SPA-Bench: A Comprehensive Benchmark for SmartPhone Agent Evaluation
作者: Jingxuan Chen, Derek Yuen, Bin Xie, Yuhao Yang, Gongwei Chen, Zhihao Wu, Li Yixing, Xurui Zhou, Weiwen Liu, Shuai Wang, Kaiwen Zhou, Rui Shao, Liqiang Nie, Yasheng Wang, Jianye Hao, Jun Wang, Kun Shao
分类: cs.AI
发布日期: 2024-10-19 (更新: 2025-03-31)
备注: ICLR 2025 Spotlight
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SPA-Bench:用于评估智能手机Agent的综合性基准测试平台。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 智能手机Agent 基准测试 多模态大语言模型 人机交互 自动化评估
📋 核心要点
- 现有智能手机Agent的评估缺乏多样化的任务范围和统一的评估标准,难以公平比较不同Agent的优劣。
- SPA-Bench提供了一个全面的基准测试,包含多样化的任务、即插即用的框架和自动化的多维度评估流程。
- 实验结果揭示了现有Agent在移动用户界面理解、动作定位和记忆保持等方面存在的挑战,为未来研究指明方向。
📝 摘要(中文)
本文提出了SPA-Bench,一个综合性的智能手机Agent基准测试平台,旨在评估基于(多模态)大型语言模型(MLLM)的Agent在模拟真实世界条件下的交互环境中的性能。SPA-Bench主要贡献包括:(1) 涵盖系统和第三方应用程序的多种任务,支持英语和中文,侧重于日常生活中常用的功能;(2) 一个即插即用的框架,支持Agent与Android设备进行实时交互,集成了十多个Agent,并具有灵活的可扩展性;(3) 一种新颖的评估流程,可以自动评估Agent在多个维度上的性能,包括与任务完成和资源消耗相关的七个指标。通过广泛的实验,揭示了Agent在理解移动用户界面、动作定位、记忆保持和执行成本等方面面临的挑战。最后,提出了未来的研究方向,以缓解这些困难,从而更接近实际的智能手机Agent应用。
🔬 方法详解
问题定义:现有基于(M)LLM的智能手机Agent在实际应用中面临诸多挑战,例如难以准确理解复杂的移动用户界面、难以将自然语言指令转化为精确的动作、以及难以在长时间交互中保持上下文信息。此外,缺乏一个统一的、全面的评估基准,使得不同Agent的性能比较变得困难,阻碍了该领域的发展。现有方法通常只关注特定任务或特定Agent,缺乏通用性和可扩展性。
