AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents
作者: Ke Yang, Yao Liu, Sapana Chaudhary, Rasool Fakoor, Pratik Chaudhari, George Karypis, Huzefa Rangwala
分类: cs.AI, cs.CL
发布日期: 2024-10-17 (更新: 2025-05-24)
💡 一句话要点
AgentOccam:通过优化观察和动作空间,显著提升LLM驱动的Web Agent性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Web Agent 大型语言模型 观察空间 动作空间 零样本学习 自动化Web任务 WebArena
📋 核心要点
- 现有Web Agent研究过度依赖手工设计的策略和上下文示例,缺乏在真实场景中的泛化能力。
- AgentOccam通过优化LLM驱动的Web Agent的观察和动作空间,使其与LLM的预训练数据更好地对齐。
- 实验表明,AgentOccam在WebArena上显著超越了现有方法,成功率提升高达161%。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)的Web Agent,旨在提升自动化Web任务的效率。现有方法通常依赖手工设计的策略和上下文示例,泛化能力有限,并且忽略了Web Agent的观察/动作表示与LLM预训练数据之间的不匹配。本文通过简单地优化LLM驱动的Web Agent的观察和动作空间,使其更好地与LLM的能力对齐,从而显著提升了其在各种Web任务上的性能。在WebArena基准测试中,AgentOccam超越了先前的state-of-the-art方法和同期工作,分别提高了9.8个百分点(+29.4%)和5.9个百分点(+15.8%),并且相对于类似的普通Web Agent,成功率提高了26.6个百分点(+161%)。该方法无需上下文示例、新的Agent角色、在线反馈或搜索策略,突显了LLM在Web任务上的强大零样本性能,并强调了仔细调整观察和动作空间的关键作用。
🔬 方法详解
问题定义:现有基于LLM的Web Agent在处理Web任务时,由于其观察和动作空间与LLM的预训练数据存在不匹配,导致性能受限。以往的研究往往侧重于手工设计复杂的策略和上下文示例,而忽略了这种根本性的不匹配问题。这些手工设计的策略难以泛化到各种真实世界的Web场景中。
核心思路:本文的核心思路是,通过简单地调整Web Agent的观察和动作空间,使其更好地适应LLM的固有能力,从而提升其在Web任务上的零样本性能。这种方法避免了复杂的策略设计和大量的上下文示例,更加简洁有效。核心假设是,LLM本身具备强大的Web任务处理能力,关键在于如何有效地利用这些能力。
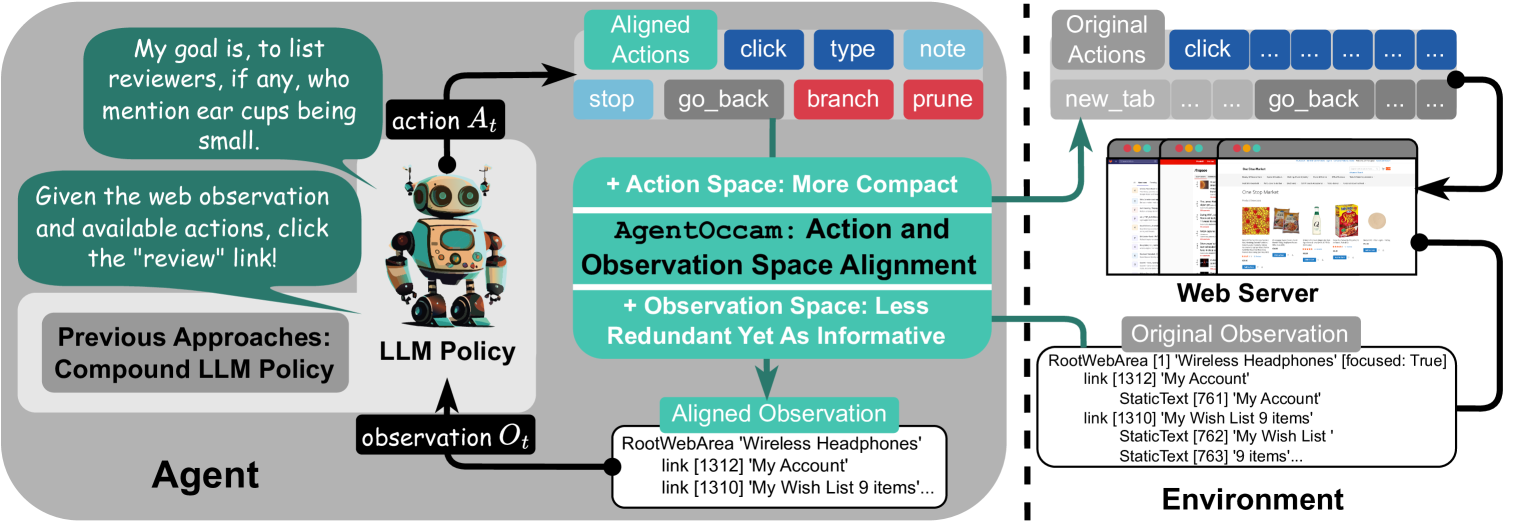
