GIVE: Structured Reasoning of Large Language Models with Knowledge Graph Inspired Veracity Extrapolation
作者: Jiashu He, Mingyu Derek Ma, Jinxuan Fan, Dan Roth, Wei Wang, Alejandro Ribeiro
分类: cs.AI, cs.CL
发布日期: 2024-10-11 (更新: 2025-05-29)
💡 一句话要点
GIVE:一种知识图谱启发的LLM结构化推理方法,通过真实验证外推提升性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识图谱 推理 真实验证 外推 提示工程 Agent系统
📋 核心要点
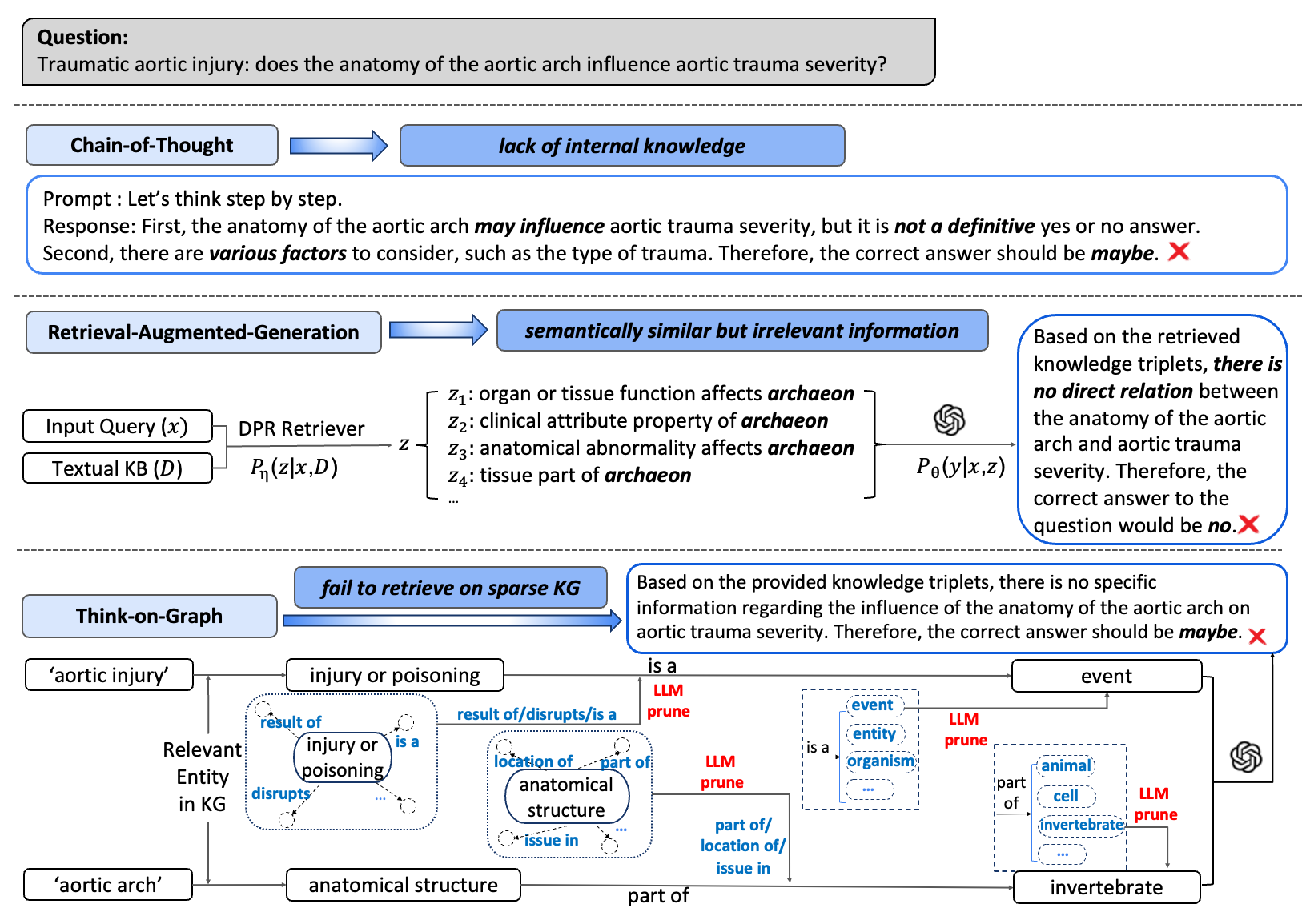
- 现有基于上下文提示或强化学习的方法依赖LLM的内部知识,难以解决复杂问题,且Agent系统需要全面的知识库,成本高昂。
- GIVE方法融合参数记忆和非参数记忆,引导LLM智能体进行观察、反思和表达,从而实现更准确的推理。
- 实验表明,GIVE能显著提升各种规模LLM的性能,甚至使较小模型在科学任务中超越大型模型,且无需训练。
📝 摘要(中文)
本文提出了一种名为图谱启发真实验证外推(GIVE)的全新推理方法,它融合了参数记忆和非参数记忆,以最小的外部输入提高准确推理能力。GIVE引导LLM智能体选择最相关的专家数据(观察),进行特定于查询的发散性思维(反思),然后综合这些信息以产生最终输出(表达)。大量实验表明,GIVE可以提升各种规模LLM的性能,在某些情况下,GIVE使较小的LLM在科学任务中超越了更大、更复杂的LLM(GPT3.5T + GIVE > GPT4)。GIVE在科学和开放领域评估中均有效。GIVE是一种免训练方法,使LLM能够处理超出其训练数据的新问题(准确率从43.5%提高到88.2%)。GIVE允许LLM智能体使用受限(非常小)和噪声(非常大)的知识源进行推理,适应节点数量从135到超过840k的知识图谱。GIVE中涉及的推理过程是完全可解释的。
🔬 方法详解
问题定义:现有基于上下文提示或强化学习的方法,在提升大型语言模型(LLM)的推理能力时,依赖于LLM的内部知识来生成可靠的思维链(CoT)。然而,无论LLM的规模如何,某些问题无法通过单次前向传递解决。同时,基于Agent的推理系统需要访问全面的非参数知识库,这在科学和利基领域通常成本高昂或不可行。因此,需要一种方法,能够结合LLM的参数知识和外部知识,以更低的成本和更高的效率解决复杂推理问题。
核心思路:GIVE的核心思路是融合参数记忆(LLM自身知识)和非参数记忆(外部知识图谱),通过模仿人类专家解决问题的过程,即观察(选择相关知识)、反思(发散性思考)和表达(综合信息输出),来提升LLM的推理能力。这种方法旨在利用LLM的泛化能力和知识图谱的结构化知识,从而在无需大量训练的情况下,提高推理的准确性和可解释性。
技术框架:GIVE的技术框架主要包含三个阶段:观察(Observe)、反思(Reflect)和表达(Speak)。在观察阶段,GIVE引导LLM智能体从知识图谱中选择与当前查询最相关的专家数据。在反思阶段,LLM智能体基于所选知识进行特定于查询的发散性思维,生成多种可能的推理路径。在表达阶段,LLM智能体综合观察和反思阶段的信息,生成最终的输出。整个过程通过提示工程(Prompt Engineering)实现,无需对LLM进行额外的训练。
关键创新:GIVE的关键创新在于其融合参数记忆和非参数记忆的推理方式,以及模仿人类专家解决问题过程的框架。与传统的依赖LLM自身知识或完全依赖外部知识库的方法不同,GIVE能够充分利用LLM的泛化能力和知识图谱的结构化知识,从而在无需大量训练的情况下,提高推理的准确性和可解释性。此外,GIVE的框架具有良好的可扩展性,可以适应不同规模和类型的知识图谱。
关键设计:GIVE的关键设计包括:1) 如何选择最相关的专家数据:这涉及到设计有效的提示,引导LLM智能体从知识图谱中选择与当前查询最相关的节点和关系。2) 如何进行特定于查询的发散性思维:这涉及到设计合适的提示,引导LLM智能体基于所选知识生成多种可能的推理路径。3) 如何综合观察和反思阶段的信息:这涉及到设计合适的提示,引导LLM智能体将观察到的知识和反思的推理路径进行综合,生成最终的输出。论文中没有明确提及损失函数或网络结构等技术细节,因为GIVE是一种免训练的方法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GIVE能够显著提升各种规模LLM的性能。在某些情况下,GIVE使较小的LLM在科学任务中超越了更大、更复杂的LLM(GPT3.5T + GIVE > GPT4)。GIVE在科学和开放领域评估中均有效。GIVE是一种免训练方法,使LLM能够处理超出其训练数据的新问题(准确率从43.5%提高到88.2%)。GIVE允许LLM智能体使用受限(非常小)和噪声(非常大)的知识源进行推理,适应节点数量从135到超过840k的知识图谱。
