Large Language Models as Narrative-Driven Recommenders
作者: Lukas Eberhard, Thorsten Ruprechter, Denis Helic
分类: cs.IR, cs.AI, cs.CL
发布日期: 2024-10-17
备注: Under review; 19 pages
💡 一句话要点
利用大型语言模型进行叙事驱动的电影推荐,显著优于传统方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 叙事驱动推荐 电影推荐 自然语言理解 个性化推荐
📋 核心要点
- 现有叙事驱动推荐系统难以理解用户自由文本表达的复杂需求,导致推荐结果不尽人意。
- 利用大型语言模型强大的自然语言理解能力,直接根据用户叙述生成个性化电影推荐。
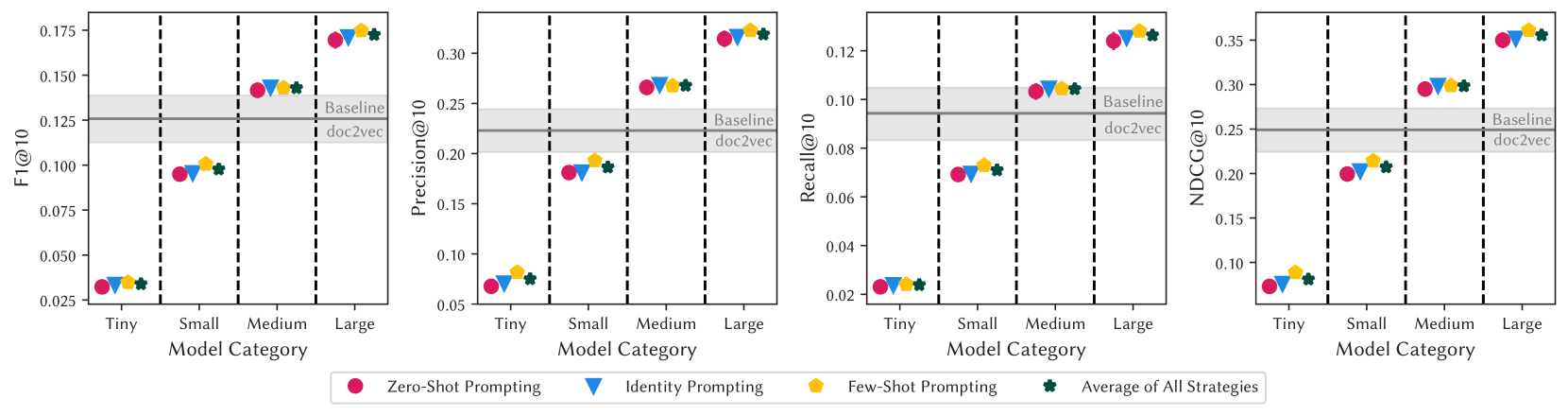
- 实验表明,LLM显著优于传统方法,即使是中等规模的开源模型也表现出强大的竞争力。
📝 摘要(中文)
本文探讨了大型语言模型(LLMs)在叙事驱动推荐中的应用,旨在为用户以自由文本表达的请求提供个性化建议,例如“我想看一部像《禁闭岛》那样剧情烧脑的惊悚片”。尽管LLMs在处理通用自然语言查询方面表现出色,但其在处理此类推荐请求方面的有效性仍有待探索。为了弥补这一差距,我们比较了38个不同规模的开源和闭源LLMs(如LLama 3.2和GPT-4o)在电影推荐场景中的性能。为此,我们利用了一个黄金标准的、由众包工作者标注的Reddit电影推荐社区帖子数据集,并采用了各种提示策略,包括零样本、身份和少样本提示。我们的研究结果表明,LLMs能够生成上下文相关的电影推荐,显著优于其他最先进的方法,如doc2vec。虽然我们发现闭源和大型参数模型通常表现最佳,但中等规模的开源模型仍然具有竞争力,仅略逊于计算成本更高的模型。此外,我们观察到大多数模型的提示策略之间没有显著差异,突显了零样本提示等简单方法在叙事驱动推荐中的有效性。总的来说,这项工作为推荐系统研究人员以及旨在将LLMs集成到实际推荐工具中的从业者提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决叙事驱动的电影推荐问题,即根据用户提供的自由文本描述(例如,“我想看一部关于时间旅行的科幻电影”)推荐合适的电影。现有方法,如基于协同过滤或内容过滤的方法,难以有效理解和利用用户叙述中的复杂语义信息,导致推荐结果的相关性和个性化程度较低。
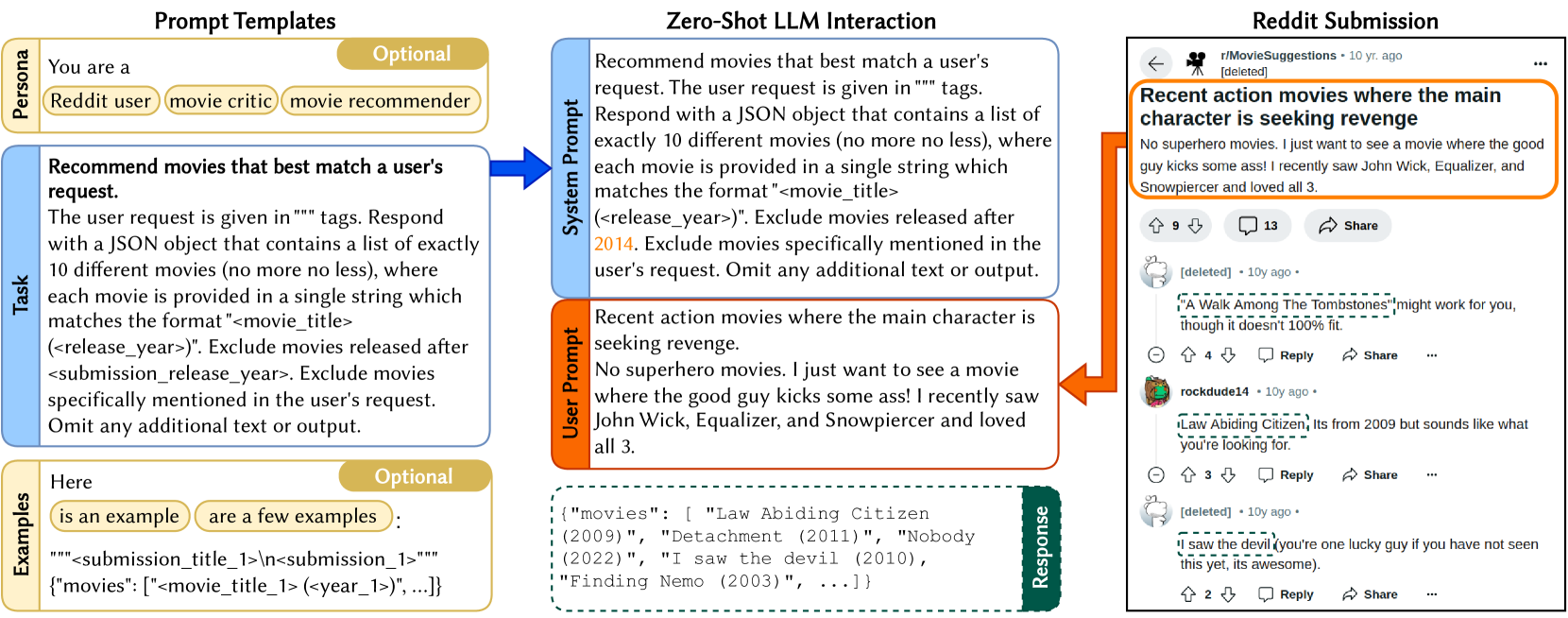
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的自然语言理解和生成能力,直接将用户的叙述作为输入,生成电影推荐。这种方法避免了传统方法中需要手动提取特征或构建复杂的知识图谱的步骤,从而简化了推荐流程并提高了推荐的准确性。
技术框架:该研究采用了一种直接的端到端方法。用户提供的电影推荐请求被直接输入到LLM中,LLM根据请求生成一个电影列表。研究人员使用了各种提示策略(如零样本、身份和少样本提示)来引导LLM生成更相关的推荐。然后,通过人工评估或与现有方法进行比较来评估LLM生成的推荐结果的质量。
关键创新:该研究的关键创新在于直接将LLM应用于叙事驱动的电影推荐问题,并证明了其有效性。与传统方法相比,LLM能够更好地理解用户叙述中的复杂语义信息,并生成更个性化和相关的推荐。此外,该研究还比较了不同规模和类型的LLM在推荐任务中的性能,为实际应用中选择合适的LLM提供了指导。
关键设计:研究中使用了多种LLM,包括开源模型(如LLama 3.2)和闭源模型(如GPT-4o)。采用了不同的提示策略,例如:零样本提示(直接向LLM提出请求)、身份提示(告诉LLM它是一个电影推荐系统)和少样本提示(提供一些示例请求和推荐)。评估指标包括推荐结果的相关性、多样性和个性化程度。具体参数设置和损失函数取决于所使用的LLM的默认设置,研究重点在于比较不同LLM和提示策略的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在叙事驱动的电影推荐任务中显著优于传统的doc2vec方法。闭源和大型参数模型通常表现最佳,但中等规模的开源模型也具有竞争力。此外,零样本提示等简单方法在大多数模型中表现良好,无需复杂的提示工程。
