HyQE: Ranking Contexts with Hypothetical Query Embeddings
作者: Weichao Zhou, Jiaxin Zhang, Hilaf Hasson, Anu Singh, Wenchao Li
分类: cs.IR, cs.AI
发布日期: 2024-10-20
🔗 代码/项目: GITHUB
💡 一句话要点
HyQE:利用假设查询嵌入提升检索增强系统中上下文排序性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强 上下文排序 大型语言模型 查询嵌入 假设查询 信息检索 零样本学习
📋 核心要点
- 现有上下文排序方法依赖嵌入相似度或微调LLM,前者效果欠佳,后者面临扩展性和领域依赖问题。
- HyQE框架利用预训练LLM基于上下文生成假设查询,并通过比较假设查询与原始查询的相似度进行排序。
- 实验表明,HyQE在多个基准测试中提升了排序性能,且无需LLM微调,具有良好的通用性和效率。
📝 摘要(中文)
在检索增强系统中,上下文排序技术常用于根据上下文与用户查询的相关性对检索到的上下文进行重新排序。一种常见方法是通过嵌入空间中上下文和查询之间的相似性来衡量这种相关性。然而,这种相似性往往无法准确捕捉相关性。另一种方法是使用大型语言模型(LLM)进行上下文排序,但当候选上下文数量增加且LLM的上下文窗口大小受到限制时,它们可能会遇到可扩展性问题。此外,这些方法通常需要使用特定领域的数据对LLM进行微调。本文提出了一种可扩展的排序框架,该框架结合了嵌入相似性和LLM的能力,而无需LLM微调。我们的框架使用预训练的LLM根据检索到的上下文来假设用户查询,并根据假设查询与用户查询之间的相似性对上下文进行排序。我们的框架在推理时是高效的,并且与许多其他检索和排序技术兼容。实验结果表明,我们的方法提高了多个基准测试中的排序性能。代码和数据已公开。
🔬 方法详解
问题定义:现有检索增强系统中,上下文排序旨在根据上下文与用户查询的相关性对检索到的上下文进行排序。然而,基于嵌入相似度的方法无法准确捕捉相关性,而基于LLM的方法则面临可扩展性问题(当候选上下文数量巨大时)以及需要针对特定领域进行微调的难题。
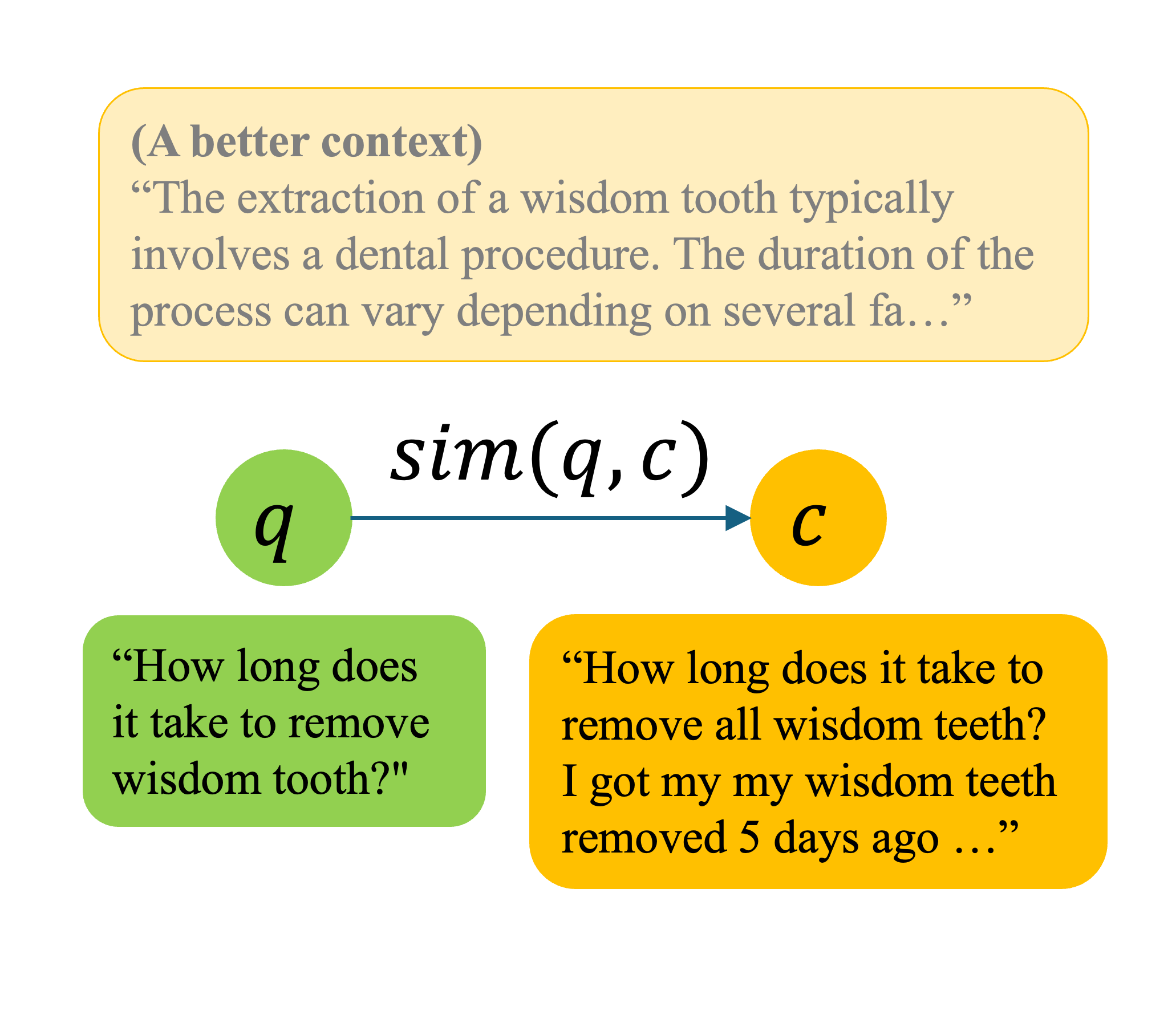
核心思路:HyQE的核心思路是利用LLM的生成能力,根据给定的上下文“反向”推断用户可能的查询意图,即生成一个“假设查询”。然后,通过比较这个假设查询与真实用户查询的相似度,来判断该上下文与用户真实意图的相关性。这种方法避免了直接比较上下文和查询的嵌入,从而更准确地捕捉相关性。
技术框架:HyQE框架包含以下主要步骤:1) 使用现有的检索方法(例如基于嵌入的检索)获取候选上下文;2) 对于每个候选上下文,使用预训练的LLM生成一个假设查询;3) 计算每个假设查询与原始用户查询的嵌入相似度;4) 根据相似度对候选上下文进行排序。整个框架可以与各种检索方法和LLM结合使用。
关键创新:HyQE的关键创新在于利用LLM的生成能力来“反向”推断查询意图,而不是直接比较上下文和查询的嵌入。这种方法能够更准确地捕捉上下文与用户意图的相关性,并且避免了对LLM进行微调的需求,从而提高了通用性和效率。
关键设计:HyQE的关键设计在于如何有效地利用预训练LLM生成高质量的假设查询。论文中可能使用了特定的prompt工程技术来引导LLM生成更准确的假设查询。此外,选择合适的嵌入模型来计算假设查询和原始查询之间的相似度也是一个重要的设计考虑因素。具体的损失函数和网络结构取决于所使用的LLM和嵌入模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,HyQE在多个基准测试中显著提升了上下文排序的性能。例如,在某些数据集上,HyQE可以将排序指标(如Recall@K或NDCG@K)提高几个百分点,超过了现有的基于嵌入相似度和微调LLM的方法。更重要的是,HyQE在无需LLM微调的情况下实现了这些提升,证明了其通用性和效率。
