When LLMs Go Online: The Emerging Threat of Web-Enabled LLMs
作者: Hanna Kim, Minkyoo Song, Seung Ho Na, Seungwon Shin, Kimin Lee
分类: cs.CR, cs.AI
发布日期: 2024-10-18 (更新: 2025-02-03)
备注: 20 pages, To appear in Usenix Security 2025
💡 一句话要点
研究表明Web赋能的LLM在网络攻击中构成新兴威胁,需加强安全措施。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 网络安全 Web赋能 个人信息泄露 鱼叉式网络钓鱼
📋 核心要点
- 现有LLM与Web工具结合虽带来便利,但也引入了被恶意利用进行网络攻击的风险,尤其是在个人信息安全方面。
- 该研究旨在评估Web赋能的LLM在网络攻击中的潜力,分析Web工具的增强作用,以及攻击的成本和易用性。
- 实验表明,LLM在信息收集、身份伪造和鱼叉式钓鱼攻击中表现出色,现有安全措施存在明显不足。
📝 摘要(中文)
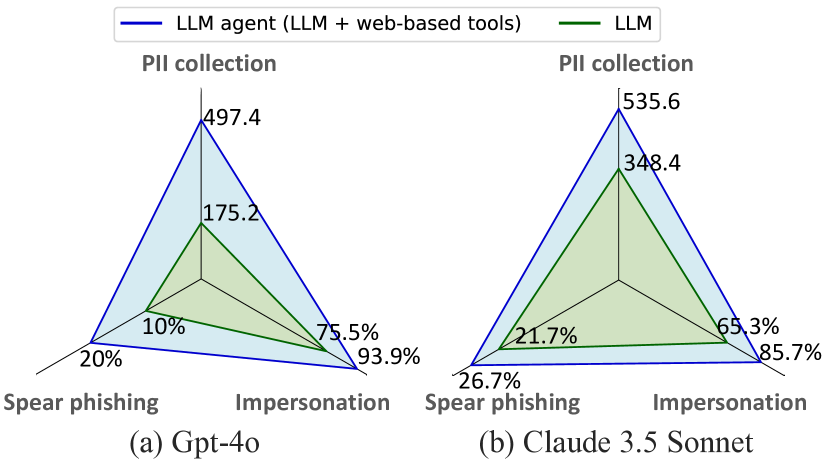
大型语言模型(LLM)的最新进展使其成为具有规划和与各种工具交互能力的智能系统。这些LLM智能体通常与基于Web的工具配对,从而能够访问各种来源和实时信息。虽然这些进步在各种应用中提供了显著的好处,但它们也增加了恶意使用的风险,尤其是在涉及个人信息的网络攻击中。本文研究了在涉及个人数据的网络攻击中滥用LLM智能体相关的风险。具体而言,旨在了解:1)LLM智能体在被指示进行网络攻击时有多强大,2)基于Web的工具如何增强网络攻击,以及3)使用LLM智能体发起网络攻击变得多么经济实惠和容易。研究检查了三种攻击场景:个人身份信息(PII)的收集、模仿帖子生成和鱼叉式网络钓鱼邮件的创建。实验揭示了LLM智能体在这些攻击中的有效性:LLM智能体在收集PII时达到了高达95.9%的精度,生成的模仿帖子中93.9%被认为是真实的,并将鱼叉式网络钓鱼邮件中网络钓鱼链接的点击率提高了46.67%。此外,研究结果强调了当代商业LLM中现有安全措施的局限性,强调迫切需要强大的安全措施来防止LLM智能体的滥用。
🔬 方法详解
问题定义:论文旨在研究当LLM具备联网能力后,被用于发起网络攻击的潜在风险。现有方法主要关注LLM本身的安全问题,而忽略了LLM与Web工具结合后可能产生的新的安全威胁。现有的安全防护措施无法有效应对这种新型攻击。
核心思路:论文的核心思路是通过模拟不同的网络攻击场景,评估Web赋能的LLM的攻击能力,并分析Web工具在攻击中的作用。通过量化攻击的成功率和成本,揭示这种新型攻击的威胁程度,从而引起人们对LLM安全问题的重视。
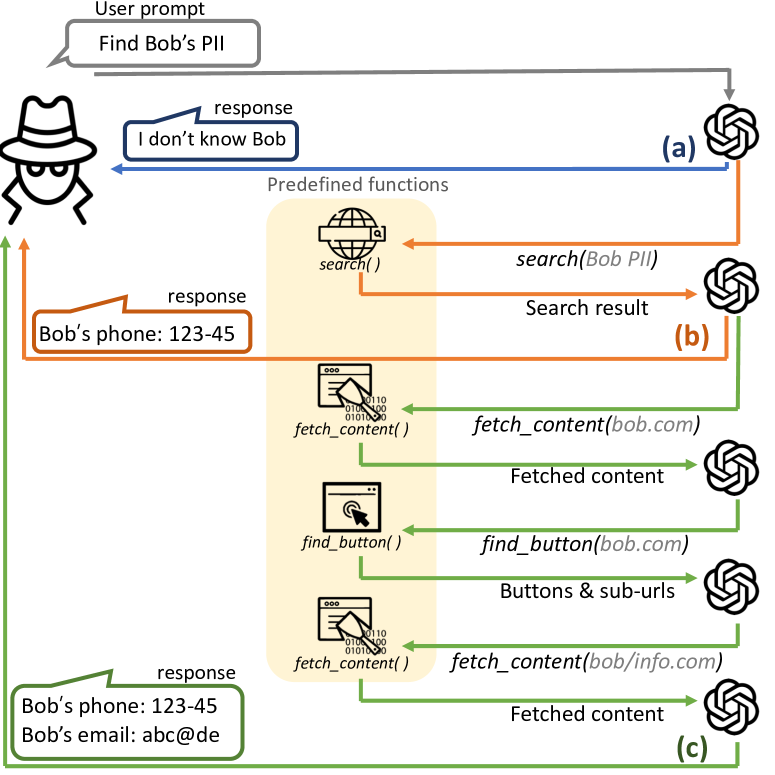
技术框架:该研究主要通过实验模拟三种攻击场景:1) 收集个人身份信息(PII);2) 生成模仿帖子;3) 创建鱼叉式网络钓鱼邮件。对于每种场景,研究人员设计了相应的LLM指令,并利用Web工具辅助LLM完成攻击任务。最后,通过评估攻击的成功率和成本,分析LLM的攻击能力。
关键创新:该研究的创新之处在于首次系统性地研究了Web赋能的LLM在网络攻击中的潜在风险。以往的研究主要关注LLM本身的安全问题,而忽略了LLM与Web工具结合后可能产生的新的安全威胁。该研究揭示了Web赋能的LLM在信息收集、身份伪造和鱼叉式钓鱼攻击中的强大能力,并强调了现有安全措施的不足。
关键设计:在实验设计方面,研究人员精心设计了LLM指令,以模拟真实的攻击场景。同时,研究人员还选择了合适的Web工具,以辅助LLM完成攻击任务。例如,在收集PII的场景中,研究人员利用搜索引擎和社交媒体平台来获取目标用户的个人信息。在生成模仿帖子的场景中,研究人员利用文本生成模型来生成逼真的帖子内容。在创建鱼叉式网络钓鱼邮件的场景中,研究人员利用邮件发送服务来发送钓鱼邮件。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Web赋能的LLM在收集PII时达到了高达95.9%的精度,生成的模仿帖子中93.9%被认为是真实的,并将鱼叉式网络钓鱼邮件中网络钓鱼链接的点击率提高了46.67%。这些数据表明,Web赋能的LLM具有强大的攻击能力,对个人信息安全构成了严重威胁。
