Baichuan-Omni Technical Report
作者: Yadong Li, Haoze Sun, Mingan Lin, Tianpeng Li, Guosheng Dong, Tao Zhang, Bowen Ding, Wei Song, Zhenglin Cheng, Yuqi Huo, Song Chen, Xu Li, Da Pan, Shusen Zhang, Xin Wu, Zheng Liang, Jun Liu, Tao Zhang, Keer Lu, Yaqi Zhao, Yanjun Shen, Fan Yang, Kaicheng Yu, Tao Lin, Jianhua Xu, Zenan Zhou, Weipeng Chen
分类: cs.AI, cs.CL, cs.CV
发布日期: 2024-10-11 (更新: 2024-12-27)
💡 一句话要点
开源7B多模态大语言模型Baichuan-Omni,支持图文音视频并发处理与交互
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 开源模型 多模态对齐 多任务学习 音视频处理 图像理解
📋 核心要点
- GPT-4o展现了强大的多模态能力,但在开源领域缺乏高性能的同类模型,限制了其在实际应用中的普及。
- Baichuan-Omni通过多模态对齐和多任务微调,使7B语言模型具备了处理图像、视频、音频和文本数据的能力。
- 实验结果表明,Baichuan-Omni在多个多模态基准测试中表现出色,为开源社区提供了一个强大的多模态基线模型。
📝 摘要(中文)
本文介绍了Baichuan-Omni,首个开源的7B多模态大语言模型(MLLM),它能够同时处理和分析图像、视频、音频和文本等多种模态的数据,并提供先进的多模态交互体验和强大的性能。该模型采用了一种有效的多模态训练方案,从7B模型开始,经过多模态对齐和跨音频、图像、视频和文本模态的多任务微调两个阶段。这种方法使语言模型能够有效地处理视觉和音频数据。Baichuan-Omni在各种全模态和多模态基准测试中表现出强大的性能,旨在为开源社区在推进多模态理解和实时交互方面提供一个有竞争力的基线。
🔬 方法详解
