ETF: An Entity Tracing Framework for Hallucination Detection in Code Summaries
作者: Kishan Maharaj, Vitobha Munigala, Srikanth G. Tamilselvam, Prince Kumar, Sayandeep Sen, Palani Kodeswaran, Abhijit Mishra, Pushpak Bhattacharyya
分类: cs.SE, cs.AI, cs.CL
发布日期: 2024-10-17 (更新: 2025-09-06)
备注: Accepted in ACL 2025 Main, 14 pages, 3 Figures, 5 Tables
💡 一句话要点
提出实体追踪框架ETF,用于检测代码摘要中的幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码摘要 幻觉检测 实体追踪 静态程序分析 大型语言模型
📋 核心要点
- 大型语言模型在代码摘要生成中表现出色,但容易产生幻觉,导致生成的摘要不准确或不完整。
- 实体追踪框架(ETF)通过静态程序分析识别代码实体,并利用LLM验证这些实体在摘要中的一致性,从而检测幻觉。
- 在CodeSumEval数据集上的实验表明,ETF能够有效检测代码摘要中的幻觉,F1得分达到73%,显著提升了幻觉检测的性能。
📝 摘要(中文)
大型语言模型(LLMs)在理解自然语言和代码方面的能力显著提升,推动了其在自然语言到代码(NL2Code)和代码摘要等任务中的应用。然而,LLMs容易产生幻觉,即输出偏离预期含义。由于编程语言和自然语言之间复杂的相互作用,检测代码摘要中的幻觉尤其困难。本文提出了首个专门用于代码摘要幻觉检测的数据集CodeSumEval,包含约1万个样本。此外,本文还提出了一种新颖的实体追踪框架(ETF),该框架a)利用静态程序分析从程序中识别代码实体,b)使用LLMs来映射和验证这些实体及其在生成的代码摘要中的意图。实验分析表明,该框架是有效的,F1得分达到73%。该方法通过追踪摘要到代码的实体来检测幻觉,从而评估摘要的准确性并在摘要中定位错误。
🔬 方法详解
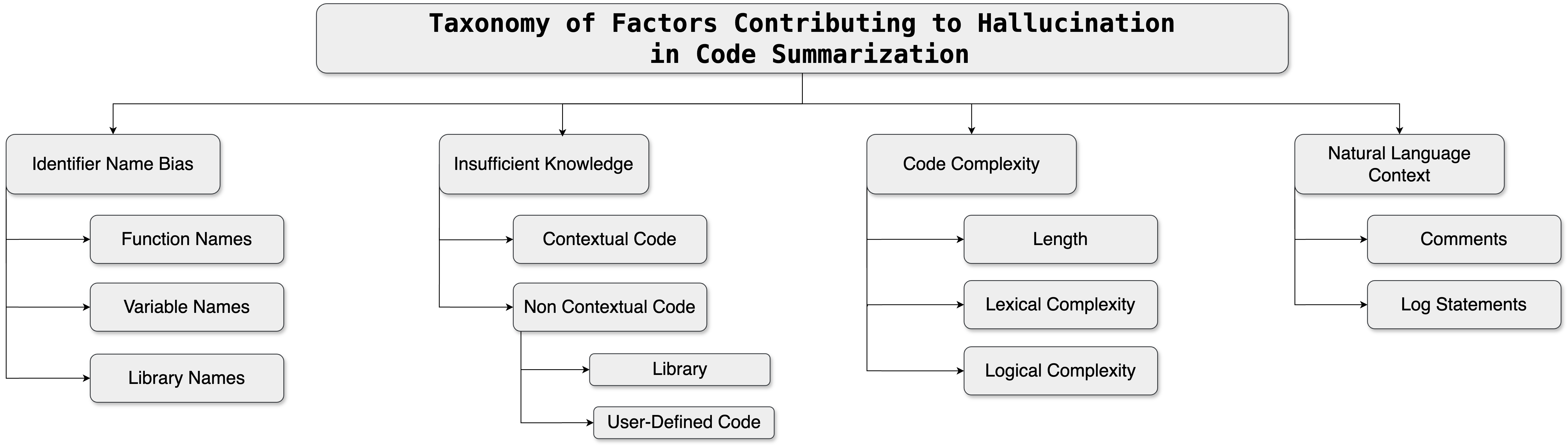
问题定义:代码摘要生成任务旨在根据给定的代码片段生成自然语言描述。然而,现有的代码摘要生成模型,特别是基于大型语言模型的模型,容易产生幻觉,即生成的摘要包含与代码不一致或不相关的实体或信息。检测这些幻觉是一项具有挑战性的任务,因为需要理解代码的语义并将其与生成的摘要进行比较。
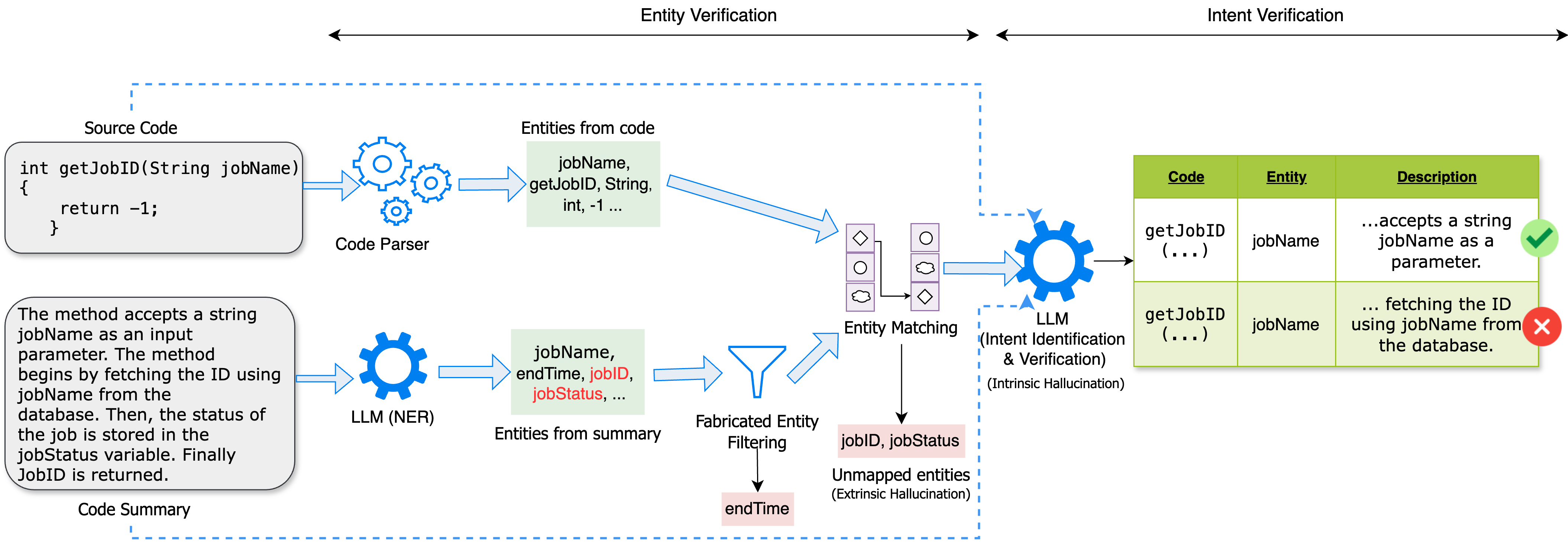
核心思路:本文的核心思路是通过追踪代码中的实体及其在摘要中的对应关系来检测幻觉。具体来说,该方法首先从代码中提取关键实体,然后检查这些实体是否在摘要中正确地表示,并且其意图是否与代码一致。如果摘要中缺少某个实体,或者实体的信息与代码不一致,则认为存在幻觉。
技术框架:实体追踪框架(ETF)包含两个主要模块:实体识别模块和实体验证模块。实体识别模块使用静态程序分析技术从代码中提取关键实体,例如变量、函数和类。实体验证模块使用大型语言模型来映射和验证这些实体及其在生成的代码摘要中的意图。该模块首先将代码实体和摘要输入到LLM中,然后LLM会判断摘要中是否正确地表示了该实体及其意图。
关键创新:该方法的主要创新在于提出了一种基于实体追踪的幻觉检测方法。与现有的方法相比,该方法能够更准确地检测代码摘要中的幻觉,因为它能够直接追踪代码中的实体及其在摘要中的对应关系。此外,该方法还提出了一个新的数据集CodeSumEval,专门用于代码摘要幻觉检测。