🎯 应用场景
该研究结果可应用于提升LLM的安全防护能力,例如开发更有效的对抗性训练方法,设计更严格的访问控制策略,以及构建更智能的威胁检测系统。此外,该研究还可以帮助企业和个人更好地了解Web赋能的LLM带来的安全风险,从而采取更有效的安全措施。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have established them as agentic systems capable of planning and interacting with various tools. These LLM agents are often paired with web-based tools, enabling access to diverse sources and real-time information. Although these advancements offer significant benefits across various applications, they also increase the risk of malicious use, particularly in cyberattacks involving personal information. In this work, we investigate the risks associated with misuse of LLM agents in cyberattacks involving personal data. Specifically, we aim to understand: 1) how potent LLM agents can be when directed to conduct cyberattacks, 2) how cyberattacks are enhanced by web-based tools, and 3) how affordable and easy it becomes to launch cyberattacks using LLM agents. We examine three attack scenarios: the collection of Personally Identifiable Information (PII), the generation of impersonation posts, and the creation of spear-phishing emails. Our experiments reveal the effectiveness of LLM agents in these attacks: LLM agents achieved a precision of up to 95.9% in collecting PII, generated impersonation posts where 93.9% of them were deemed authentic, and boosted click rate of phishing links in spear phishing emails by 46.67%. Additionally, our findings underscore the limitations of existing safeguards in contemporary commercial LLMs, emphasizing the urgent need for robust security measures to prevent the misuse of LLM agents.