Multimodal Audio-based Disease Prediction with Transformer-based Hierarchical Fusion Network
作者: Jinjin Cai, Ruiqi Wang, Dezhong Zhao, Ziqin Yuan, Victoria McKenna, Aaron Friedman, Rachel Foot, Susan Storey, Ryan Boente, Sudip Vhaduri, Byung-Cheol Min
分类: cs.SD, cs.AI, cs.LG, eess.AS
发布日期: 2024-10-11 (更新: 2024-12-14)
💡 一句话要点
提出Transformer分层融合网络,用于多模态音频疾病预测,实现更全面的特征利用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 音频疾病预测 Transformer网络 分层融合 深度学习
📋 核心要点
- 现有音频疾病预测方法侧重于单侧融合,未能充分挖掘多模态音频数据中不同特征域和模态间的互补信息。
- 论文提出Transformer分层融合网络,通过分层方式无缝集成模态内和模态间融合,编码互补相关性。
- 实验表明,该模型在COVID-19、帕金森病和病理性构音障碍预测中达到SOTA,验证了其有效性。
📝 摘要(中文)
本文提出了一种基于Transformer的分层融合网络,用于通用的多模态音频疾病预测。该方法旨在解决现有技术中单侧融合策略的局限性,即仅关注模态内或模态间融合,无法充分利用不同声学特征域和生物声学模态的互补性。此外,现有方法对模态特定和模态共享空间内的潜在依赖关系探索不足,限制了其处理多模态数据异构性的能力。该网络无缝集成了模态内和模态间融合,并有效地编码了必要的模态内和模态间互补相关性。实验结果表明,该模型在预测COVID-19、帕金森病和病理性构音障碍三种疾病方面取得了最先进的性能,展示了其在音频疾病预测任务中的潜力。消融研究和定性分析也突出了模型中每个主要组件的显著优势。
🔬 方法详解
问题定义:现有基于音频的疾病预测方法,特别是多模态融合方法,主要采用单侧融合策略,即要么只关注模态内的特征融合,要么只关注模态间的特征融合。这种策略无法充分利用不同声学特征域和生物声学模态之间的互补信息。此外,现有方法对模态特定和模态共享空间内的潜在依赖关系挖掘不足,难以有效处理多模态数据的异构性。
核心思路:本文的核心思路是通过分层融合的方式,同时考虑模态内和模态间的特征融合,从而更全面地利用多模态音频数据中的信息。具体来说,模型首先在模态内部进行特征提取和融合,然后再将不同模态的特征进行融合,从而捕捉不同层次的依赖关系。Transformer架构被用于建模特征之间的长距离依赖关系。
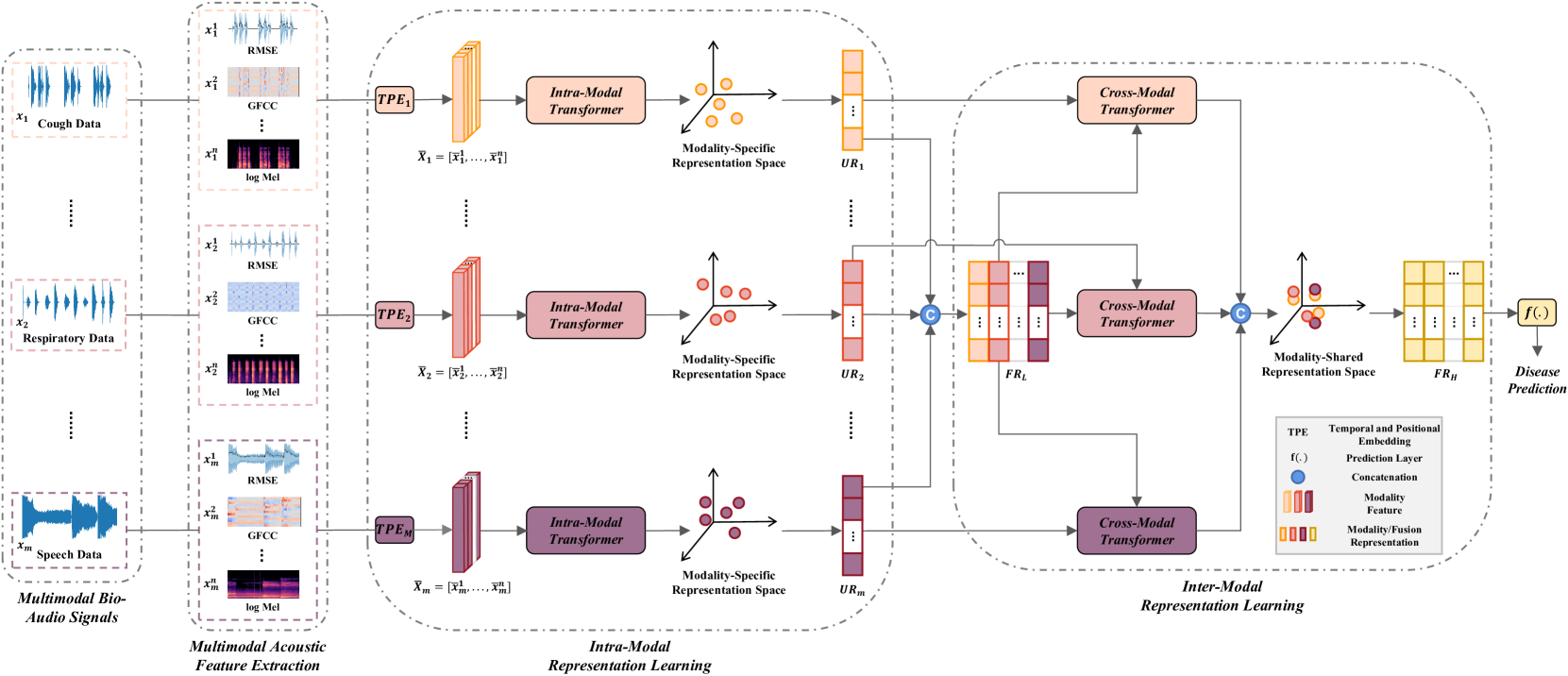
