Multi-Agent Actor-Critics in Autonomous Cyber Defense
作者: Mingjun Wang, Remington Dechene
分类: cs.CR, cs.AI, cs.MA
发布日期: 2024-10-11
备注: 6 pages. 2 figures
💡 一句话要点
提出基于多智能体Actor-Critic的自主网络防御方法,提升网络安全策略的智能化水平。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 网络防御 Actor-Critic算法 自主网络操作 网络安全 深度强化学习 网络威胁
📋 核心要点
- 现有网络防御机制难以适应快速变化的网络威胁,需要更智能和自主的防御方法。
- 利用多智能体Actor-Critic算法,通过智能体间的协作,实现对网络威胁的检测、缓解和响应。
- 实验表明,该方法能显著提升自主网络防御系统的能力,为更智能的网络安全策略奠定基础。
📝 摘要(中文)
在快速演进的网络威胁态势下,对自主和自适应防御机制的需求变得至关重要。多智能体深度强化学习(MADRL)为增强自主网络操作的有效性和弹性提供了一种有前景的方法。本文探讨了多智能体Actor-Critic算法在网络防御中的应用,该算法为多智能体学习提供了一种通用形式,利用多个智能体之间的协作交互来检测、缓解和响应网络威胁。我们证明了在模拟的网络攻击场景中,每个智能体都能够使用MADRL快速学习并自主地对抗威胁。结果表明,MADRL可以显著提高自主网络防御系统的能力,为更智能的网络安全策略铺平道路。这项研究为利用人工智能进行网络安全的知识体系做出了贡献,并为自主网络操作的未来研究和发展提供了启示。
🔬 方法详解
问题定义:论文旨在解决传统网络防御系统在面对日益复杂和快速演变的网络威胁时,缺乏足够的自主性和适应性的问题。现有方法往往依赖于人工干预或预定义的规则,难以有效应对新型或未知的攻击模式,导致防御效率低下和响应滞后。
核心思路:论文的核心思路是利用多智能体深度强化学习(MADRL)框架,将网络防御过程建模为多个智能体之间的协作博弈。每个智能体负责监控和防御网络中的特定区域或功能,通过学习与其他智能体的交互策略,共同实现对整个网络的有效保护。Actor-Critic算法被用作每个智能体的学习算法,使其能够根据环境反馈不断优化自身的防御策略。
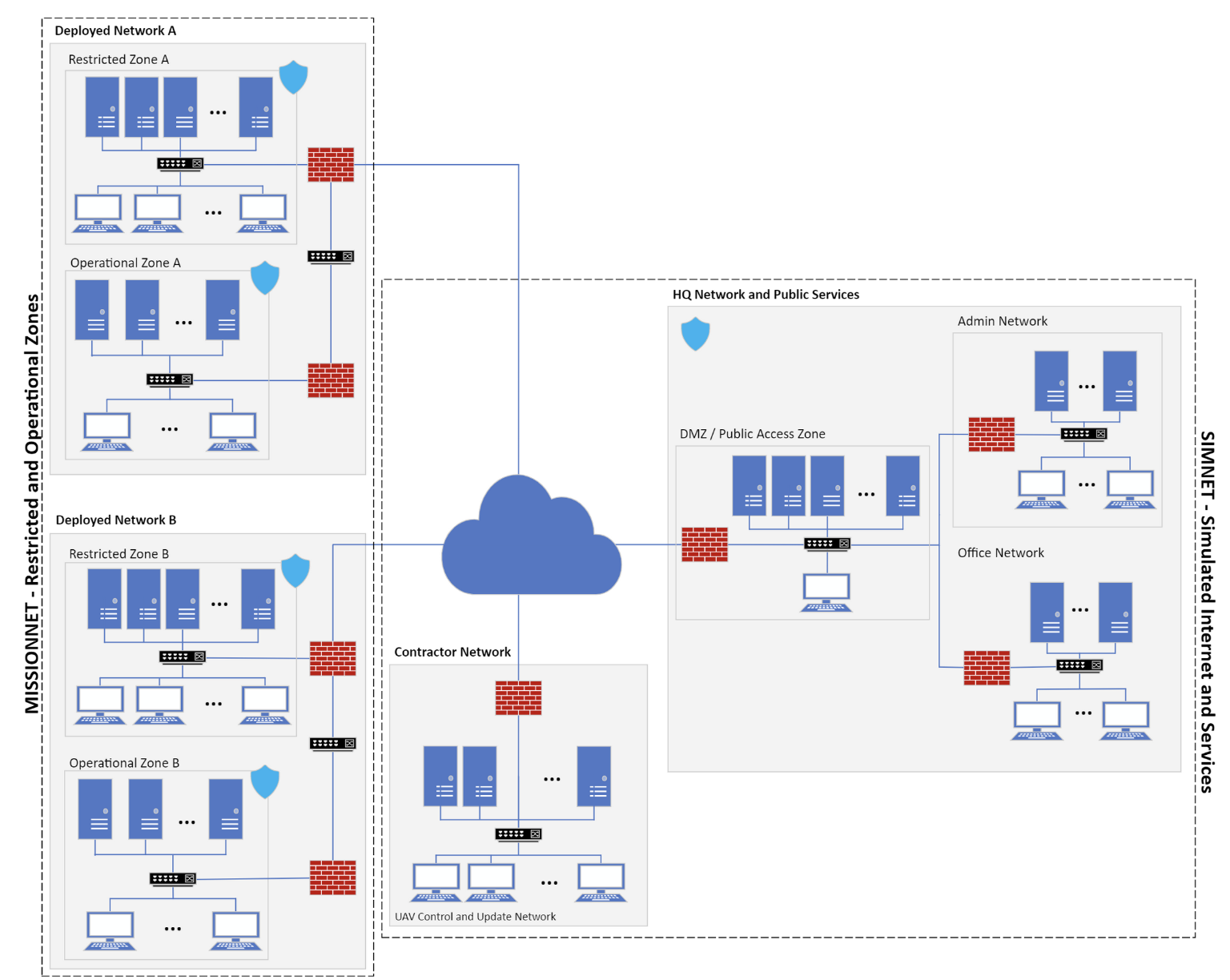
技术框架:该方法的技术框架主要包括以下几个部分:1) 网络环境建模:将网络环境抽象为可观测的状态空间,包括网络流量、系统日志、安全警报等信息。2) 智能体设计:定义每个智能体的行为空间,包括各种防御动作,如隔离受感染主机、更新防火墙规则、执行漏洞扫描等。3) Actor-Critic算法:使用Actor网络学习最优策略,Critic网络评估策略的价值。4) 奖励函数设计:设计合适的奖励函数,鼓励智能体采取有效的防御措施,惩罚不当行为。5) 多智能体协作:通过共享信息或协调行动,实现智能体之间的协作,共同应对复杂的网络威胁。
关键创新:该方法最重要的技术创新点在于将多智能体学习应用于网络防御领域,实现了智能体之间的自主协作和策略演化。与传统的单智能体方法相比,多智能体方法能够更好地应对复杂和动态的网络环境,提高防御系统的鲁棒性和适应性。此外,Actor-Critic算法的使用使得智能体能够有效地学习复杂的防御策略,并在实践中不断优化。
