GlitchMiner: Mining Glitch Tokens in Large Language Models via Gradient-based Discrete Optimization
作者: Zihui Wu, Haichang Gao, Ping Wang, Shudong Zhang, Zhaoxiang Liu, Shiguo Lian
分类: cs.AI
发布日期: 2024-10-19 (更新: 2025-11-10)
🔗 代码/项目: GITHUB
💡 一句话要点
GlitchMiner:通过梯度引导的离散优化挖掘大语言模型中的Glitch Token
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Glitch Token 大语言模型 对抗攻击 梯度优化 预测熵 模型安全 鲁棒性评估
📋 核心要点
- 现有Glitch Token检测方法依赖启发式规则或统计异常,泛化性差,易漏检。
- GlitchMiner通过最大化预测熵,利用梯度引导局部搜索高效探索离散Token空间。
- 实验表明,GlitchMiner在多种LLM上显著提升了检测精度和查询效率。
📝 摘要(中文)
Glitch Token是指能够触发大语言模型(LLM)中不可预测或异常行为的输入,它们对模型的可靠性和安全性构成重大挑战。现有的检测方法主要依赖于启发式的嵌入模式或内部表示中的统计异常,这限制了它们在不同模型架构上的泛化能力,并可能遗漏偏离观察模式的异常。我们提出了GlitchMiner,一个行为驱动的框架,旨在通过最大化预测熵来识别Glitch Token。GlitchMiner利用梯度引导的局部搜索策略,高效地探索离散Token空间,而无需依赖于模型特定的启发式方法或大批量采样。在来自五个主要模型系列的十个LLM上的大量实验表明,GlitchMiner在检测精度和查询效率方面始终优于现有方法,为有效的Glitch Token发现提供了一种通用且可扩展的解决方案。
🔬 方法详解
问题定义:论文旨在解决大语言模型中Glitch Token的检测问题。现有方法主要依赖于启发式规则或模型内部表示的统计异常,这些方法泛化能力较弱,难以适应不同的模型架构,并且容易遗漏那些不符合预定义模式的Glitch Token。因此,需要一种更通用、更高效的方法来识别这些能够引发模型异常行为的特殊输入。
