Words as Beacons: Guiding RL Agents with High-Level Language Prompts
作者: Unai Ruiz-Gonzalez, Alain Andres, Pedro G. Bascoy, Javier Del Ser
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-10-11
💡 一句话要点
提出基于LLM引导的强化学习框架,解决稀疏奖励环境下的探索难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 稀疏奖励 探索策略 课程学习
📋 核心要点
- 稀疏奖励环境下的强化学习面临探索难题,传统方法效率低下或无法完成学习。
- 利用LLM理解环境并生成子目标,构建师生框架引导智能体学习,加速探索。
- 实验表明,该方法在MiniGrid环境中显著加速学习,收敛速度提升高达200倍。
📝 摘要(中文)
本文提出了一种师生强化学习框架,利用大型语言模型(LLM)作为“教师”,通过将复杂任务分解为子目标来指导智能体的学习过程,从而解决强化学习中稀疏奖励环境带来的探索挑战。LLM基于对环境结构和目的的文本描述的理解能力,可以提供类似于人类的子目标。论文提出了三种类型的子目标:相对于智能体的位置目标、对象表示和基于语言的指令,这些指令直接由LLM生成。更重要的是,论文证明了仅在训练阶段查询LLM是可行的,从而使智能体无需任何LLM干预即可在环境中运行。通过在MiniGrid基准测试的各种程序生成环境中,评估了三个最先进的开源LLM(Llama、DeepSeek、Qwen)来生成子目标,从而评估了该框架的性能。实验结果表明,与最近为稀疏奖励环境设计的基线相比,这种基于课程的方法加速了学习并增强了复杂任务中的探索,在训练步骤中实现了高达30到200倍的更快收敛。
🔬 方法详解
问题定义:在强化学习中,稀疏奖励环境是一个重大挑战。智能体很难获得有意义的奖励信号,导致探索效率低下,难以学习到最优策略。现有的探索方法,如基于好奇心的探索或分层强化学习,在复杂环境中仍然面临挑战,需要大量的试错才能找到有效的策略。
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大理解和推理能力,将复杂的任务分解为一系列更易于实现的子目标。LLM可以根据环境的文本描述,生成有意义的子目标,引导智能体逐步完成任务。这种方法类似于人类导师指导学生,通过提供明确的步骤和目标来加速学习过程。
技术框架:该框架是一个师生强化学习架构。首先,LLM作为“教师”,根据环境描述生成子目标。这些子目标可以是位置目标、对象表示或语言指令。然后,强化学习智能体作为“学生”,根据LLM提供的子目标进行学习。在训练过程中,LLM只在开始时被查询,生成一系列子目标。智能体在没有LLM干预的情况下,逐步完成这些子目标。训练完成后,智能体可以直接在环境中运行,无需依赖LLM。
关键创新:该方法最重要的创新点在于利用LLM的语义理解能力来指导强化学习智能体的探索。与传统的探索方法相比,LLM可以提供更具指导性和语义信息的子目标,从而显著提高探索效率。此外,该方法只在训练阶段使用LLM,避免了在推理阶段对LLM的依赖,降低了计算成本。
关键设计:论文提出了三种类型的子目标:位置目标(相对于智能体的位置坐标)、对象表示(环境中的物体描述)和语言指令(例如“走到红色的方块”)。LLM通过prompt工程生成这些子目标。强化学习智能体使用标准的强化学习算法(例如PPO)进行训练,奖励函数根据智能体是否成功完成子目标进行设计。具体的参数设置和网络结构在论文中有详细描述,但此处未知。
🖼️ 关键图片

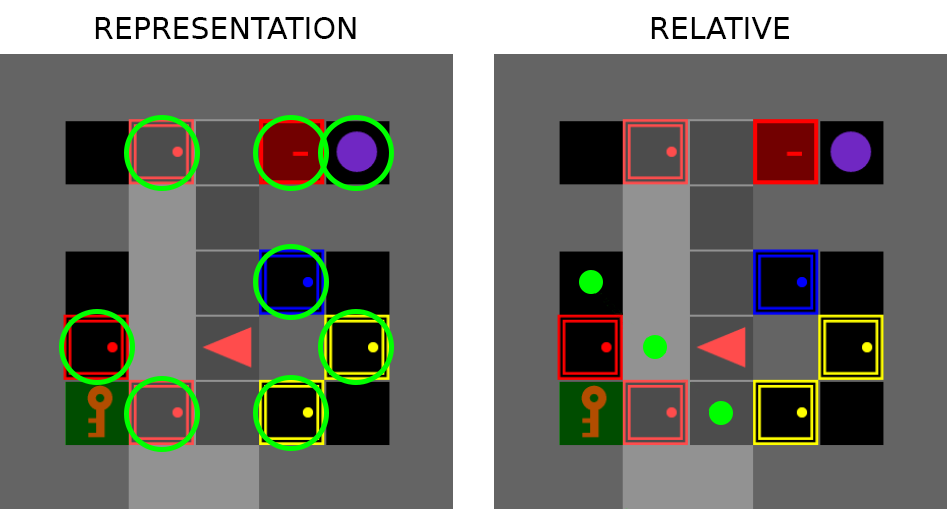
📊 实验亮点
实验结果表明,该方法在MiniGrid环境中显著加速了强化学习的训练过程。与现有的基线方法相比,该方法在训练步骤中实现了高达30到200倍的更快收敛速度。此外,该方法在不同的LLM(Llama、DeepSeek、Qwen)和不同的环境设置下都表现出良好的性能,证明了该方法的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等领域。通过利用LLM的知识和推理能力,可以帮助智能体在复杂和未知的环境中更快地学习和适应,从而提高智能体的自主性和智能化水平。未来,该方法可以扩展到更复杂的任务和环境,例如家庭服务机器人、工业自动化等。
📄 摘要(原文)
Sparse reward environments in reinforcement learning (RL) pose significant challenges for exploration, often leading to inefficient or incomplete learning processes. To tackle this issue, this work proposes a teacher-student RL framework that leverages Large Language Models (LLMs) as "teachers" to guide the agent's learning process by decomposing complex tasks into subgoals. Due to their inherent capability to understand RL environments based on a textual description of structure and purpose, LLMs can provide subgoals to accomplish the task defined for the environment in a similar fashion to how a human would do. In doing so, three types of subgoals are proposed: positional targets relative to the agent, object representations, and language-based instructions generated directly by the LLM. More importantly, we show that it is possible to query the LLM only during the training phase, enabling agents to operate within the environment without any LLM intervention. We assess the performance of this proposed framework by evaluating three state-of-the-art open-source LLMs (Llama, DeepSeek, Qwen) eliciting subgoals across various procedurally generated environment of the MiniGrid benchmark. Experimental results demonstrate that this curriculum-based approach accelerates learning and enhances exploration in complex tasks, achieving up to 30 to 200 times faster convergence in training steps compared to recent baselines designed for sparse reward environments.