Cooperation and Fairness in Multi-Agent Reinforcement Learning
作者: Jasmine Jerry Aloor, Siddharth Nayak, Sydney Dolan, Hamsa Balakrishnan
分类: cs.MA, cs.AI, cs.RO
发布日期: 2024-10-19
备注: Manuscript accepted in ACM Journal on Autonomous Transportation Systems
DOI: 10.1145/3702012
💡 一句话要点
提出基于Min-Max公平目标分配的MARL方法,提升多智能体导航的公平性和效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 公平性 效率 目标分配 导航
📋 核心要点
- 现有MARL方法侧重于系统效率,忽略了智能体间的公平性,导致资源分配不均和个体成本差异。
- 论文提出基于Min-Max公平目标分配的MARL框架,结合公平性奖励,引导智能体学习公平策略。
- 实验表明,该方法在导航和覆盖任务中,显著提升了公平性,同时保持了较高的效率水平。
📝 摘要(中文)
多智能体系统通常被训练以最大化共享成本目标,这通常反映了系统层面的效率。然而,在资源受限的移动和交通系统中,效率的实现可能会以牺牲公平性为代价——某些智能体可能会承担明显更高的成本或更低的回报。任务分配可能不公平,导致一些智能体获得不公平的优势,而另一些智能体则承担过高的成本。考虑效率和公平性之间的权衡非常重要。本文研究了使用多智能体强化学习(MARL)的一组去中心化智能体的公平多智能体导航问题。我们将不同智能体行进距离的变异系数的倒数作为公平性的度量,并研究智能体是否可以在不显著牺牲效率(即不增加总行进距离)的情况下学习公平。我们发现,通过使用最小-最大公平距离目标分配以及激励公平性的奖励项来训练智能体,智能体可以(1)学习公平的目标分配,以及(2)仅使用局部观察即可在导航场景中实现几乎完美的目标覆盖。对于目标覆盖场景,我们发现,平均而言,我们的模型在效率方面比使用随机分配训练的基线提高了14%,在公平性方面提高了5%。此外,与在最优效率分配上训练的模型相比,公平性平均提高了21%;这种公平性的提高是以效率降低7%为代价的。最后,我们将我们的方法扩展到智能体必须以规定的队形完成覆盖任务的环境中,并表明可以在不针对特定队形形状定制模型的情况下做到这一点。
🔬 方法详解
问题定义:论文旨在解决多智能体系统中效率与公平性之间的矛盾。现有MARL方法通常以最大化系统整体效率为目标,忽略了各个智能体之间的公平性,导致某些智能体承担过多的任务或成本,而另一些智能体则获得不公平的优势。这种不公平性在资源受限的环境中尤为突出。
核心思路:论文的核心思路是通过引入公平性指标和相应的奖励机制,引导智能体在学习过程中兼顾效率和公平性。具体而言,论文采用最小-最大公平距离目标分配策略,并设计了一个奖励项来激励智能体朝着公平的方向移动。这样,智能体不仅要完成任务,还要尽可能地保证任务分配的公平性,从而实现整体效率和个体公平的平衡。
