Embedding Self-Correction as an Inherent Ability in Large Language Models for Enhanced Mathematical Reasoning
作者: Kuofeng Gao, Huanqia Cai, Qingyao Shuai, Dihong Gong, Zhifeng Li
分类: cs.AI, cs.CL
发布日期: 2024-10-14 (更新: 2025-02-08)
💡 一句话要点
提出链式自我修正机制以提升大语言模型的数学推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 自我修正 链式机制 深度学习 模型训练 零-shot学习
📋 核心要点
- 现有的大语言模型在数学推理中常常出现错误,导致结果不准确,影响其在相关领域的应用。
- 本文提出的链式自我修正机制(CoSC)通过嵌入自我修正能力,使LLMs能够验证和纠正自身的推理结果。
- 实验结果显示,CoSC显著提升了模型在数学数据集上的表现,尤其是CoSC-Code-34B模型在MATH数据集上取得了53.5%的得分。
📝 摘要(中文)
准确的数学推理对于依赖此类推理的领域至关重要。然而,大语言模型(LLMs)在某些数学推理方面常常遇到困难,导致推理错误和结果不准确。为了解决这些问题,本文提出了一种新机制——链式自我修正(CoSC),旨在将自我修正嵌入LLMs中,使其能够验证和纠正自身结果。CoSC通过一系列自我修正阶段运行,每个阶段生成程序以解决给定问题,执行程序并验证输出。基于验证结果,LLMs决定是否进入下一个修正阶段或最终确定答案。实验表明,CoSC在标准数学数据集上的表现显著优于现有开源LLMs,尤其是CoSC-Code-34B模型在MATH数据集上取得了53.5%的得分,超越了ChatGPT、GPT-4及多模态LLMs如GPT-4V和Gemini-1.0。重要的是,CoSC以零-shot方式运行,无需示范。
🔬 方法详解
问题定义:本文旨在解决大语言模型在数学推理中常见的错误和不准确性,现有方法在自我验证和修正方面存在不足。
核心思路:提出链式自我修正机制(CoSC),通过多个自我修正阶段,使模型能够生成、执行并验证程序,从而逐步提高推理的准确性。
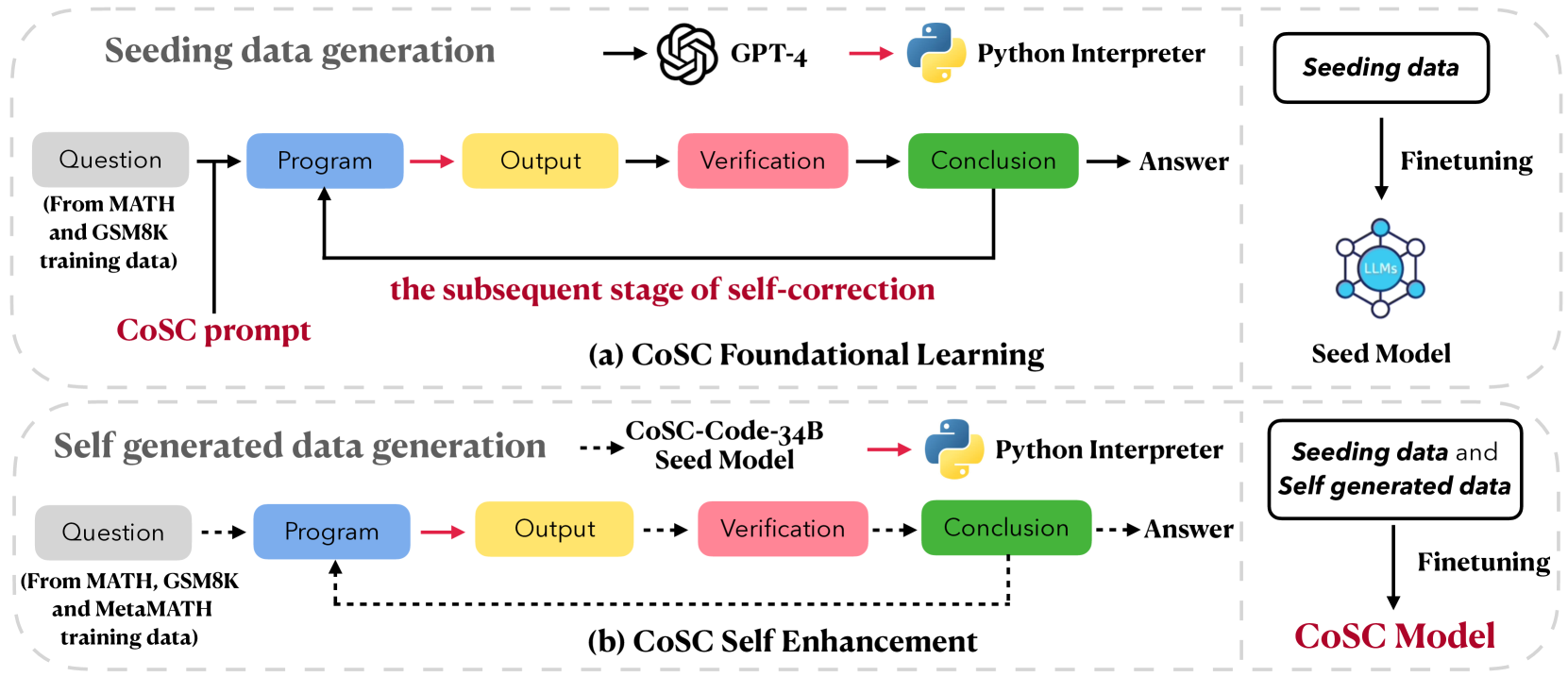
技术框架:CoSC的整体架构包括两个主要阶段:首先使用少量从GPT-4生成的种子数据进行初步训练,然后利用大量自生成数据进行进一步的增强训练。每个阶段都包含生成程序、执行程序和验证输出的步骤。
关键创新:CoSC的核心创新在于将自我修正嵌入到LLMs中,使其能够在零-shot情况下进行推理和修正,这与传统方法依赖外部示范的方式有本质区别。
关键设计:在训练过程中,采用了两阶段的微调方法,初期使用小规模数据,后期使用自生成的大规模数据,确保模型在自我修正能力上的提升。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoSC机制显著提升了模型的数学推理能力,CoSC-Code-34B模型在MATH数据集上取得了53.5%的得分,超越了ChatGPT、GPT-4及其他多模态模型,显示出其在数学推理任务中的优越性。
🎯 应用场景
该研究的潜在应用领域包括教育、科学计算和工程设计等需要精确数学推理的场景。通过提升大语言模型的数学推理能力,可以在自动化问题解决、智能辅导系统等方面发挥重要作用,未来可能对相关行业产生深远影响。
📄 摘要(原文)
