Step Guided Reasoning: Improving Mathematical Reasoning using Guidance Generation and Step Reasoning
作者: Lang Cao, Yingtian Zou, Chao Peng, Renhong Chen, Wu Ning, Yitong Li
分类: cs.AI, cs.CL, cs.HC
发布日期: 2024-10-18 (更新: 2025-09-21)
备注: 9 pages, 9 figures
💡 一句话要点
提出Step Guided Reasoning,提升通用LLM在数学推理上的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 大型语言模型 逐步推理 无训练学习 指导生成
📋 核心要点
- 现有LLM在数学推理上表现不足,CoT方法虽有提升,但依赖大量数据或牺牲精度。
- Step Guided Reasoning通过引导LLM反思推理步骤,提升其数学推理能力,无需额外训练。
- 实验表明,该方法显著提升了Qwen2系列模型在数学任务上的性能,甚至超越专用数学模型。
📝 摘要(中文)
大型语言模型(LLMs)在数学推理方面面临挑战,而逐步推理(Chain-of-Thought, CoT)的引入显著提升了LLMs的数学能力。然而,当前方法要么需要大量的推理数据集进行训练,要么依赖于少样本方法,这通常会牺牲计算精度。为了解决这些根本限制,我们提出了一种新颖的无训练自适应框架Step Guided Reasoning,该框架能够有效地增强通用预训练语言模型的数学推理能力。在这种方法中,LLMs反思小的推理步骤,类似于人类深思熟虑并专注于下一步该做什么。通过将这种反思过程纳入推理阶段,LLMs可以有效地引导其推理从一个步骤到下一个步骤。通过广泛的实验,我们证明了Step Guided Reasoning在增强最先进语言模型的数学性能方面的显著效果——Qwen2-72B-Instruct在MMLU-STEM上的表现优于其数学专用版本Qwen2.5-72B-Math-Instruct,得分分别为90.9%和87.3%。Qwen2-7B-Instruct和Qwen2-72B-Instruct在数学领域的平均得分分别从27.1%提高到36.3%,以及从36.5%提高到47.4%。
🔬 方法详解
问题定义:论文旨在解决通用预训练语言模型在数学推理任务中表现不佳的问题。现有方法,如微调或少样本学习,要么需要大量标注数据,成本高昂,要么精度不足,无法满足实际需求。因此,如何提升通用LLM的数学推理能力,同时避免大量训练数据和精度损失,是本文要解决的核心问题。
核心思路:论文的核心思路是模仿人类解决数学问题时的逐步思考过程,将复杂的推理过程分解为一系列小的、可控的步骤。通过引导LLM在每一步进行反思,明确下一步的目标和方法,从而提高推理的准确性和效率。这种方法类似于CoT,但更加强调对每一步骤的引导和反思,而非简单地生成步骤。
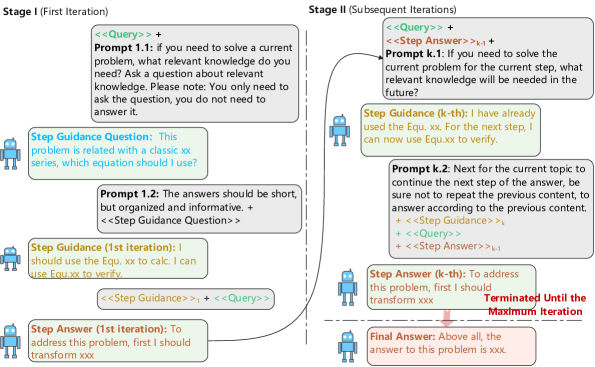
技术框架:Step Guided Reasoning框架主要包含两个阶段:指导生成阶段和逐步推理阶段。在指导生成阶段,LLM首先接收数学问题,然后生成一个简短的指导性语句,明确下一步推理的目标。在逐步推理阶段,LLM根据指导性语句进行推理,生成当前步骤的答案,并更新问题状态。这两个阶段交替进行,直到问题得到解决。整个过程无需额外的训练数据,可以直接应用于预训练的LLM。
关键创新:该方法最重要的创新在于引入了“指导”的概念,通过让LLM在每一步推理前生成指导性语句,明确推理目标,从而避免了推理过程中的盲目性和随机性。与传统的CoT方法相比,Step Guided Reasoning更加注重对推理过程的控制和引导,从而提高了推理的准确性和效率。此外,该方法是训练无关的,可以直接应用于各种预训练的LLM,具有很强的通用性和可扩展性。
关键设计:指导性语句的生成是该方法的一个关键设计。论文中没有明确说明如何生成指导性语句,这部分可能依赖于prompt工程。另外,如何判断问题是否已经解决,以及如何处理推理过程中的错误,也是需要考虑的关键设计。具体的参数设置、损失函数、网络结构等技术细节在论文中没有详细描述,可能使用了预训练模型的默认设置。