关键设计:实体识别模块使用了静态程序分析工具来提取代码实体。实体验证模块使用了预训练的大型语言模型,例如T5或BART。该模块使用prompt engineering技术来指导LLM进行实体验证。具体的prompt包含代码实体、摘要和验证任务的描述。LLM的输出是一个二元标签,表示摘要中是否正确地表示了该实体及其意图。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的实体追踪框架(ETF)在CodeSumEval数据集上取得了显著的性能提升,F1得分达到73%。与现有的基线方法相比,ETF能够更准确地检测代码摘要中的幻觉。此外,实验还表明,ETF能够有效地定位摘要中的错误。
🎯 应用场景
该研究成果可应用于代码生成、代码理解、软件测试等领域。通过检测代码摘要中的幻觉,可以提高代码摘要的质量和可靠性,帮助开发人员更好地理解代码,减少软件缺陷。此外,该方法还可以用于评估代码生成模型的性能,并指导模型的改进。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have significantly enhanced their ability to understand both natural language and code, driving their use in tasks like natural language-to-code (NL2Code) and code summarisation. However, LLMs are prone to hallucination, outputs that stray from intended meanings. Detecting hallucinations in code summarisation is especially difficult due to the complex interplay between programming and natural languages. We introduce a first-of-its-kind dataset, CodeSumEval, with ~10K samples, curated specifically for hallucination detection in code summarisation. We further propose a novel Entity Tracing Framework (ETF) that a) utilises static program analysis to identify code entities from the program and b) uses LLMs to map and verify these entities and their intents within generated code summaries. Our experimental analysis demonstrates the framework's effectiveness, leading to a 73% F1 score. The proposed approach provides a method for detecting hallucinations by tracing entities from the summary to the code, allowing us to evaluate summary accuracy and localise the error within the summary.