P-FOLIO: Evaluating and Improving Logical Reasoning with Abundant Human-Written Reasoning Chains
作者: Simeng Han, Aaron Yu, Rui Shen, Zhenting Qi, Martin Riddell, Wenfei Zhou, Yujie Qiao, Yilun Zhao, Semih Yavuz, Ye Liu, Shafiq Joty, Yingbo Zhou, Caiming Xiong, Dragomir Radev, Rex Ying, Arman Cohan
分类: cs.AI, cs.CL
发布日期: 2024-10-11
💡 一句话要点
P-FOLIO:利用人工编写的推理链评估并提升LLM的逻辑推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 逻辑推理 大型语言模型 数据集 推理链 微调
📋 核心要点
- 现有方法依赖二元蕴含分类或合成推理,不足以充分评估LLM的逻辑推理能力。
- P-FOLIO数据集包含人工编写的复杂推理链,用于评估和提升LLM的逻辑推理能力。
- 实验表明,P-FOLIO能显著提升LLM的逻辑推理能力,并在领域外数据集上取得显著性能提升。
📝 摘要(中文)
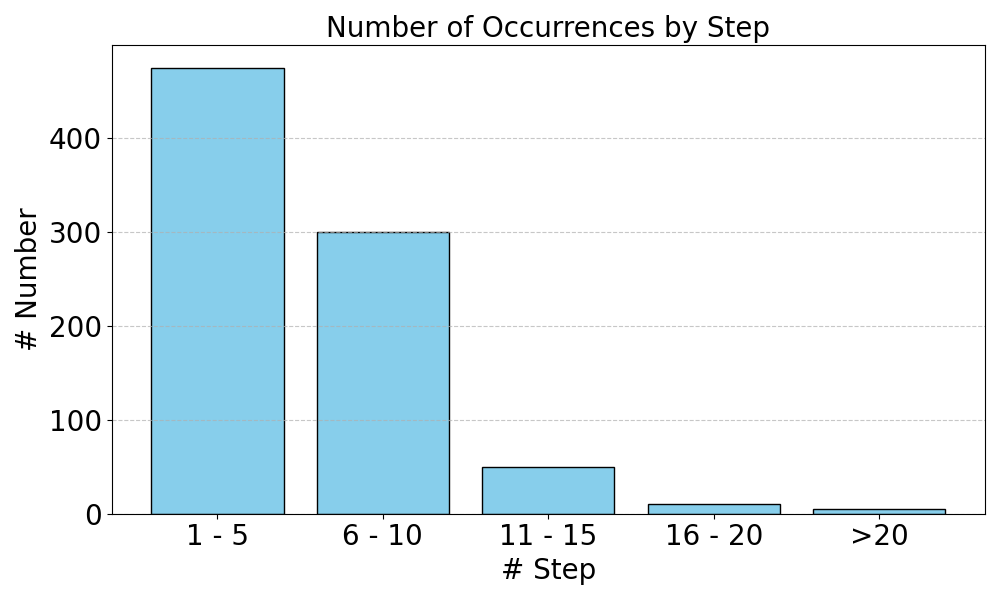
本文提出了P-FOLIO,一个人工标注的数据集,包含了一系列现实逻辑推理故事的复杂推理链。P-FOLIO的标注协议旨在帮助标注者逐步构建结构良好的自然语言证明,用于一阶逻辑推理问题。数据集中的推理步骤数量从0到20不等。我们使用P-FOLIO来评估和提升大型语言模型(LLM)的推理能力。通过单步推理规则分类,我们以更精细的粒度评估LLM的推理能力,所使用的推理规则比以往工作更加多样化,复杂程度也更高。考虑到模型生成的推理链可能与人工标注的推理链完全不同,我们从模型中抽取多个推理链,并使用pass@k指标来评估模型生成推理链的质量。结果表明,人工编写的推理链可以通过多样本提示和微调显著提升LLM的逻辑推理能力。此外,在P-FOLIO上微调Llama3-7B可以在其他三个领域外的逻辑推理数据集上将模型性能提高10%或更多。我们还进行了详细的分析,以揭示最强大的LLM在推理方面的不足之处。数据集和代码将公开发布。
🔬 方法详解
问题定义:现有方法在评估LLM的逻辑推理能力时,主要依赖于二元蕴含分类或合成生成的推理过程,这些方法无法充分反映LLM在处理复杂、真实的逻辑推理问题时的能力。痛点在于缺乏高质量、多样化的人工标注推理链,难以对LLM的推理过程进行细粒度的评估和改进。
核心思路:本文的核心思路是构建一个高质量的人工标注数据集P-FOLIO,其中包含多样且复杂的逻辑推理链,这些推理链基于现实场景,并由人工逐步构建。通过使用P-FOLIO,可以更准确地评估LLM的推理能力,并通过多样本提示和微调来提升LLM的推理性能。这样设计的目的是为了弥补现有方法在评估和提升LLM逻辑推理能力方面的不足。
技术框架:整体框架包括数据收集、模型评估和模型改进三个主要阶段。数据收集阶段,通过精心设计的标注协议,收集高质量的人工标注推理链。模型评估阶段,使用P-FOLIO对LLM进行细粒度的推理规则分类评估,并使用pass@k指标评估模型生成推理链的质量。模型改进阶段,利用P-FOLIO进行多样本提示和微调,以提升LLM的逻辑推理能力。
关键创新:最重要的技术创新点在于P-FOLIO数据集的构建和使用。P-FOLIO提供了比以往工作更丰富、更复杂的推理链,以及更细粒度的推理规则分类。与现有方法相比,P-FOLIO提供了一个更真实、更全面的评估LLM逻辑推理能力的平台。此外,利用P-FOLIO进行微调可以显著提升LLM在领域外数据集上的性能,表明了P-FOLIO的泛化能力。
关键设计:P-FOLIO的标注协议是关键设计之一,它指导标注者逐步构建结构良好的自然语言证明。在模型评估方面,使用了pass@k指标来评估模型生成推理链的质量,考虑到模型可能生成与人工标注不同的推理路径。在模型改进方面,采用了多样本提示和微调策略,以充分利用P-FOLIO中的人工标注推理链。具体的参数设置和损失函数等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片


📊 实验亮点