🖼️ 关键图片
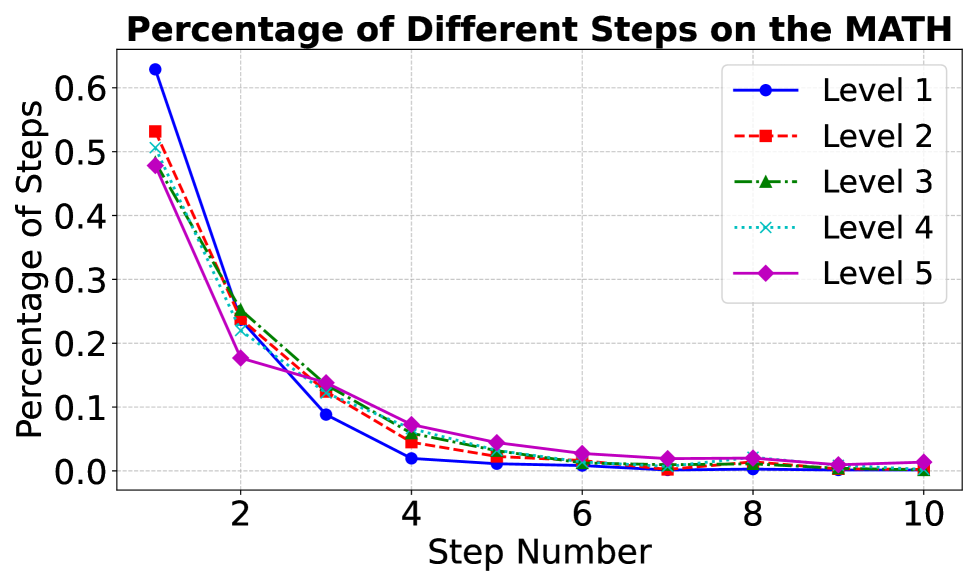

📊 实验亮点
实验结果表明,Step Guided Reasoning能够显著提升LLM在数学任务上的性能。例如,Qwen2-72B-Instruct在MMLU-STEM上的得分从原始的87.3%提升到90.9%,甚至超过了专门为数学任务设计的Qwen2.5-72B-Math-Instruct。此外,Qwen2-7B-Instruct和Qwen2-72B-Instruct在数学领域的平均得分分别提升了9.2%和10.9%。这些结果表明,Step Guided Reasoning是一种有效的提升LLM数学推理能力的方法。
🎯 应用场景
Step Guided Reasoning具有广泛的应用前景,可应用于数学教育、科学研究、金融分析等领域。通过提升LLM的数学推理能力,可以辅助学生学习数学知识,帮助科研人员解决复杂的数学问题,以及为金融分析师提供更准确的决策支持。该方法还可以扩展到其他需要复杂推理的任务中,例如代码生成、逻辑推理等。
📄 摘要(原文)
Mathematical reasoning has been challenging for large language models (LLMs), and the introduction of step-by-step Chain-of-Thought (CoT) inference has significantly advanced the mathematical capabilities of LLMs. However, current approaches either necessitate extensive inference datasets for training or depend on few-shot methods that frequently compromise computational accuracy. To address these fundamental limitations, we propose Step Guided Reasoning, a novel training-free adaptation framework that efficiently equips general-purpose pre-trained language models with enhanced mathematical reasoning capabilities. In this approach, LLMs reflect on small reasoning steps, similar to how humans deliberate and focus attention on what to do next. By incorporating this reflective process into the inference stage, LLMs can effectively guide their reasoning from one step to the next. Through extensive experiments, we demonstrate the significant effect of Step Guided Reasoning in enhancing mathematical performance in state-of-the-art language models -- Qwen2-72B-Instruct outperforms its math-specific counterpart, Qwen2.5-72B-Math-Instruct, on MMLU-STEM with a score of 90.9%, compared to 87.3%. The average scores of Qwen2-7B-Instruct and Qwen2-72B-Instruct increase from 27.1% to 36. 3% and from 36. 5% to 47.4% in the math domain, respectively.