🎯 应用场景
HyQE可广泛应用于各种检索增强系统中,例如问答系统、对话系统、信息检索等。它可以提升这些系统在处理复杂查询和长文档时的性能,提高用户满意度。该方法无需领域特定数据的微调,降低了部署成本,具有很高的实际应用价值。未来,HyQE可以进一步扩展到多模态检索和跨语言检索等领域。
📄 摘要(原文)
In retrieval-augmented systems, context ranking techniques are commonly employed to reorder the retrieved contexts based on their relevance to a user query. A standard approach is to measure this relevance through the similarity between contexts and queries in the embedding space. However, such similarity often fails to capture the relevance. Alternatively, large language models (LLMs) have been used for ranking contexts. However, they can encounter scalability issues when the number of candidate contexts grows and the context window sizes of the LLMs remain constrained. Additionally, these approaches require fine-tuning LLMs with domain-specific data. In this work, we introduce a scalable ranking framework that combines embedding similarity and LLM capabilities without requiring LLM fine-tuning. Our framework uses a pre-trained LLM to hypothesize the user query based on the retrieved contexts and ranks the context based on the similarity between the hypothesized queries and the user query. Our framework is efficient at inference time and is compatible with many other retrieval and ranking techniques. Experimental results show that our method improves the ranking performance across multiple benchmarks. The complete code and data are available at https://github.com/zwc662/hyqe