Optimal Quantization for Matrix Multiplication
作者: Or Ordentlich, Yury Polyanskiy
分类: cs.IT, cs.AI, cs.CL, cs.LG
发布日期: 2024-10-17 (更新: 2025-10-15)
💡 一句话要点
针对矩阵乘法,提出一种基于嵌套格的渐近最优量化方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 矩阵量化 矩阵乘法 率失真理论 嵌套格 大语言模型
📋 核心要点
- 现有矩阵量化方法在加速矩阵乘法时,缺乏对矩阵乘积误差的直接优化和理论分析。
- 提出一种基于嵌套格的量化方案,显式保证矩阵乘积的近似误差,并证明其渐近最优性。
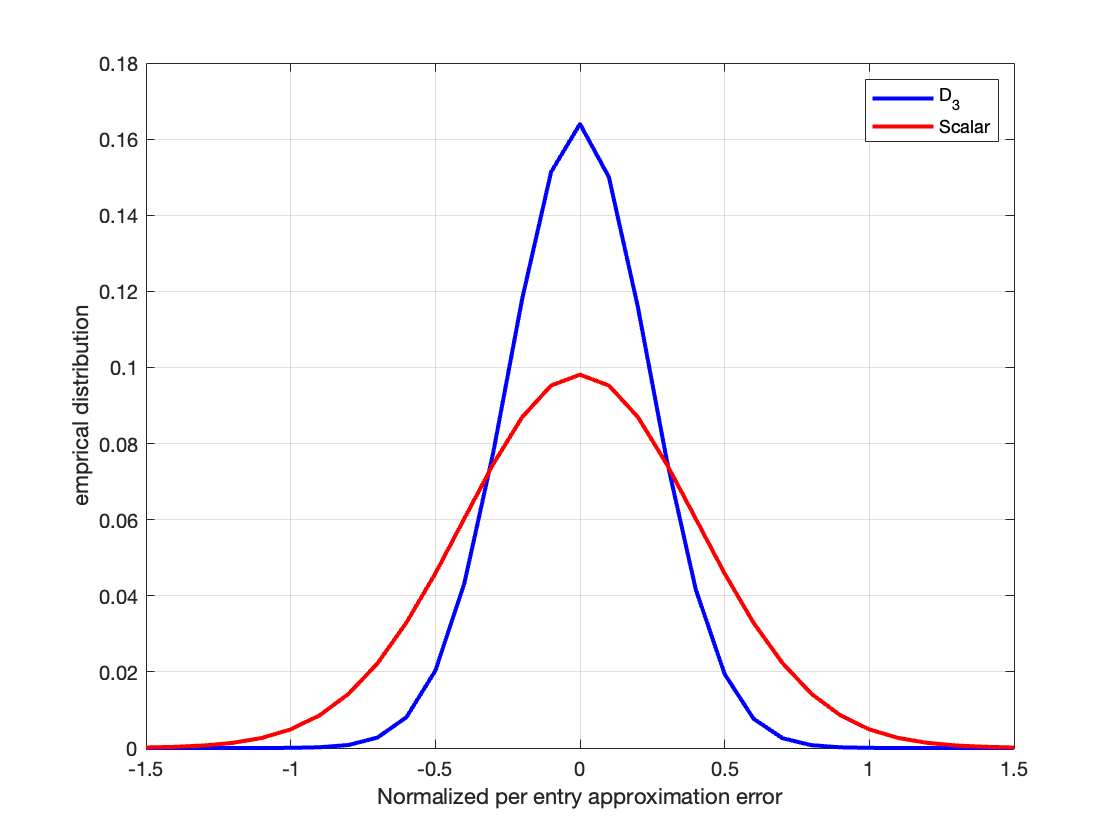
- 实验表明,该量化器在高斯矩阵乘法中达到理论下界,且低复杂度版本性能接近最优。
📝 摘要(中文)
本文针对矩阵乘法中的有损压缩(量化)问题,提出了一种新的量化方法。该方法旨在压缩大型矩阵,加速矩阵乘法运算,尤其是在大语言模型中,矩阵加载速度是瓶颈。与传统向量量化和率失真理论不同,本文关注的是矩阵乘积的近似,而非矩阵本身的近似。给定矩阵A和B,分别对其进行编码,每个条目使用R比特。解码器利用这些表示估计矩阵乘积A^T B。本文为独立同分布高斯矩阵的均方误差提供了一个非渐近下界(作为速率R的函数)。在算法上,我们构建了一个基于嵌套格的通用量化器,针对任意矩阵对A和B,给出了近似误差的显式保证,误差仅与Frobenius范数||A||_F, ||B||_F和||A^T B||_F有关,其中A和B是列中心化的版本。对于独立同分布高斯矩阵,我们的量化器达到了下界,因此是渐近最优的。一个实用的低复杂度版本也取得了接近最优的性能。此外,我们推导了独立同分布高斯矩阵乘法的率失真函数,该函数在R≈0.906比特/条目处表现出一个有趣的相变,表明在低速率情况下需要Johnson-Lindestrauss降维(草图)。
🔬 方法详解
问题定义:论文旨在解决矩阵乘法中,对输入矩阵进行量化压缩后,如何最小化矩阵乘积的近似误差的问题。现有方法通常关注矩阵本身的重构误差,而忽略了矩阵乘法这一特定应用场景的需求。此外,缺乏对量化误差的理论下界分析,难以评估量化算法的优劣。
核心思路:论文的核心思路是设计一种针对矩阵乘积优化的量化方案。通过分析矩阵乘积的误差特性,设计了一种基于嵌套格的量化器,该量化器能够显式地控制矩阵乘积的近似误差。同时,推导了高斯矩阵乘法的率失真函数,为量化算法的性能评估提供了理论依据。
技术框架:该方法包含以下几个主要步骤:1. 对输入矩阵A和B进行列中心化,得到A_bar和B_bar。2. 使用基于嵌套格的量化器分别对A_bar和B_bar进行量化,得到量化后的矩阵A_q和B_q。3. 使用量化后的矩阵A_q和B_q计算矩阵乘积A_q^T B_q,作为原始矩阵乘积A^T B的近似。4. 通过理论分析和实验验证,评估量化方案的性能。
关键创新:该论文的关键创新在于:1. 提出了一种针对矩阵乘积优化的量化方案,直接优化矩阵乘积的近似误差。2. 推导了高斯矩阵乘法的率失真函数,为量化算法的性能评估提供了理论依据。3. 设计了一种基于嵌套格的量化器,该量化器能够显式地控制矩阵乘积的近似误差,并具有渐近最优性。
关键设计:该量化器的关键设计包括:1. 使用嵌套格结构,实现对矩阵元素的精细量化。2. 量化器的参数(如格的密度)根据矩阵的Frobenius范数进行自适应调整,以保证量化误差的最小化。3. 针对高斯矩阵,选择合适的格结构,以达到率失真函数的下界。
🖼️ 关键图片
📊 实验亮点
该论文提出的量化器在高斯矩阵乘法中达到了理论率失真函数的下界,证明了其渐近最优性。同时,一个实用的低复杂度版本也取得了接近最优的性能,验证了该方法的有效性和实用性。此外,论文还揭示了高斯矩阵乘法率失真函数的一个有趣的相变现象。
🎯 应用场景
该研究成果可应用于大语言模型、推荐系统、图神经网络等领域,通过对模型参数或中间计算结果进行量化压缩,降低内存占用和计算复杂度,从而加速模型训练和推理过程。尤其是在资源受限的边缘设备上,该技术具有重要的应用价值。
