FIRE: Fact-checking with Iterative Retrieval and Verification
作者: Zhuohan Xie, Rui Xing, Yuxia Wang, Jiahui Geng, Hasan Iqbal, Dhruv Sahnan, Iryna Gurevych, Preslav Nakov
分类: cs.IR, cs.AI, cs.CL, cs.LG
发布日期: 2024-10-17 (更新: 2025-02-12)
备注: 4 figures, 8 tables, accepted to Findings of NAACL
🔗 代码/项目: GITHUB
💡 一句话要点
提出FIRE框架,通过迭代检索与验证进行高效的事实核查。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 迭代检索 声明验证 置信度 大语言模型 知识库 自然语言处理
📋 核心要点
- 现有事实核查方法依赖固定数量的证据检索,未能充分利用验证模型的内部知识和人类迭代推理过程。
- FIRE框架通过迭代地整合证据检索和声明验证,基于置信度动态决定提供答案或生成新的搜索查询。
- 实验表明,FIRE在性能略微提升的同时,显著降低了大语言模型和搜索成本,具有大规模应用潜力。
📝 摘要(中文)
长文本的事实核查具有挑战性,通常的做法是将其分解为多个原子声明。针对这些原子声明的事实核查,典型方法是检索固定数量的证据,然后进行验证。然而,这种方法通常效率不高,因为它未能充分利用验证模型对声明的内部知识,并且无法复现人类搜索策略中的迭代推理过程。为了解决这些局限性,我们提出了FIRE,一种新颖的基于代理的框架,以迭代方式整合证据检索和声明验证。具体来说,FIRE采用统一的机制来决定是提供最终答案还是生成后续搜索查询,这取决于其对当前判断的置信度。我们比较了FIRE与其他强大的事实核查框架,发现它在略微提高性能的同时,平均降低了7.6倍的大语言模型(LLM)成本和16.5倍的搜索成本。这些结果表明,FIRE在大型事实核查操作中具有应用前景。我们的代码可在https://github.com/mbzuai-nlp/fire.git获取。
🔬 方法详解
问题定义:论文旨在解决长文本事实核查中,现有方法效率不高的问题。现有方法通常先检索固定数量的证据,再进行验证,未能充分利用验证模型的内部知识,也缺乏人类迭代搜索的灵活性。这种固定模式导致资源浪费,且可能错过关键证据。