关键设计:论文中关键的设计包括:1) 状态空间的设计,需要充分考虑网络环境的特征,选择能够反映网络安全状态的关键指标。2) 行为空间的设计,需要涵盖各种有效的防御动作,并考虑动作的成本和风险。3) 奖励函数的设计,需要平衡防御效果和资源消耗,避免智能体采取过于激进或保守的策略。4) Actor和Critic网络的结构设计,需要根据状态空间和行为空间的维度进行调整,并选择合适的激活函数和优化算法。
🖼️ 关键图片
📊 实验亮点
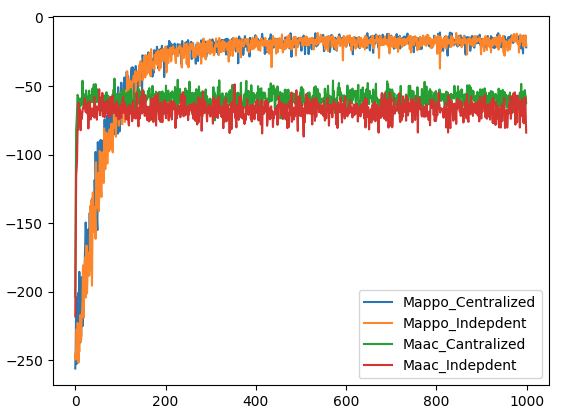
论文通过模拟网络攻击场景,验证了MADRL在自主网络防御中的有效性。实验结果表明,与传统的防御方法相比,基于MADRL的防御系统能够更快地检测和响应网络威胁,显著降低攻击成功率和损失。具体性能数据未知,但结果表明MADRL能够提升自主网络防御系统的能力。
🎯 应用场景
该研究成果可应用于构建自主网络防御系统,提升企业、政府和关键基础设施的网络安全防护能力。通过部署多智能体防御系统,可以实现对网络威胁的实时检测、自动响应和持续优化,降低人工干预的需求,提高防御效率和效果。此外,该方法还可以用于网络安全态势感知、威胁情报分析和漏洞挖掘等领域,为网络安全研究和实践提供新的思路和工具。
📄 摘要(原文)
The need for autonomous and adaptive defense mechanisms has become paramount in the rapidly evolving landscape of cyber threats. Multi-Agent Deep Reinforcement Learning (MADRL) presents a promising approach to enhancing the efficacy and resilience of autonomous cyber operations. This paper explores the application of Multi-Agent Actor-Critic algorithms which provides a general form in Multi-Agent learning to cyber defense, leveraging the collaborative interactions among multiple agents to detect, mitigate, and respond to cyber threats. We demonstrate each agent is able to learn quickly and counter act on the threats autonomously using MADRL in simulated cyber-attack scenarios. The results indicate that MADRL can significantly enhance the capability of autonomous cyber defense systems, paving the way for more intelligent cybersecurity strategies. This study contributes to the growing body of knowledge on leveraging artificial intelligence for cybersecurity and sheds light for future research and development in autonomous cyber operations.