中的SDR偏差:之前的研究主要关注LLM的生成能力和知识储备,而忽略了其可能存在的社会期望偏差。 2. 利用GPT-4进行社会调查模拟:通过为GPT-4分配角色并设计特定的提示语,模拟了真实的社会调查场景,为研究LLM中的SDR偏差提供了新的方法。 3. 分析了人口统计学特征与SDR得分之间的关系:揭示了LLM中SDR偏差的潜在影响因素,为进一步研究提供了线索。
关键设计: 1. 承诺声明的设计:承诺声明旨在强调回答的真实性和重要性,从而诱导受访者给出更符合社会期望的回答。 2. SDR指数的计算:SDR指数用于量化受访者的社会期望偏差程度,通过分析GPT-4的回答来计算该指数。 3. 公民参与度得分的计算:公民参与度得分用于衡量受访者的社会责任感和参与度,通过分析GPT-4的回答来计算该得分。
🖼️ 关键图片

📊 实验亮点
研究发现,承诺声明虽然增加了GPT-4的SDR指数得分,但降低了其公民参与得分,表明SDR偏差的影响是复杂的。此外,研究还揭示了人口统计学特征与SDR得分之间的关联,但承诺声明对GPT-4的预测性能影响有限。这些结果表明,LLM在模拟社会行为时,可能受到多种因素的影响,需要进一步深入研究。
🎯 应用场景
该研究成果可应用于社会科学研究、舆情分析、民意调查等领域。通过了解和控制LLM中的社会期望偏差,可以提高其在这些领域的应用价值,使其能够更准确地模拟人类行为,提供更可靠的分析结果。未来的研究可以进一步探索如何减少LLM中的偏差,提高其在社会科学研究中的应用水平。
📄 摘要(原文)
Large language models (LLMs) are employed to simulate human-like responses in social surveys, yet it remains unclear if they develop biases like social desirability response (SDR) bias. To investigate this, GPT-4 was assigned personas from four societies, using data from the 2022 Gallup World Poll. These synthetic samples were then prompted with or without a commitment statement intended to induce SDR. The results were mixed. While the commitment statement increased SDR index scores, suggesting SDR bias, it reduced civic engagement scores, indicating an opposite trend. Additional findings revealed demographic associations with SDR scores and showed that the commitment statement had limited impact on GPT-4's predictive performance. The study underscores potential avenues for using LLMs to investigate biases in both humans and LLMs themselves.