Do Large Language Models Truly Grasp Mathematics? An Empirical Exploration From Cognitive Psychology
作者: Wei Xie, Shuoyoucheng Ma, Zhenhua Wang, Enze Wang, Kai Chen, Xiaobing Sun, Baosheng Wang
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-10-19 (更新: 2025-09-20)
备注: Thank you for your attention. This paper was accepted by the CogSci 2025 conference in April and published in August. The location in the proceedings is: https://escholarship.org/uc/item/24x9t7s1
💡 一句话要点
基于认知心理学视角,探究大语言模型数学能力局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学能力 认知心理学 认知反射测试 思维链 模式匹配 推理能力
📋 核心要点
- 现有研究缺乏将LLM数学问题求解与人类认知心理学联系的可解释实验证据。
- 通过修改认知反射测试(CRT)问题,探究LLM是否具备类似人类的数学推理能力。
- 实验表明,即使使用CoT提示,LLM在修改后的CRT问题上准确率显著下降,表明其依赖模式匹配。
📝 摘要(中文)
大型语言模型(LLM)解决数学问题的认知机制仍然是一个备受争议且未解决的问题。目前,几乎没有可解释的实验证据将LLM的问题解决与人类认知心理学联系起来。为了确定LLM是否具有类似人类的数学推理能力,我们修改了人类认知反射测试(CRT)中使用的问题。结果表明,即使使用思维链(CoT)提示,包括最新的o1模型(以其推理能力而闻名)在内的主流LLM在解决这些修改后的CRT问题时也具有很高的错误率。具体而言,平均准确率与原始问题相比下降了高达50%。对LLM不正确答案的进一步分析表明,它们主要依赖于来自其训练数据的模式匹配,这更符合人类的直觉(系统1思维),而不是类似人类的推理(系统2思维)。这一发现挑战了LLM具有与人类相当的真正数学推理能力的观点。因此,这项工作可能会调整对LLM在迈向通用人工智能方面进展的过度乐观的看法。
🔬 方法详解
问题定义:论文旨在探究大型语言模型(LLM)是否真正具备类似人类的数学推理能力。现有方法主要关注LLM在标准数学数据集上的表现,但缺乏从认知心理学角度的深入分析,无法区分LLM是真正理解数学原理,还是仅仅依赖于模式匹配。现有研究无法有效评估LLM是否具备人类的“系统2思维”,即有意识、分析性的推理能力。
核心思路:论文的核心思路是借鉴人类认知心理学中的认知反射测试(CRT),通过修改CRT问题,诱导LLM产生基于直觉(系统1思维)的错误答案,从而判断LLM是否具备克服直觉、进行深入推理(系统2思维)的能力。如果LLM在修改后的CRT问题上表现不佳,则表明其数学能力更多地依赖于模式匹配,而非真正的推理。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择并修改经典的认知反射测试(CRT)问题,使其更适合LLM处理;2) 使用不同的提示策略(包括思维链CoT)引导LLM解决修改后的CRT问题;3) 分析LLM的答案,统计准确率,并深入分析错误答案的类型和原因;4) 将LLM的错误答案与人类的典型错误答案进行对比,从而判断LLM的认知过程是否与人类相似。
关键创新:论文的关键创新在于将认知心理学中的CRT测试引入到LLM的数学能力评估中。通过修改CRT问题,论文能够更有效地诱导LLM产生基于直觉的错误答案,从而区分LLM是真正理解数学原理,还是仅仅依赖于模式匹配。这种方法为评估LLM的认知能力提供了一种新的视角。
关键设计:论文的关键设计包括:1) 对CRT问题的修改,使其既能保留CRT测试的核心思想,又能适应LLM的处理方式;2) 使用思维链(CoT)提示,以提高LLM的推理能力,并观察CoT提示是否能帮助LLM克服直觉偏差;3) 对LLM错误答案的深入分析,包括错误答案的类型、频率以及与人类典型错误答案的对比。
🖼️ 关键图片
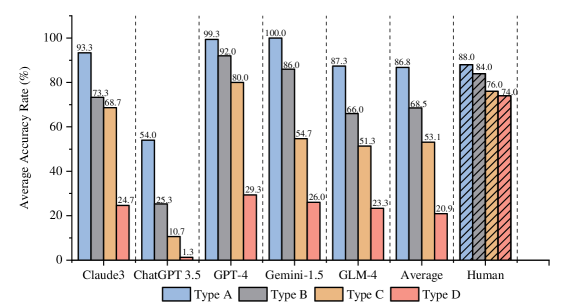


📊 实验亮点
实验结果表明,即使使用思维链(CoT)提示,主流LLM(包括最新的o1模型)在解决修改后的CRT问题时,平均准确率下降高达50%。这表明LLM在数学问题解决中主要依赖于模式匹配,而非类似人类的推理能力。该研究挑战了LLM具备真正数学推理能力的观点。
🎯 应用场景
该研究成果可应用于更准确地评估和理解大型语言模型的数学能力,避免对LLM在通用人工智能方面进展的过度乐观。此外,该研究方法可以推广到评估LLM在其他领域的认知能力,例如常识推理、逻辑推理等,从而促进LLM的可靠性和安全性。
📄 摘要(原文)
The cognitive mechanism by which Large Language Models (LLMs) solve mathematical problems remains a widely debated and unresolved issue. Currently, there is little interpretable experimental evidence that connects LLMs' problem-solving with human cognitive psychology.To determine if LLMs possess human-like mathematical reasoning, we modified the problems used in the human Cognitive Reflection Test (CRT). Our results show that, even with the use of Chains of Thought (CoT) prompts, mainstream LLMs, including the latest o1 model (noted for its reasoning capabilities), have a high error rate when solving these modified CRT problems. Specifically, the average accuracy rate dropped by up to 50% compared to the original questions.Further analysis of LLMs' incorrect answers suggests that they primarily rely on pattern matching from their training data, which aligns more with human intuition (System 1 thinking) rather than with human-like reasoning (System 2 thinking). This finding challenges the belief that LLMs have genuine mathematical reasoning abilities comparable to humans. As a result, this work may adjust overly optimistic views on LLMs' progress towards artificial general intelligence.