🎯 应用场景
该研究成果可应用于各种个性化推荐系统,例如电影、书籍、音乐等。通过理解用户以自然语言表达的需求,可以提供更精准、更符合用户兴趣的推荐结果,提升用户体验。未来,可以将LLM与知识图谱等技术结合,进一步提高推荐系统的性能和可解释性。
📄 摘要(原文)
Narrative-driven recommenders aim to provide personalized suggestions for user requests expressed in free-form text such as "I want to watch a thriller with a mind-bending story, like Shutter Island." Although large language models (LLMs) have been shown to excel in processing general natural language queries, their effectiveness for handling such recommendation requests remains relatively unexplored. To close this gap, we compare the performance of 38 open- and closed-source LLMs of various sizes, such as LLama 3.2 and GPT-4o, in a movie recommendation setting. For this, we utilize a gold-standard, crowdworker-annotated dataset of posts from reddit's movie suggestion community and employ various prompting strategies, including zero-shot, identity, and few-shot prompting. Our findings demonstrate the ability of LLMs to generate contextually relevant movie recommendations, significantly outperforming other state-of-the-art approaches, such as doc2vec. While we find that closed-source and large-parameterized models generally perform best, medium-sized open-source models remain competitive, being only slightly outperformed by their more computationally expensive counterparts. Furthermore, we observe no significant differences across prompting strategies for most models, underscoring the effectiveness of simple approaches such as zero-shot prompting for narrative-driven recommendations. Overall, this work offers valuable insights for recommender system researchers as well as practitioners aiming to integrate LLMs into real-world recommendation tools.