技术框架:整体框架包含以下几个主要组成部分:1) 环境建模:定义多智能体导航或覆盖任务的环境,包括智能体的位置、目标位置等信息。2) 目标分配:采用Min-Max公平距离目标分配策略,为每个智能体分配目标。3) 策略学习:使用MARL算法(具体算法未知)训练智能体的策略,使其能够根据局部观察选择合适的动作。4) 奖励函数设计:设计包含效率奖励和公平性奖励的综合奖励函数,引导智能体学习公平高效的策略。5) 评估指标:使用效率指标(如总行进距离)和公平性指标(如行进距离的变异系数的倒数)来评估算法的性能。
关键创新:论文的关键创新在于将公平性显式地纳入MARL的训练过程中。传统的MARL方法通常只关注系统整体的效率,而忽略了智能体之间的公平性。论文通过引入Min-Max公平距离目标分配策略和公平性奖励,使得智能体能够在学习过程中主动地考虑公平性,从而实现更公平的任务分配和资源利用。
关键设计:论文的关键设计包括:1) Min-Max公平距离目标分配策略:该策略旨在最小化智能体之间行进距离的最大差异,从而保证任务分配的公平性。具体实现方式未知。2) 公平性奖励:该奖励项旨在激励智能体朝着公平的方向移动。具体形式未知,但可能与智能体之间的行进距离差异有关。3) 综合奖励函数:该函数将效率奖励和公平性奖励结合起来,通过调整两者的权重来控制效率和公平性之间的权衡。
🖼️ 关键图片

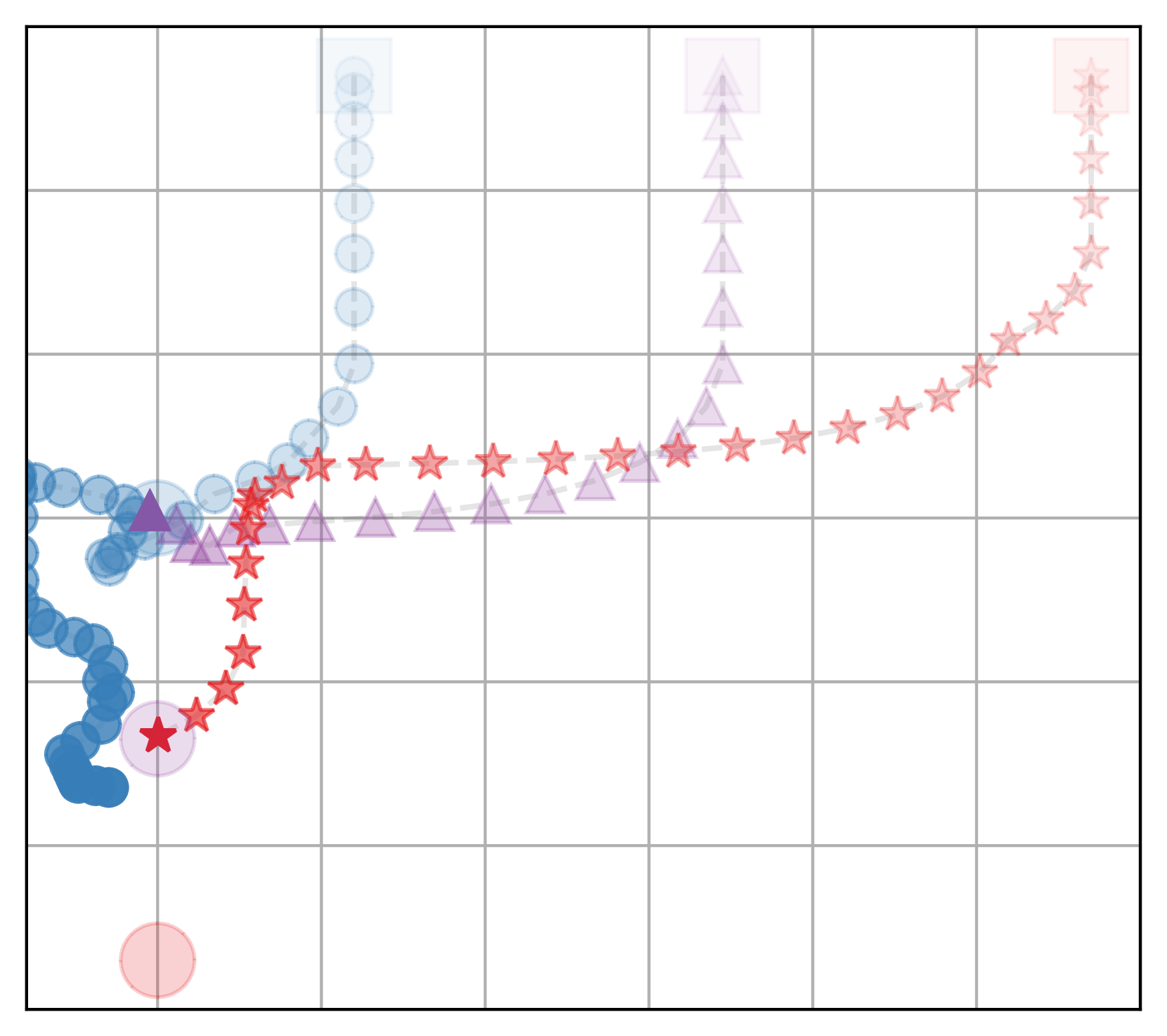
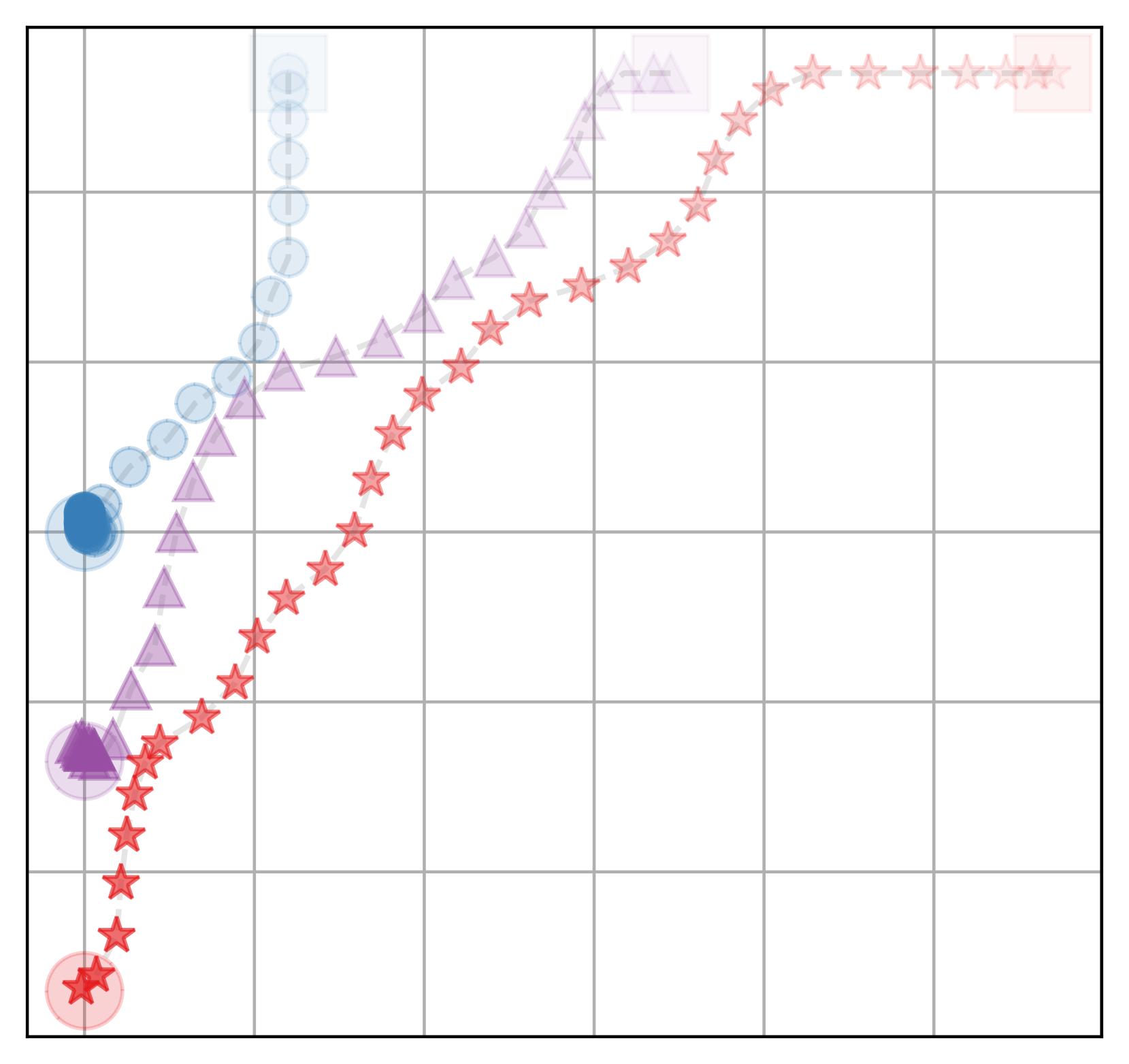
📊 实验亮点
实验结果表明,与随机分配策略相比,该方法在效率上平均提升了14%,在公平性上平均提升了5%。与最优效率分配策略相比,该方法在公平性上平均提升了21%,而效率仅下降了7%。这些数据表明,该方法能够在显著提升公平性的同时,保持较高的效率水平,实现了效率与公平性的有效平衡。
🎯 应用场景
该研究成果可应用于各种多智能体协作场景,如自动驾驶车辆调度、无人机协同搜索、机器人仓库管理等。通过提升任务分配的公平性,可以避免资源过度集中于某些智能体,提高系统的整体鲁棒性和可持续性。此外,该方法还有助于构建更公平、更和谐的人工智能系统,提升用户体验和社会福祉。
📄 摘要(原文)
Multi-agent systems are trained to maximize shared cost objectives, which typically reflect system-level efficiency. However, in the resource-constrained environments of mobility and transportation systems, efficiency may be achieved at the expense of fairness -- certain agents may incur significantly greater costs or lower rewards compared to others. Tasks could be distributed inequitably, leading to some agents receiving an unfair advantage while others incur disproportionately high costs. It is important to consider the tradeoffs between efficiency and fairness. We consider the problem of fair multi-agent navigation for a group of decentralized agents using multi-agent reinforcement learning (MARL). We consider the reciprocal of the coefficient of variation of the distances traveled by different agents as a measure of fairness and investigate whether agents can learn to be fair without significantly sacrificing efficiency (i.e., increasing the total distance traveled). We find that by training agents using min-max fair distance goal assignments along with a reward term that incentivizes fairness as they move towards their goals, the agents (1) learn a fair assignment of goals and (2) achieve almost perfect goal coverage in navigation scenarios using only local observations. For goal coverage scenarios, we find that, on average, our model yields a 14% improvement in efficiency and a 5% improvement in fairness over a baseline trained using random assignments. Furthermore, an average of 21% improvement in fairness can be achieved compared to a model trained on optimally efficient assignments; this increase in fairness comes at the expense of only a 7% decrease in efficiency. Finally, we extend our method to environments in which agents must complete coverage tasks in prescribed formations and show that it is possible to do so without tailoring the models to specific formation shapes.