Large Legislative Models: Towards Efficient AI Policymaking in Economic Simulations
作者: Henry Gasztowtt, Benjamin Smith, Vincent Zhu, Qinxun Bai, Edwin Zhang
分类: cs.AI
发布日期: 2024-10-10
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于LLM的经济政策制定模型,提升社会复杂MARL场景效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 经济政策制定 多智能体强化学习 样本效率 社会模拟
📋 核心要点
- 现有基于强化学习的经济政策制定方法样本效率低,难以灵活融入细致信息。
- 利用预训练大型语言模型作为政策制定者,提升在复杂社会环境下的决策效率。
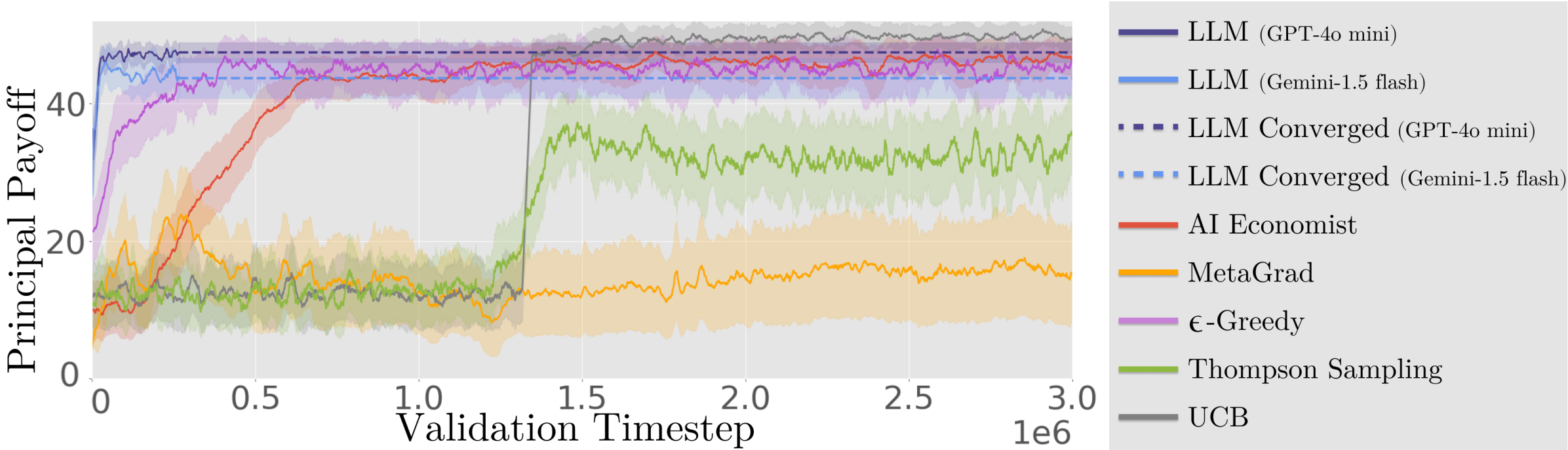
- 实验表明,该方法在多个环境中显著优于现有方法,实现了效率提升。
📝 摘要(中文)
经济政策制定的改进为社会带来广泛利益,激发了AI驱动的政策制定工具的研究。AI政策制定有潜力通过大规模快速处理数据来超越人类表现。然而,现有的基于强化学习(RL)的方法存在样本效率低下的问题,并且在将细致信息灵活地融入决策过程方面受到限制。因此,我们提出了一种新方法,利用预训练的大型语言模型(LLM)作为社会复杂多智能体强化学习(MARL)场景中具有样本效率的政策制定者。我们证明了显著的效率提升,在三个环境中优于现有方法。我们的代码可在https://github.com/hegasz/large-legislative-models获取。
🔬 方法详解
问题定义:论文旨在解决经济政策制定中,传统强化学习方法样本效率低,且难以灵活整合复杂信息的问题。现有方法在处理社会复杂的多智能体环境时,需要大量的训练样本才能达到较好的性能,并且难以将一些细粒度的社会、经济信息融入到决策过程中,限制了其应用范围。
核心思路:论文的核心思路是利用预训练的大型语言模型(LLM)的强大泛化能力和知识储备,将其作为经济政策的制定者。LLM在大量文本数据上进行预训练,学习到了丰富的世界知识和推理能力,可以直接用于指导政策制定,从而避免了从零开始训练强化学习模型的需要,提高了样本效率。
技术框架:该方法的技术框架主要包含以下几个部分:首先,构建一个社会经济模拟环境,该环境包含多个智能体,每个智能体代表一个经济实体。然后,将预训练的LLM作为政策制定者,LLM接收来自环境的状态信息,并输出相应的政策指令。最后,通过强化学习的方式对LLM进行微调,使其更好地适应特定的经济环境。整个流程可以看作是利用LLM进行策略初始化,然后通过强化学习进行策略优化。
关键创新:该论文最重要的技术创新点在于将大型语言模型引入到经济政策制定领域,并将其作为强化学习的策略网络。与传统的强化学习方法相比,该方法具有更高的样本效率和更好的泛化能力。此外,该方法还可以方便地将一些外部知识融入到政策制定过程中,例如,可以通过prompt engineering的方式引导LLM制定更加合理的政策。