在P-FOLIO上微调Llama3-7B可以在三个领域外的逻辑推理数据集上将模型性能提高10%或更多。实验结果表明,人工编写的推理链可以通过多样本提示和微调显著提升LLM的逻辑推理能力。P-FOLIO数据集的构建和使用为LLM的逻辑推理能力评估和提升提供了一个新的有效途径。
🎯 应用场景
该研究成果可广泛应用于需要逻辑推理能力的自然语言处理任务中,例如问答系统、对话系统、信息抽取和知识图谱推理等。通过提升LLM的逻辑推理能力,可以提高这些应用在处理复杂问题时的准确性和可靠性,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Existing methods on understanding the capabilities of LLMs in logical reasoning rely on binary entailment classification or synthetically derived rationales, which are not sufficient for proper investigation of model's capabilities. We present P-FOLIO, a human-annotated dataset consisting of diverse and complex reasoning chains for a set of realistic logical reasoning stories also written by humans. P-FOLIO is collected with an annotation protocol that facilitates humans to annotate well-structured natural language proofs for first-order logic reasoning problems in a step-by-step manner. The number of reasoning steps in P-FOLIO span from 0 to 20. We further use P-FOLIO to evaluate and improve large-language-model (LLM) reasoning capabilities. We evaluate LLM reasoning capabilities at a fine granularity via single-step inference rule classification, with more diverse inference rules of more diverse and higher levels of complexities than previous works. Given that a single model-generated reasoning chain could take a completely different path than the human-annotated one, we sample multiple reasoning chains from a model and use pass@k metrics for evaluating the quality of model-generated reasoning chains. We show that human-written reasoning chains significantly boost the logical reasoning capabilities of LLMs via many-shot prompting and fine-tuning. Furthermore, fine-tuning Llama3-7B on P-FOLIO improves the model performance by 10% or more on three other out-of-domain logical reasoning datasets. We also conduct detailed analysis to show where most powerful LLMs fall short in reasoning. We will release the dataset and code publicly.