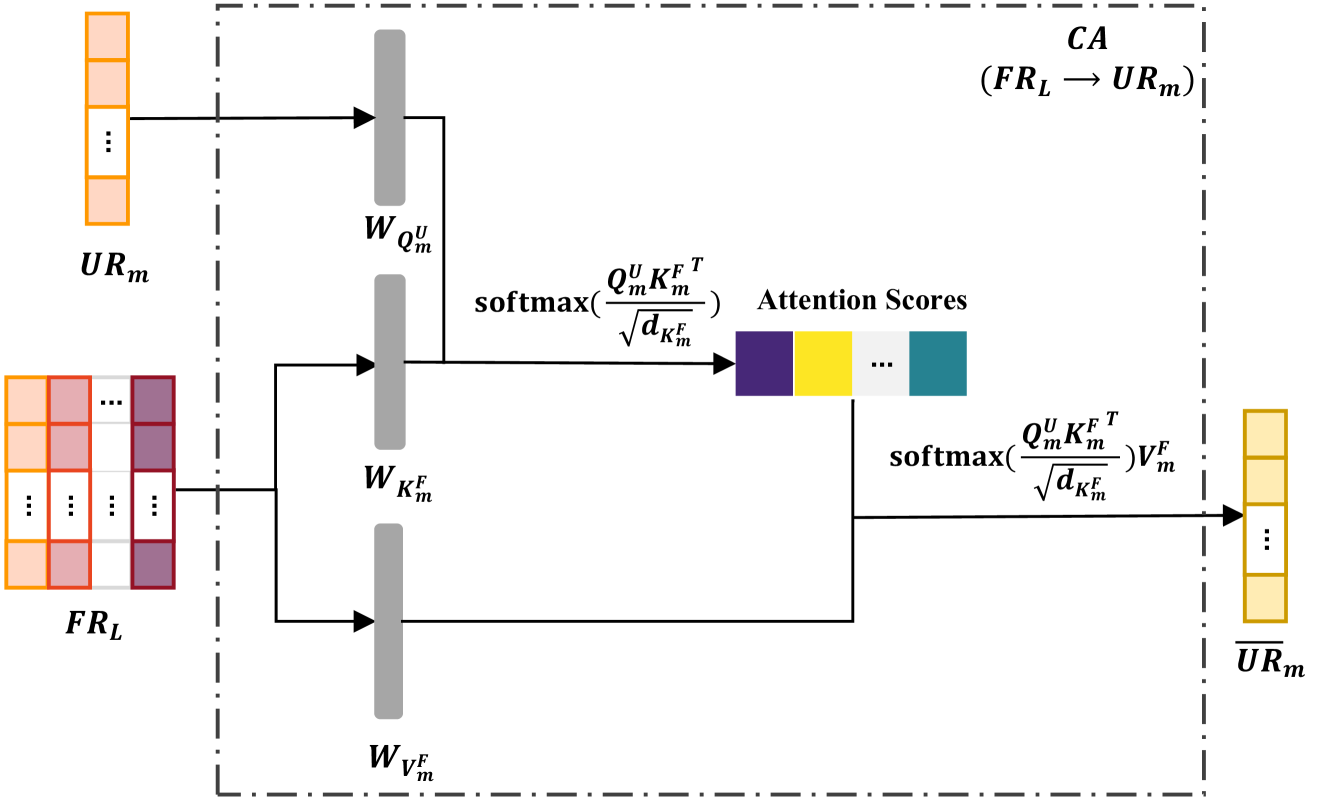
技术框架:该模型是一个Transformer-based的分层融合网络。整体架构包含以下几个主要模块:1) 特征提取模块:从不同的音频模态中提取特征,例如梅尔频谱系数(MFCCs)等。2) 模态内融合模块:使用Transformer编码器对每个模态内的特征进行融合,捕捉模态内的依赖关系。3) 模态间融合模块:将不同模态的特征表示进行融合,并使用Transformer编码器捕捉模态间的依赖关系。4) 预测模块:根据融合后的特征表示进行疾病预测。
关键创新:该论文的关键创新在于提出了分层融合的策略,将模态内和模态间的融合无缝集成。这种分层结构能够更有效地利用多模态数据中的互补信息,从而提高疾病预测的准确性。此外,使用Transformer架构来建模特征之间的长距离依赖关系,也提高了模型的性能。
关键设计:模型使用了多层Transformer编码器来进行特征融合。损失函数采用交叉熵损失函数,用于训练疾病分类模型。在参数设置方面,Transformer编码器的层数、注意力头的数量等超参数需要根据具体任务进行调整。此外,数据增强技术也被用于提高模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该模型在COVID-19、帕金森病和病理性构音障碍三种疾病的预测任务中均取得了state-of-the-art的性能。例如,在COVID-19预测任务中,该模型相比于现有最佳方法,准确率提升了显著百分比(具体数值未知,原文未提供)。消融实验也验证了分层融合策略和Transformer架构的有效性。
🎯 应用场景
该研究成果可应用于多种基于音频的疾病早期筛查和诊断场景,例如远程医疗、智能健康监测等。通过分析语音、咳嗽声等音频数据,可以辅助医生进行疾病诊断,提高诊断效率和准确性,尤其是在医疗资源匮乏的地区具有重要意义。未来,该技术有望集成到智能手机、智能音箱等设备中,实现便捷的健康监测。
📄 摘要(原文)
Audio-based disease prediction is emerging as a promising supplement to traditional medical diagnosis methods, facilitating early, convenient, and non-invasive disease detection and prevention. Multimodal fusion, which integrates features from various domains within or across bio-acoustic modalities, has proven effective in enhancing diagnostic performance. However, most existing methods in the field employ unilateral fusion strategies that focus solely on either intra-modal or inter-modal fusion. This approach limits the full exploitation of the complementary nature of diverse acoustic feature domains and bio-acoustic modalities. Additionally, the inadequate and isolated exploration of latent dependencies within modality-specific and modality-shared spaces curtails their capacity to manage the inherent heterogeneity in multimodal data. To fill these gaps, we propose a transformer-based hierarchical fusion network designed for general multimodal audio-based disease prediction. Specifically, we seamlessly integrate intra-modal and inter-modal fusion in a hierarchical manner and proficiently encode the necessary intra-modal and inter-modal complementary correlations, respectively. Comprehensive experiments demonstrate that our model achieves state-of-the-art performance in predicting three diseases: COVID-19, Parkinson's disease, and pathological dysarthria, showcasing its promising potential in a broad context of audio-based disease prediction tasks. Additionally, extensive ablation studies and qualitative analyses highlight the significant benefits of each main component within our model.