Accurate mathematical reasoning with Large Language Models (LLMs) is crucial in revolutionizing domains that heavily rely on such reasoning. However, LLMs often encounter difficulties in certain aspects of mathematical reasoning, leading to flawed reasoning and erroneous results. To mitigate these issues, we introduce a novel mechanism, the Chain of Self-Correction (CoSC), specifically designed to embed self-correction as an inherent ability in LLMs, enabling them to validate and rectify their own results. The CoSC mechanism operates through a sequence of self-correction stages. In each stage, the LLMs generate a program to address a given problem, execute this program using program-based tools to obtain an output, subsequently verify this output. Based on the verification, the LLMs either proceed to the next correction stage or finalize the answer. This iterative self-correction process allows the LLMs to refine its reasoning steps and improve the accuracy of its mathematical reasoning. We implement CoSC using a two-phase fine-tuning approach. First, LLMs are trained with a relatively small volume of seeding data generated from GPT-4. Then, we enhance CoSC by training with a larger volume of self-generated data, without relying on GPT-4. Experiments show that CoSC significantly boosts performance on standard mathematical datasets compared to existing open-source LLMs. Notably, our CoSC-Code-34B model achieved a 53.5% score on the challenging MATH dataset, outperforming models like ChatGPT, GPT-4, and multi-modal LLMs such as GPT-4V and Gemini-1.0. Importantly, CoSC operates in a zero-shot manner without requiring demonstrations.