Overcoming classic challenges for artificial neural networks by providing incentives and practice
作者: Kazuki Irie, Brenden M. Lake
分类: cs.AI, cs.LG, q-bio.NC
发布日期: 2024-10-14 (更新: 2025-09-16)
备注: In press at Nature Machine Intelligence
💡 一句话要点
通过激励与实践,元学习克服了人工神经网络的经典挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 元学习 人工神经网络 系统泛化 灾难性遗忘 少样本学习 多步推理 激励机制 实践学习
📋 核心要点
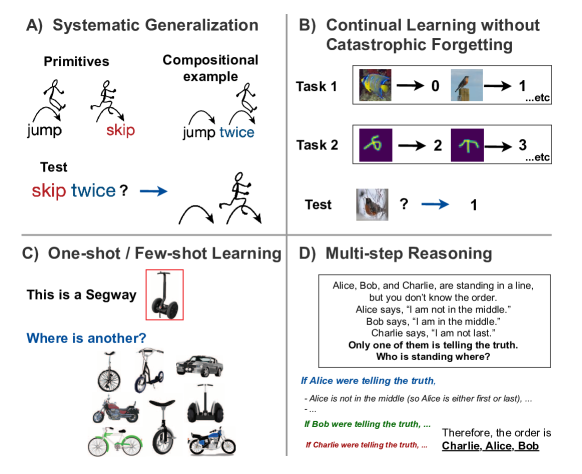
- 人工神经网络在系统泛化、灾难性遗忘、少样本学习和多步推理等方面存在不足,难以匹敌人类认知能力。
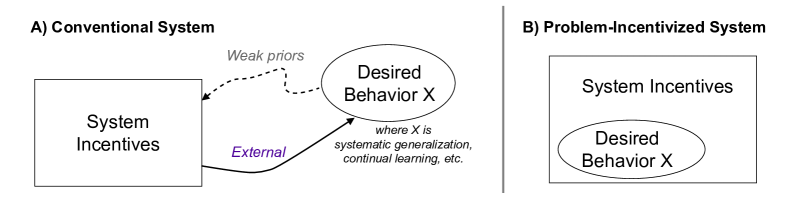
- 论文提出通过元学习,为神经网络提供改进特定技能的激励和实践机会,从而显式地优化模型性能。
- 研究表明,这种方法在解决上述四个经典挑战方面取得了显著进展,并解释了大型语言模型成功的部分原因。
📝 摘要(中文)
本文回顾了使用元学习克服人工神经网络(ANN)模型在认知能力方面相较于人类的弱点的最新研究。这些弱点可归纳为激励与实践问题,即为机器提供改进特定技能的激励和实践机会。这种显式优化与期望通过优化相关但不同的目标来涌现期望行为的传统方法形成对比。本文回顾了该原则在解决ANN的四个经典挑战中的应用:系统泛化、灾难性遗忘、少样本学习和多步推理。此外,还讨论了大型语言模型如何结合元学习框架的关键方面(即,在多样化数据上训练的带有反馈的序列预测),这有助于解释它们在这些经典挑战中的成功。最后,讨论了通过该框架理解人类发展的前景,以及自然环境是否为学习如何进行具有挑战性的泛化提供了正确的激励和实践。
🔬 方法详解
问题定义:人工神经网络在系统泛化、灾难性遗忘、少样本学习和多步推理等方面面临挑战。传统的训练方法通常依赖于优化相关但不同的目标,期望目标行为能够自然涌现,但效果往往不尽如人意。现有的神经网络模型难以像人类一样快速适应新任务,并且容易遗忘先前学习的知识。
核心思路:论文的核心思路是借鉴人类学习的方式,即通过提供明确的激励和大量的实践机会来提升神经网络的性能。具体来说,就是利用元学习框架,让模型学习如何学习,从而能够更快地适应新任务,并且更好地保持已有的知识。这种方法强调显式优化,直接针对目标技能进行训练,而不是依赖于间接的优化方式。
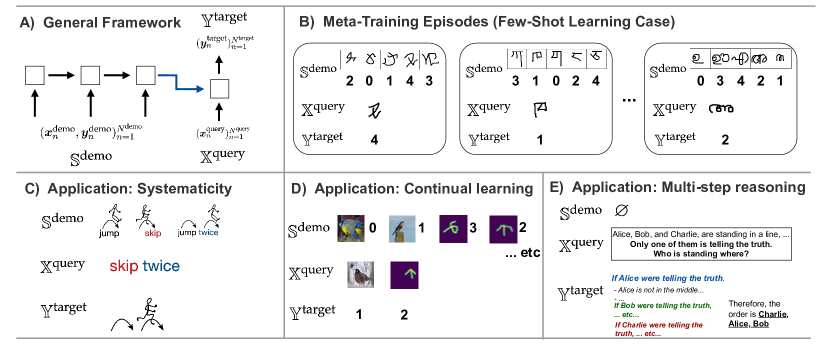
技术框架:论文主要探讨了元学习在解决ANN经典挑战中的应用。整体框架可以概括为:首先,定义一个元学习任务,该任务包含多个子任务,每个子任务代表一个需要学习的技能。然后,使用元学习算法训练模型,使其能够快速适应新的子任务。在训练过程中,模型会接收到关于其表现的反馈,并根据反馈调整自身的参数。通过不断地学习和实践,模型逐渐掌握了如何学习新技能的通用策略。
关键创新:论文的关键创新在于强调了激励和实践在神经网络学习中的重要性。与传统的训练方法不同,该方法不是简单地提供大量的数据,而是有针对性地设计训练任务,并提供明确的反馈信号,引导模型朝着期望的方向发展。此外,论文还探讨了大型语言模型如何通过结合元学习框架的关键方面(例如,在多样化数据上训练的带有反馈的序列预测)来提升其性能。
关键设计:论文中涉及的具体技术细节取决于所解决的具体问题。例如,在解决灾难性遗忘问题时,可以使用基于记忆回放的方法,将先前学习的知识存储在记忆模块中,并在训练新任务时进行回放,从而避免遗忘。在解决少样本学习问题时,可以使用基于度量学习的方法,学习一个度量空间,使得相似的样本在空间中距离较近,不相似的样本距离较远。具体的参数设置、损失函数和网络结构需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