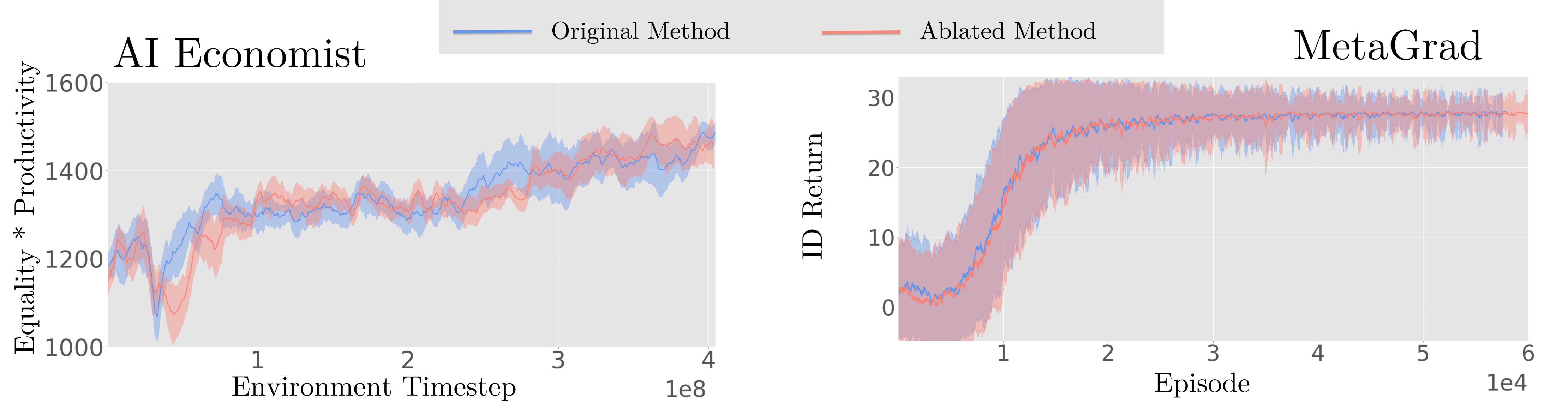
关键设计:在具体实现上,论文可能采用了以下关键设计:1) 使用特定的prompt engineering技巧,引导LLM生成符合要求的政策指令。2) 设计合适的奖励函数,用于指导LLM的微调过程。3) 探索不同的LLM架构和参数设置,以获得最佳的性能。4) 采用一些正则化技术,防止LLM在微调过程中出现过拟合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在三个不同的经济模拟环境中均优于现有的强化学习方法,实现了显著的效率提升。具体的性能数据和提升幅度在论文中进行了详细的展示。这些结果表明,利用大型语言模型进行经济政策制定具有巨大的潜力。
🎯 应用场景
该研究成果可应用于各种经济政策模拟和制定场景,例如税收政策、贸易政策、产业政策等。通过AI驱动的政策制定,可以更高效地评估政策效果,优化资源配置,促进经济发展。未来,该技术有望应用于更广泛的社会治理领域,例如公共卫生、环境保护等。
📄 摘要(原文)
The improvement of economic policymaking presents an opportunity for broad societal benefit, a notion that has inspired research towards AI-driven policymaking tools. AI policymaking holds the potential to surpass human performance through the ability to process data quickly at scale. However, existing RL-based methods exhibit sample inefficiency, and are further limited by an inability to flexibly incorporate nuanced information into their decision-making processes. Thus, we propose a novel method in which we instead utilize pre-trained Large Language Models (LLMs), as sample-efficient policymakers in socially complex multi-agent reinforcement learning (MARL) scenarios. We demonstrate significant efficiency gains, outperforming existing methods across three environments. Our code is available at https://github.com/hegasz/large-legislative-models.