📄 摘要(原文)
Recent work in machine learning community proposed multiple methods for performing lossy compression (quantization) of large matrices. This quantization is important for accelerating matrix multiplication (main component of large language models), which is often bottlenecked by the speed of loading these matrices from memory. Unlike classical vector quantization and rate-distortion theory, the goal of these new compression algorithms is to be able to approximate not the matrices themselves, but their matrix product. Specifically, given a pair of real matrices $A,B$ an encoder (compressor) is applied to each of them independently producing descriptions with $R$ bits per entry. These representations subsequently are used by the decoder to estimate matrix product $A^\top B$. In this work, we provide a non-asymptotic lower bound on the mean squared error of this approximation (as a function of rate $R$) for the case of matrices $A,B$ with iid Gaussian entries. Algorithmically, we construct a universal quantizer based on nested lattices with an explicit guarantee of approximation error for any (non-random) pair of matrices $A$, $B$ in terms of only Frobenius norms $\|\bar{A}\|_F, \|\bar{B}\|_F$ and $\|\bar{A}^\top \bar{B}\|_F$, where $\bar{A},\bar{B}$ are versions of $A,B$ with zero-centered columns, respectively. For iid Gaussian matrices our quantizer achieves the lower bound and is, thus, asymptotically optimal. A practical low-complexity version of our quantizer achieves performance quite close to optimal. In addition, we derive rate-distortion function for matrix multiplication of iid Gaussian matrices, which exhibits an interesting phase-transition at $R\approx 0.906$ bit/entry, showing necessity of Johnson-Lindestrauss dimensionality reduction (sketching) in the low-rate regime.