论文回顾了元学习在解决系统泛化、灾难性遗忘、少样本学习和多步推理等经典挑战中的应用,并指出大型语言模型通过结合元学习框架的关键方面取得了成功。虽然没有提供具体的性能数据,但强调了激励和实践在提升神经网络性能方面的重要性,为未来的研究方向提供了新的思路。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、智能助手等领域,提升机器在复杂环境下的适应性和学习能力。通过模拟人类的学习方式,可以开发出更加智能、可靠的AI系统,更好地服务于社会。未来的研究可以进一步探索如何设计更有效的激励机制和实践环境,从而推动人工智能技术的进步。
📄 摘要(原文)
Since the earliest proposals for artificial neural network (ANN) models of the mind and brain, critics have pointed out key weaknesses in these models compared to human cognitive abilities. Here we review recent work that uses metalearning to overcome several classic challenges, which we characterize as addressing the Problem of Incentive and Practice -- that is, providing machines with both incentives to improve specific skills and opportunities to practice those skills. This explicit optimization contrasts with more conventional approaches that hope the desired behaviour will emerge through optimizing related but different objectives. We review applications of this principle to addressing four classic challenges for ANNs: systematic generalization, catastrophic forgetting, few-shot learning and multi-step reasoning. We also discuss how large language models incorporate key aspects of this metalearning framework (namely, sequence prediction with feedback trained on diverse data), which helps to explain some of their successes on these classic challenges. Finally, we discuss the prospects for understanding aspects of human development through this framework, and whether natural environments provide the right incentives and practice for learning how to make challenging generalizations.