核心思路:SPA-Bench的核心思路是构建一个模拟真实世界智能手机使用场景的交互环境,并提供一套全面的评估指标,从而能够客观、公平地评估不同Agent的性能。通过提供多样化的任务、即插即用的框架和自动化的评估流程,SPA-Bench旨在促进智能手机Agent领域的研究和发展。
技术框架:SPA-Bench包含三个主要组成部分:(1) 任务集:涵盖系统应用和第三方应用,包含英语和中文任务,模拟用户日常使用场景;(2) Agent交互框架:提供一个即插即用的平台,允许研究人员轻松集成和测试不同的Agent;(3) 评估流程:自动评估Agent在任务完成度、资源消耗等多个维度上的性能,提供全面的性能分析。
关键创新:SPA-Bench的关键创新在于其综合性和通用性。它不仅提供了一个多样化的任务集,还提供了一个灵活的Agent集成框架和一个自动化的评估流程。这使得研究人员能够在一个统一的平台上比较不同Agent的性能,并深入分析Agent的优缺点。此外,SPA-Bench还关注Agent在实际应用中面临的挑战,例如用户界面理解和动作定位。
关键设计:SPA-Bench的任务集设计侧重于模拟用户日常使用场景,包含各种常见的任务,例如发送短信、设置闹钟、浏览网页等。Agent交互框架采用模块化设计,允许研究人员轻松添加新的Agent和自定义评估指标。评估流程采用自动化的方式,可以高效地评估Agent在多个维度上的性能,例如任务完成时间、成功率、资源消耗等。具体的参数设置和损失函数取决于所使用的Agent的具体实现,SPA-Bench提供了一个通用的评估平台,可以支持各种不同的Agent。
🖼️ 关键图片
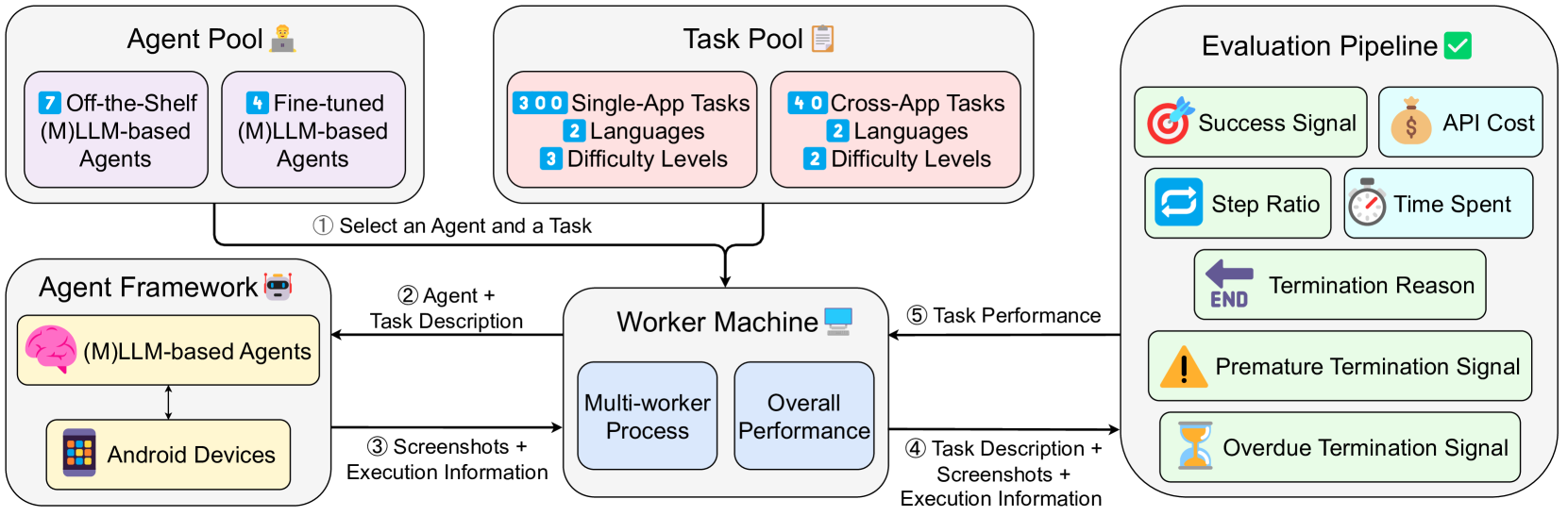

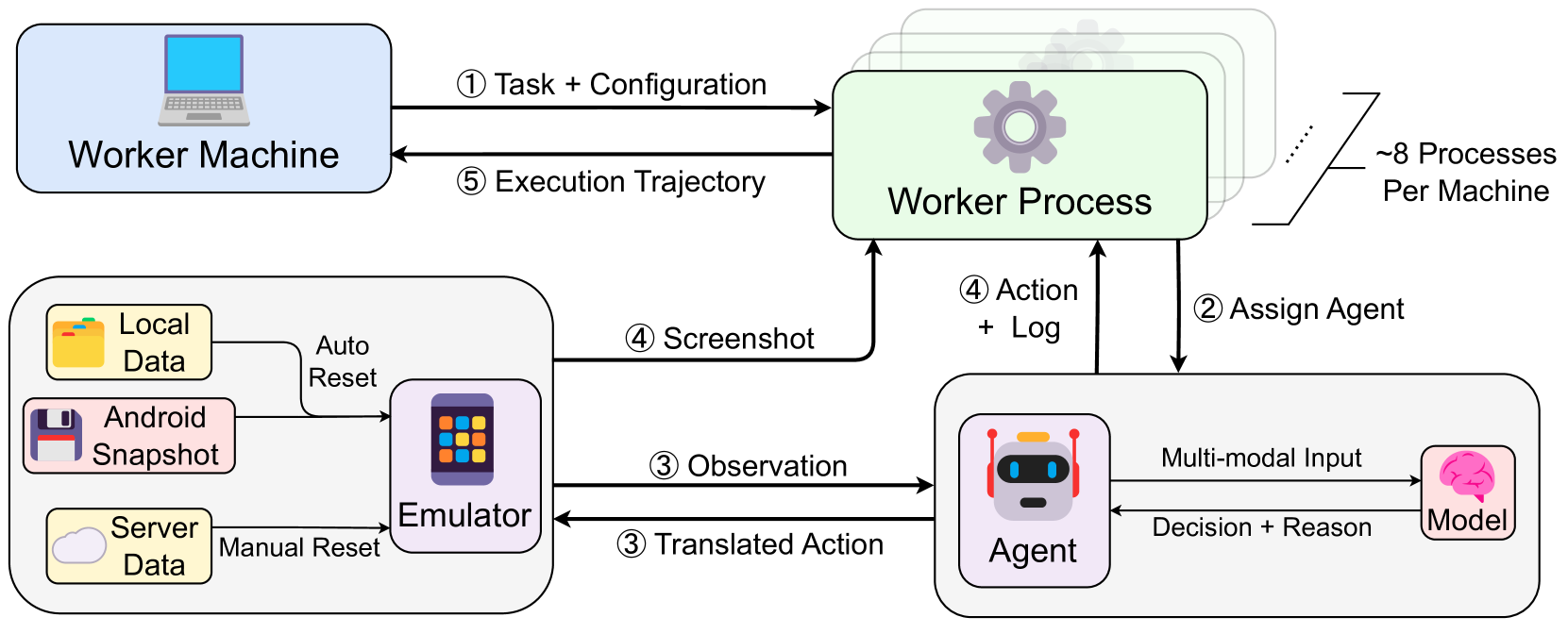
📊 实验亮点
SPA-Bench的实验结果表明,现有Agent在理解移动用户界面、动作定位和记忆保持等方面存在显著挑战。例如,某些Agent在处理复杂的用户界面时,任务完成率较低。此外,不同Agent在资源消耗方面也存在差异,某些Agent的执行成本较高。这些实验结果为未来的研究提供了重要的参考。
🎯 应用场景
SPA-Bench可用于评估和改进智能手机Agent,提高其在实际应用中的性能和用户体验。该基准测试平台能够推动智能手机Agent在自动化任务处理、智能助手、辅助技术等领域的应用,并促进人机交互技术的进步。未来,SPA-Bench可以扩展到其他移动设备和应用场景,例如智能家居、车载系统等。
📄 摘要(原文)
Smartphone agents are increasingly important for helping users control devices efficiently, with (Multimodal) Large Language Model (MLLM)-based approaches emerging as key contenders. Fairly comparing these agents is essential but challenging, requiring a varied task scope, the integration of agents with different implementations, and a generalisable evaluation pipeline to assess their strengths and weaknesses. In this paper, we present SPA-Bench, a comprehensive SmartPhone Agent Benchmark designed to evaluate (M)LLM-based agents in an interactive environment that simulates real-world conditions. SPA-Bench offers three key contributions: (1) A diverse set of tasks covering system and third-party apps in both English and Chinese, focusing on features commonly used in daily routines; (2) A plug-and-play framework enabling real-time agent interaction with Android devices, integrating over ten agents with the flexibility to add more; (3) A novel evaluation pipeline that automatically assesses agent performance across multiple dimensions, encompassing seven metrics related to task completion and resource consumption. Our extensive experiments across tasks and agents reveal challenges like interpreting mobile user interfaces, action grounding, memory retention, and execution costs. We propose future research directions to ease these difficulties, moving closer to real-world smartphone agent applications. SPA-Bench is available at https://ai-agents-2030.github.io/SPA-Bench/.