核心思路:FIRE的核心思路是模仿人类专家进行事实核查时的迭代过程。它不是一次性检索所有证据,而是根据当前已检索到的证据和验证模型的置信度,决定是给出最终判断,还是继续检索更多相关证据。这种迭代式的方法能够更有效地利用资源,并提高事实核查的准确性。
技术框架:FIRE框架包含两个主要模块:证据检索模块和声明验证模块。这两个模块在一个循环中迭代运行。首先,证据检索模块根据当前声明生成搜索查询,并从外部知识库中检索相关证据。然后,声明验证模块利用检索到的证据对声明进行验证,并输出一个置信度分数。基于该置信度分数,FIRE决定是输出最终结果(已验证/未验证),还是生成新的搜索查询,以检索更多证据。
关键创新:FIRE的关键创新在于其迭代检索和验证的框架,以及基于置信度的决策机制。与传统的固定检索方法不同,FIRE能够根据验证模型的置信度动态调整检索策略,从而更有效地利用资源,并提高事实核查的准确性。此外,FIRE采用统一的机制来决定是否提供最终答案或生成后续搜索查询,简化了整体流程。
关键设计:FIRE框架的关键设计包括:1) 如何生成有效的搜索查询,以检索到相关证据;2) 如何设计声明验证模型,以准确评估声明的真实性;3) 如何设定置信度阈值,以决定何时停止迭代检索并给出最终判断。论文中可能使用了特定的预训练语言模型作为验证模型,并可能采用了特定的损失函数来训练该模型。具体的参数设置和网络结构细节需要在论文中查找。
🖼️ 关键图片

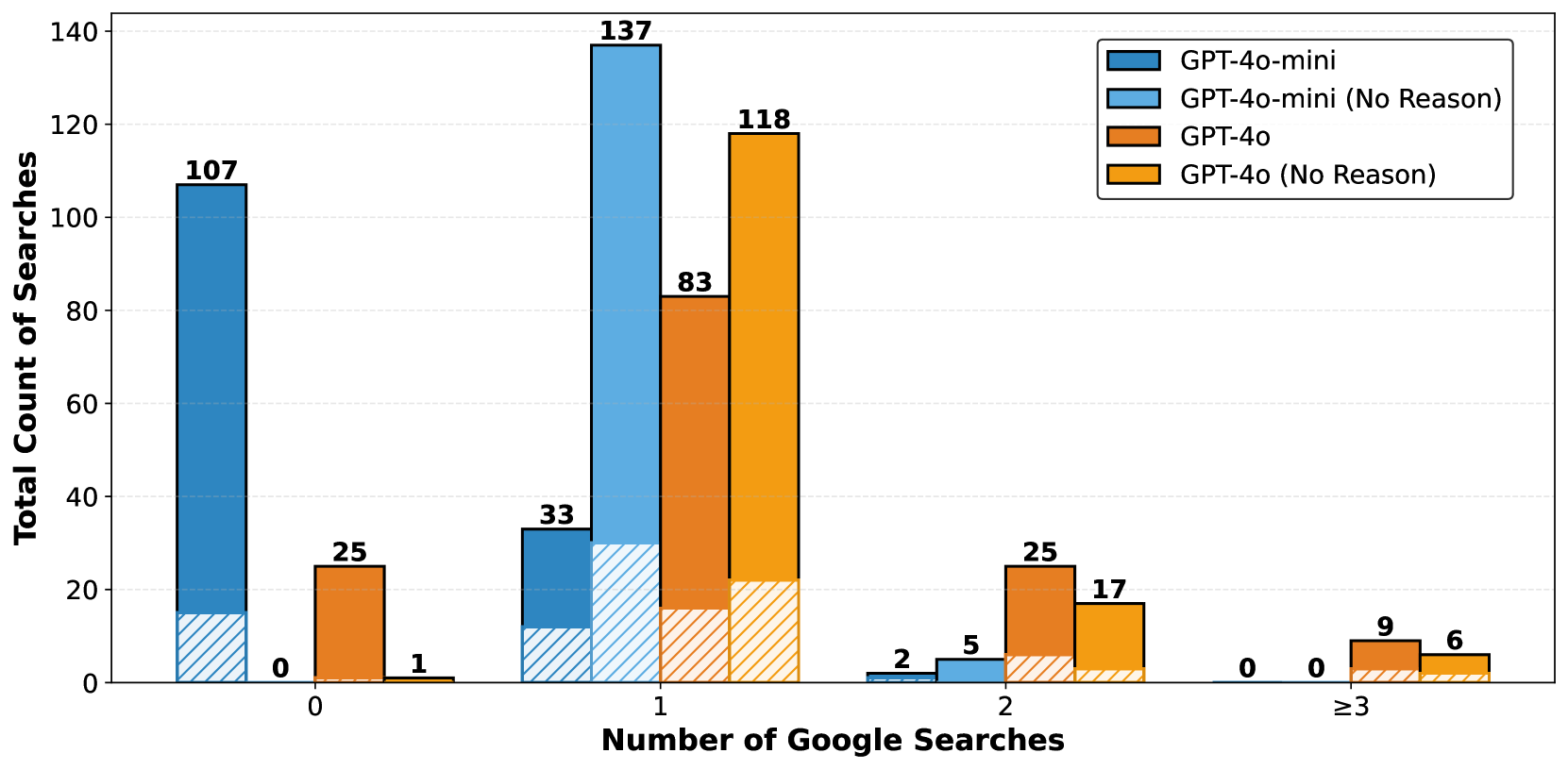
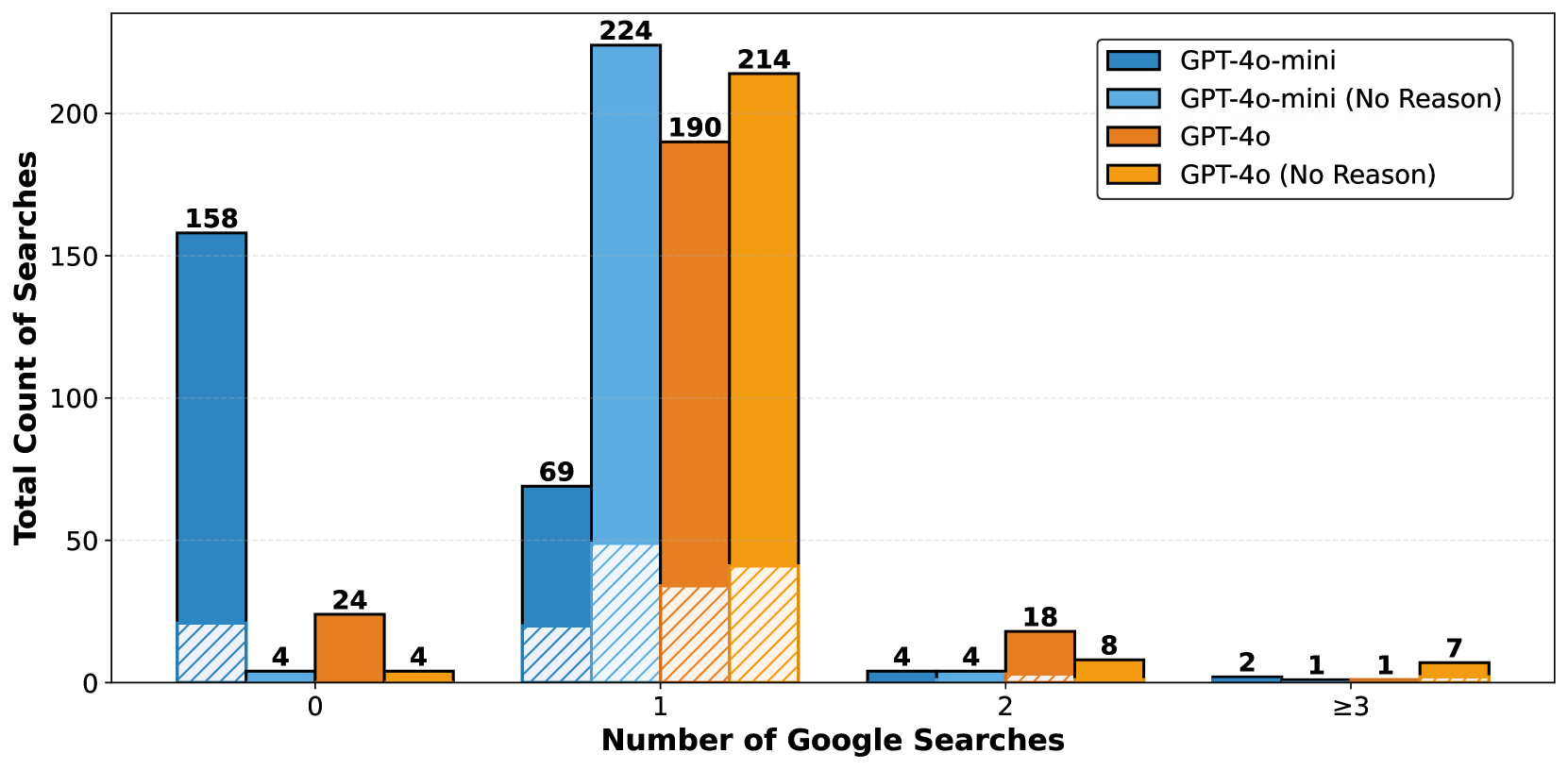
📊 实验亮点
实验结果表明,FIRE框架在事实核查任务上取得了与现有方法相当的性能,同时显著降低了大语言模型(LLM)成本和搜索成本,分别降低了平均7.6倍和16.5倍。这表明FIRE在保证性能的同时,能够更有效地利用计算资源,具有很高的实用价值。
🎯 应用场景
FIRE框架可应用于各种需要事实核查的场景,例如新闻报道验证、社交媒体内容审核、学术论文审查等。该研究的实际价值在于提高事实核查的效率和准确性,降低人工成本,并有助于构建更值得信赖的信息环境。未来,FIRE可以进一步扩展到处理多语言、多模态的事实核查任务。
📄 摘要(原文)
Fact-checking long-form text is challenging, and it is therefore common practice to break it down into multiple atomic claims. The typical approach to fact-checking these atomic claims involves retrieving a fixed number of pieces of evidence, followed by a verification step. However, this method is usually not cost-effective, as it underutilizes the verification model's internal knowledge of the claim and fails to replicate the iterative reasoning process in human search strategies. To address these limitations, we propose FIRE, a novel agent-based framework that integrates evidence retrieval and claim verification in an iterative manner. Specifically, FIRE employs a unified mechanism to decide whether to provide a final answer or generate a subsequent search query, based on its confidence in the current judgment. We compare FIRE with other strong fact-checking frameworks and find that it achieves slightly better performance while reducing large language model (LLM) costs by an average of 7.6 times and search costs by 16.5 times. These results indicate that FIRE holds promise for application in large-scale fact-checking operations. Our code is available at https://github.com/mbzuai-nlp/fire.git.