🎯 应用场景
GIVE方法具有广泛的应用前景,可以应用于科学研究、智能问答、决策支持等领域。例如,在科学研究中,GIVE可以帮助研究人员从海量文献和数据中提取关键信息,进行科学假设的验证和新发现的探索。在智能问答中,GIVE可以提高问答系统的准确性和可解释性,为用户提供更可靠的答案。在决策支持中,GIVE可以帮助决策者综合各种信息,进行更明智的决策。
📄 摘要(原文)
Existing approaches based on context prompting or reinforcement learning (RL) to improve the reasoning capacities of large language models (LLMs) depend on the LLMs' internal knowledge to produce reliable Chain-Of-Thought (CoT). However, no matter the size of LLMs, certain problems cannot be resolved in a single forward pass. Meanwhile, agent-based reasoning systems require access to a comprehensive nonparametric knowledge base, which is often costly or not feasible for use in scientific and niche domains. We present Graph Inspired Veracity Extrapolation (GIVE), a novel reasoning method that merges parametric and non-parametric memories to improve accurate reasoning with minimal external input. GIVE guides the LLM agent to select the most pertinent expert data (observe), engage in query-specific divergent thinking (reflect), and then synthesize this information to produce the final output (speak). Extensive experiments demonstrated the following benefits of our framework: (1) GIVE boosts the performance of LLMs across various sizes. (2) In some scenarios, GIVE allows smaller LLMs to surpass larger, more sophisticated ones in scientific tasks (GPT3.5T + GIVE > GPT4). (3) GIVE is effective on scientific and open-domain assessments. (4) GIVE is a training-free method that enables LLMs to tackle new problems that extend beyond their training data (up to 43.5% -> 88.2%} accuracy improvement). (5) GIVE allows LLM agents to reason using both restricted (very small) and noisy (very large) knowledge sources, accommodating knowledge graphs (KG) ranging from 135 to more than 840k nodes. (6) The reasoning process involved in GIVE is fully interpretable.