Can LLMs plan paths with extra hints from solvers?
作者: Erik Wu, Sayan Mitra
分类: cs.AI, cs.CL, cs.RO
发布日期: 2024-10-07
💡 一句话要点
利用求解器提示增强LLM在机器人路径规划中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 路径规划 机器人 求解器反馈 微调 高阶推理 规划策略
📋 核心要点
- LLM在长期规划和高阶推理方面存在局限性,难以有效解决复杂的机器人路径规划问题。
- 该研究提出利用求解器生成的反馈(包括视觉反馈)来指导和提升LLM在路径规划任务中的性能。
- 实验结果表明,该方法能有效提升LLM解决中等难度问题的能力,并分析了不同提示策略的影响。
📝 摘要(中文)
大型语言模型(LLM)在自然语言处理、数学问题求解和程序合成等任务中表现出卓越的能力。然而,它们在长期规划和高阶推理方面的有效性受到限制且较为脆弱。本文探索了一种通过整合求解器生成的反馈来增强LLM在解决经典机器人规划任务中的性能的方法。我们探索了四种不同的反馈提供策略,包括视觉反馈,并利用微调来提升性能。我们评估了三种不同的LLM在10个标准和100个随机生成的规划问题上的性能。结果表明,求解器生成的反馈提高了LLM解决中等难度问题的能力,但更难的问题仍然无法解决。该研究详细分析了不同提示策略和不同LLM规划倾向的影响。
🔬 方法详解
问题定义:论文旨在解决LLM在机器人路径规划任务中表现出的局限性。现有的LLM在处理需要长期规划和高阶推理的问题时,容易出错且缺乏鲁棒性。特别是在复杂的路径规划场景中,LLM难以生成有效的解决方案。
核心思路:论文的核心思路是利用外部求解器提供的反馈信息来指导LLM的规划过程。通过将求解器的输出作为提示,帮助LLM更好地理解环境、目标和约束条件,从而提高规划的准确性和效率。这种方法结合了LLM的语言理解能力和求解器的精确计算能力。
技术框架:整体框架包括以下几个主要阶段:1) 使用LLM生成初始路径规划方案;2) 利用外部求解器对该方案进行评估,并生成反馈信息;3) 将反馈信息以不同的形式(例如,文本、图像)提供给LLM;4) LLM基于反馈信息调整其规划方案;5) 重复步骤2-4,直到找到满足要求的路径或达到最大迭代次数。
关键创新:该研究的关键创新在于将求解器的反馈信息有效地融入到LLM的规划过程中。与传统的端到端LLM规划方法相比,该方法能够利用外部知识来纠正LLM的错误,并引导其朝着正确的方向前进。此外,论文还探索了多种反馈形式,并分析了它们对LLM性能的影响。
关键设计:论文探索了四种不同的反馈策略,包括文本反馈和视觉反馈。文本反馈可能包含关于当前路径的成本、可行性等信息。视觉反馈可能包含路径的可视化表示,例如,显示路径中的碰撞或不平滑区域。论文还使用了微调技术来优化LLM对反馈信息的利用。具体的参数设置和网络结构细节未在摘要中提及,属于未知信息。
🖼️ 关键图片
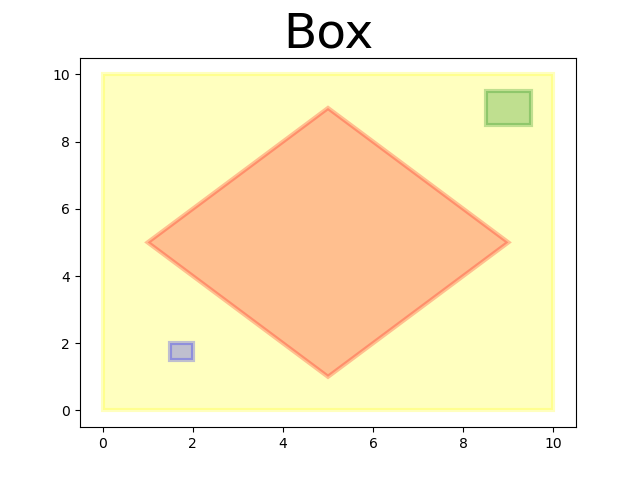

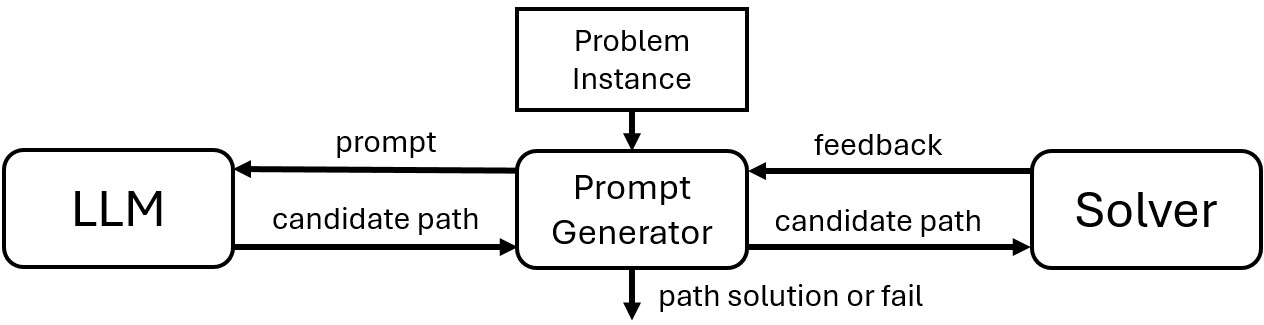
📊 实验亮点
实验结果表明,求解器生成的反馈能够显著提高LLM解决中等难度路径规划问题的能力。虽然更难的问题仍然具有挑战性,但该研究为提升LLM在复杂规划任务中的性能提供了一种有效的途径。论文详细分析了不同提示策略和不同LLM的规划倾向,为后续研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域。通过结合LLM的推理能力和求解器的精确计算,可以实现更智能、更可靠的路径规划。未来,该方法有望扩展到更复杂的规划任务,例如多智能体协作、资源分配等。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable capabilities in natural language processing, mathematical problem solving, and tasks related to program synthesis. However, their effectiveness in long-term planning and higher-order reasoning has been noted to be limited and fragile. This paper explores an approach for enhancing LLM performance in solving a classical robotic planning task by integrating solver-generated feedback. We explore four different strategies for providing feedback, including visual feedback, we utilize fine-tuning, and we evaluate the performance of three different LLMs across a 10 standard and 100 more randomly generated planning problems. Our results suggest that the solver-generated feedback improves the LLM's ability to solve the moderately difficult problems, but the harder problems still remain out of reach. The study provides detailed analysis of the effects of the different hinting strategies and the different planning tendencies of the evaluated LLMs.