问题定义:现有的大型多模态模型,如GPT-4o,虽然性能强大,但缺乏开源实现,限制了研究人员和开发者在其基础上进行创新和应用。因此,需要一个高性能的开源多模态大语言模型,以促进多模态理解和交互技术的发展。
核心思路:Baichuan-Omni的核心思路是利用一个相对较小的7B语言模型作为基础,通过多模态对齐和多任务微调,使其具备处理和理解多种模态数据的能力。这种方法旨在以较低的计算成本,实现与更大模型相媲美的性能。
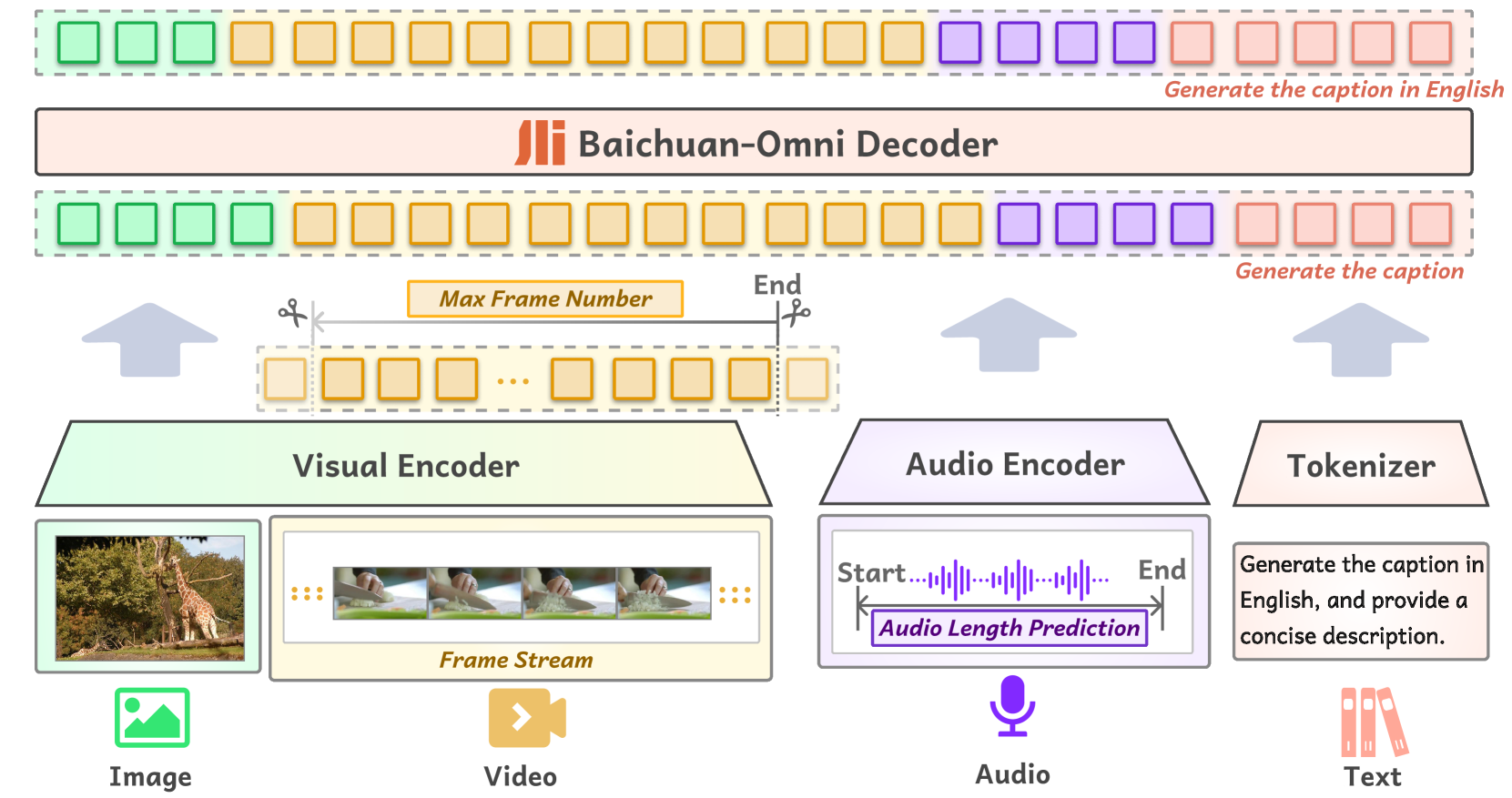
技术框架:Baichuan-Omni的训练框架主要包括两个阶段:1) 多模态对齐:将图像、视频和音频等模态的数据映射到语言模型的语义空间中,使模型能够理解不同模态的信息。2) 多任务微调:在多个多模态任务上对模型进行微调,使其具备跨模态理解和推理能力。模型输入包括图像、视频、音频和文本,输出为文本。
关键创新:Baichuan-Omni的关键创新在于其高效的多模态训练方案,该方案能够在相对较小的模型上实现强大的多模态能力。通过精心设计的多模态对齐和多任务微调策略,模型能够有效地学习不同模态之间的关联,并进行跨模态推理。
关键设计:在多模态对齐阶段,采用了对比学习的方法,将不同模态的数据映射到统一的语义空间中。在多任务微调阶段,使用了多种多模态数据集,并设计了相应的损失函数,以优化模型在不同任务上的性能。具体的网络结构和参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
Baichuan-Omni在多个全模态和多模态基准测试中表现出强大的性能,证明了其在多模态理解和交互方面的能力。虽然论文中没有给出具体的性能数据和对比基线,但强调了其作为开源社区的竞争基线的潜力。具体的性能提升幅度未知。
🎯 应用场景
Baichuan-Omni可应用于智能助手、多媒体内容分析、跨模态信息检索、教育娱乐等领域。例如,它可以用于创建能够理解用户语音指令并结合图像信息的智能家居系统,或者用于分析视频内容并自动生成摘要。该模型的开源特性将促进多模态技术的广泛应用和创新。
📄 摘要(原文)
The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.