技术框架:AgentOccam的技术框架非常简洁。它主要包含一个LLM作为核心决策模块,以及经过精心设计的观察空间和动作空间。观察空间用于将Web页面的信息以LLM易于理解的方式呈现给LLM。动作空间定义了Agent可以执行的Web操作,例如点击链接、填写表单等。整个流程是:Agent接收Web页面的观察信息,LLM根据观察信息生成动作指令,Agent执行动作指令,然后接收新的Web页面观察信息,循环往复直到完成任务。
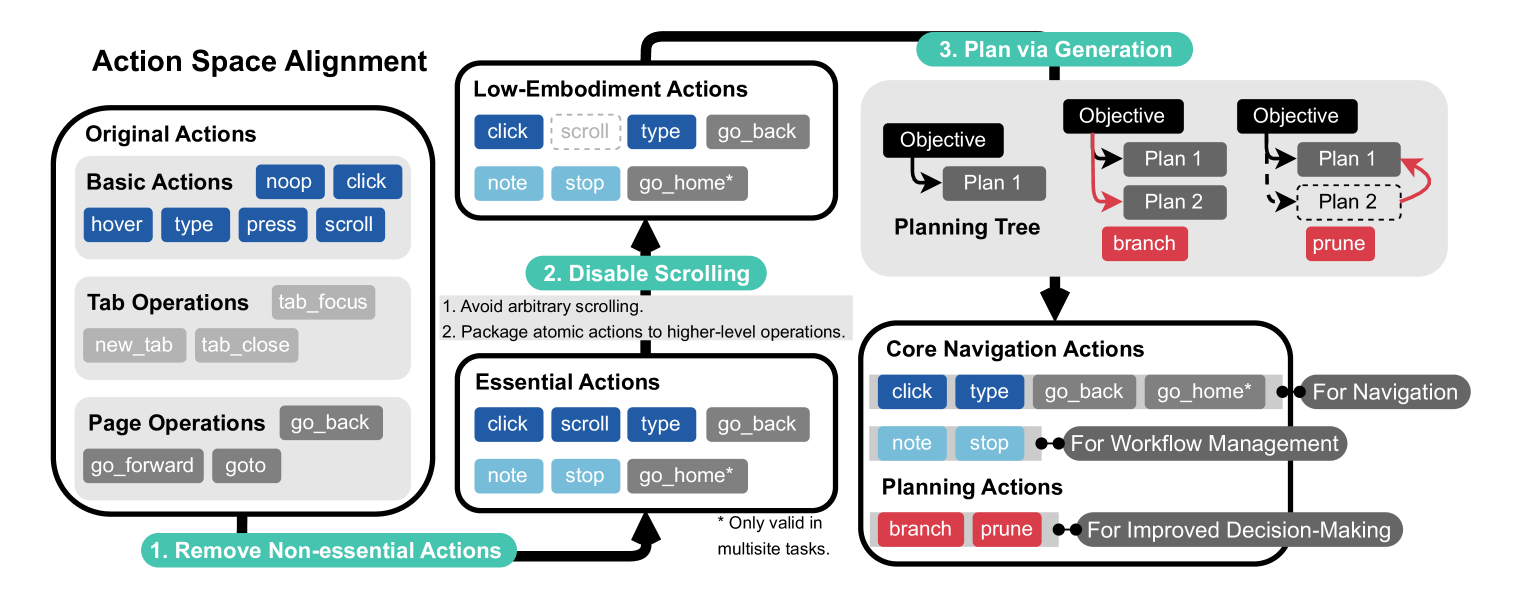
关键创新:AgentOccam最重要的技术创新点在于其对观察和动作空间的精细设计。与以往方法不同,AgentOccam没有采用复杂的策略或上下文示例,而是专注于如何将Web页面的信息以最有效的方式传递给LLM,并让LLM能够以最自然的方式执行Web操作。这种以数据对齐为核心的设计理念是与现有方法的本质区别。
关键设计:AgentOccam的关键设计在于其观察和动作空间的具体实现。观察空间的设计需要考虑如何有效地提取Web页面的关键信息,例如文本、链接、表单等,并将其转换为LLM可以理解的自然语言描述。动作空间的设计需要考虑如何定义Agent可以执行的Web操作,并确保这些操作能够覆盖各种常见的Web任务。具体的参数设置和网络结构取决于所使用的LLM和Web环境,但核心原则是保持简洁和易于理解。
🖼️ 关键图片

📊 实验亮点
AgentOccam在WebArena基准测试中取得了显著的性能提升。相对于先前的state-of-the-art方法,AgentOccam的成功率提高了9.8个百分点(+29.4%)。更重要的是,相对于类似的普通Web Agent,AgentOccam的成功率提高了26.6个百分点(+161%)。这些结果充分证明了优化观察和动作空间对于提升LLM驱动的Web Agent性能的重要性。
🎯 应用场景
AgentOccam的研究成果可以广泛应用于自动化Web任务,例如在线购物、机票预订、信息检索等。通过提升Web Agent的自动化水平,可以显著提高用户效率,降低人工成本。未来,该技术还可以应用于智能助手、自动化测试等领域,具有广阔的应用前景。
📄 摘要(原文)
Autonomy via agents using large language models (LLMs) for personalized, standardized tasks boosts human efficiency. Automating web tasks (like booking hotels within a budget) is increasingly sought after. Fulfilling practical needs, the web agent also serves as an important proof-of-concept example for various agent grounding scenarios, with its success promising advancements in many future applications. Prior research often handcrafts web agent strategies (e.g., prompting templates, multi-agent systems, search methods, etc.) and the corresponding in-context examples, which may not generalize well across all real-world scenarios. On the other hand, there has been limited study on the misalignment between a web agent's observation/action representation and the pre-training data of the LLM it's based on. This discrepancy is especially notable when LLMs are primarily trained for language completion rather than tasks involving embodied navigation actions and symbolic web elements. Our study enhances an LLM-based web agent by simply refining its observation and action space to better align with the LLM's capabilities. This approach enables our base agent to significantly outperform previous methods on a wide variety of web tasks. Specifically, on WebArena, a benchmark featuring general-purpose web interaction tasks, our agent AgentOccam surpasses the previous state-of-the-art and concurrent work by 9.8 (+29.4%) and 5.9 (+15.8%) absolute points respectively, and boosts the success rate by 26.6 points (+161%) over similar plain web agents with its observation and action space alignment. We achieve this without using in-context examples, new agent roles, online feedback or search strategies. AgentOccam's simple design highlights LLMs' impressive zero-shot performance on web tasks, and underlines the critical role of carefully tuning observation and action spaces for LLM-based agents.