核心思路:GlitchMiner的核心思路是通过最大化预测熵来寻找Glitch Token。预测熵越高,意味着模型对下一个Token的预测越不确定,越有可能触发异常行为。通过优化输入Token,使得模型的预测熵最大化,从而找到能够引发模型混乱的Glitch Token。这种方法不依赖于模型内部的特定表示或预定义的模式,因此具有更好的泛化能力。
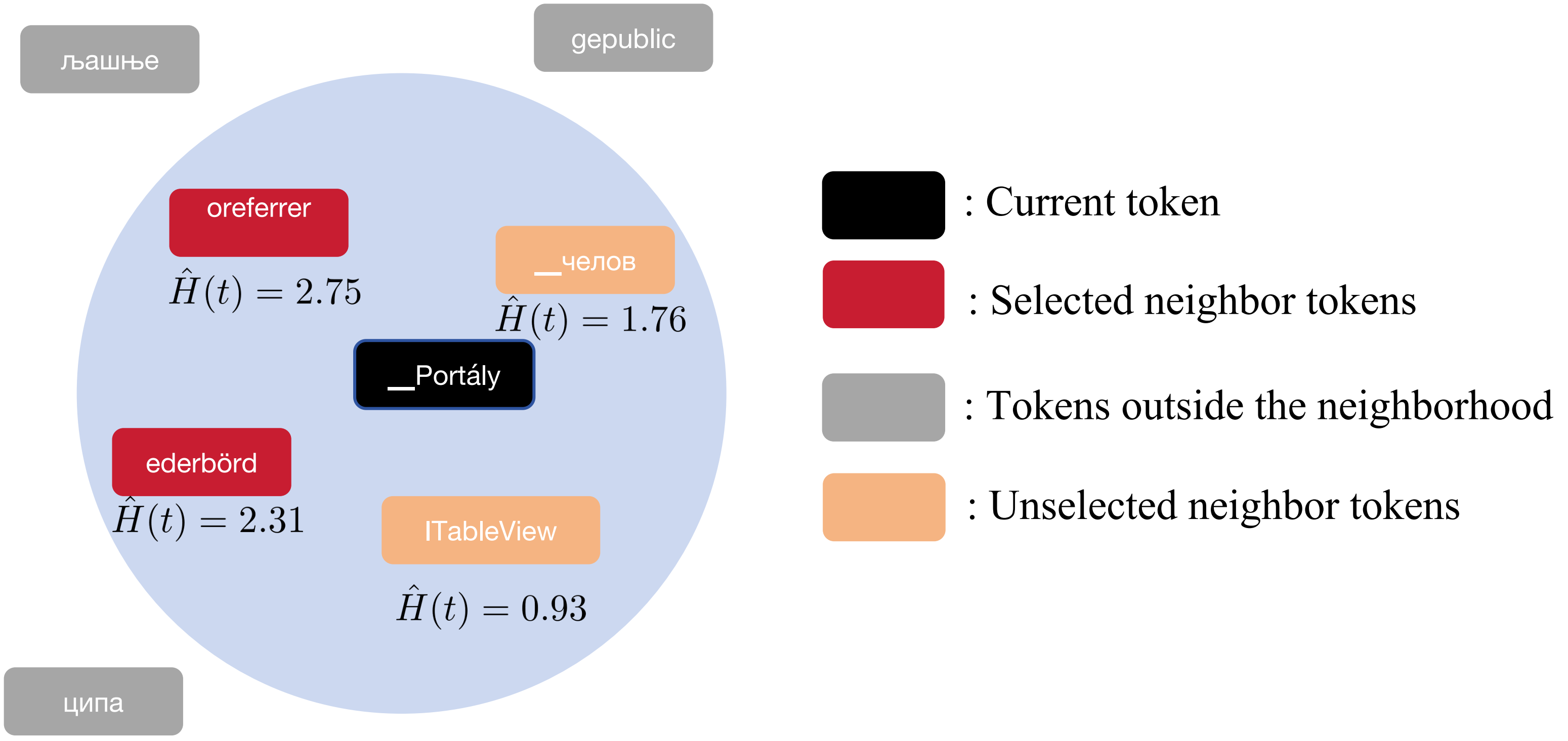
技术框架:GlitchMiner的整体框架包含以下几个主要步骤:1) 初始化:随机初始化一个Token序列作为初始输入。2) 梯度计算:计算当前输入序列对模型预测熵的梯度。3) 局部搜索:利用梯度信息,在离散的Token空间中进行局部搜索,寻找能够提高预测熵的Token。4) 迭代优化:重复梯度计算和局部搜索步骤,直到达到预定的迭代次数或预测熵达到阈值。5) Glitch Token识别:将最终的Token序列作为识别出的Glitch Token。
关键创新:GlitchMiner的关键创新在于其梯度引导的离散优化策略。与传统的基于启发式规则或统计异常的方法不同,GlitchMiner直接优化模型的预测熵,从而能够发现更广泛、更隐蔽的Glitch Token。此外,通过梯度引导的局部搜索,GlitchMiner能够高效地探索离散的Token空间,避免了大规模的采样或穷举搜索,显著提高了检测效率。
关键设计:GlitchMiner的关键设计包括:1) 预测熵的计算:使用模型的softmax输出计算预测熵,作为优化的目标函数。2) 梯度估计:由于Token是离散的,无法直接计算梯度,因此采用Gumbel-Softmax trick等方法来估计梯度。3) 局部搜索策略:设计有效的局部搜索策略,例如基于梯度方向的Token替换或插入,以在离散空间中寻找更优的Token序列。4) 迭代停止条件:设置合理的迭代次数或预测熵阈值,以平衡检测精度和计算成本。
🖼️ 关键图片
📊 实验亮点
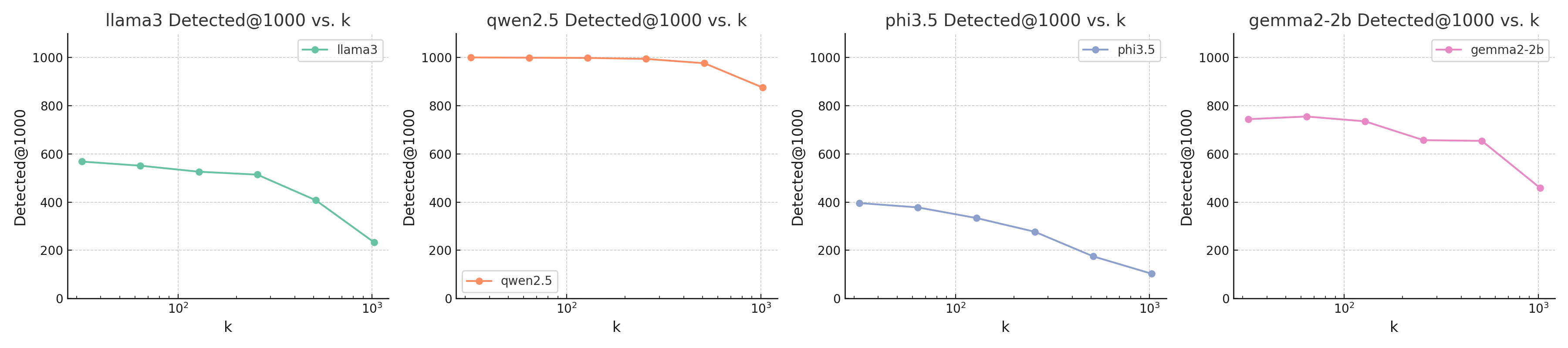
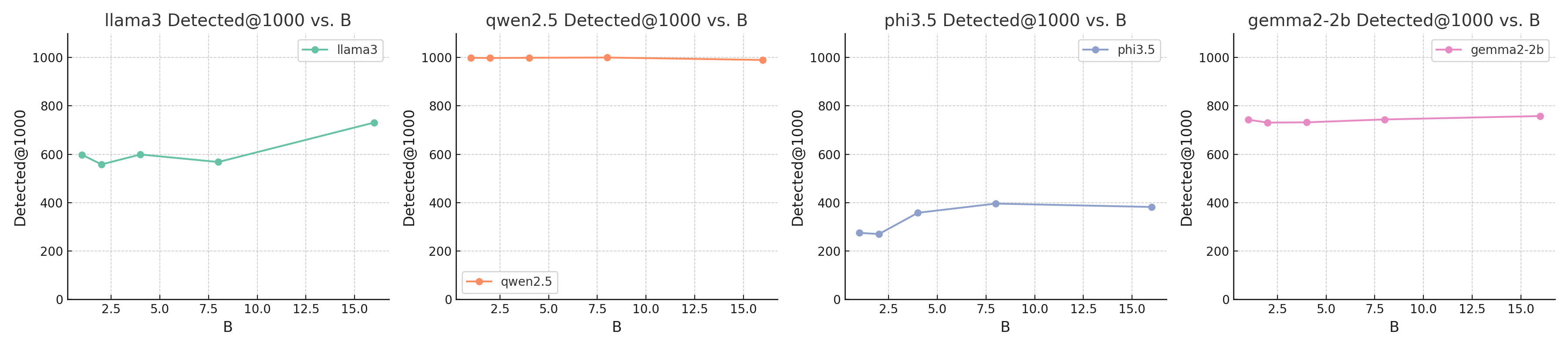
实验结果表明,GlitchMiner在十个不同的LLM上均优于现有方法。例如,在某些模型上,GlitchMiner的检测精度比现有方法提高了20%以上,同时查询效率也显著提升,能够在更短的时间内找到更多的Glitch Token。这些结果验证了GlitchMiner的通用性和有效性。
🎯 应用场景
GlitchMiner可用于评估和提高大语言模型的鲁棒性和安全性。通过识别模型中的Glitch Token,可以帮助开发者发现模型潜在的漏洞和弱点,从而采取相应的防御措施,例如对抗训练或输入过滤。此外,GlitchMiner还可以用于模型的安全审计和合规性检查,确保模型在各种输入条件下都能表现出预期的行为。
📄 摘要(原文)
Glitch tokens, inputs that trigger unpredictable or anomalous behavior in Large Language Models (LLMs), pose significant challenges to model reliability and safety. Existing detection methods primarily rely on heuristic embedding patterns or statistical anomalies within internal representations, limiting their generalizability across different model architectures and potentially missing anomalies that deviate from observed patterns. We introduce GlitchMiner, an behavior-driven framework designed to identify glitch tokens by maximizing predictive entropy. Leveraging a gradient-guided local search strategy, GlitchMiner efficiently explores the discrete token space without relying on model-specific heuristics or large-batch sampling. Extensive experiments across ten LLMs from five major model families demonstrate that GlitchMiner consistently outperforms existing approaches in detection accuracy and query efficiency, providing a generalizable and scalable solution for effective glitch token discovery. Code is available at [https://github.com/wooozihu/GlitchMiner]