Semantic Environment Atlas for Object-Goal Navigation
作者: Nuri Kim, Jeongho Park, Mineui Hong, Songhwai Oh
分类: cs.AI, cs.RO
发布日期: 2024-10-05
备注: 30 pages
期刊: Knowledge-Based Systems, Volume 304, 25 November 2024, 112446
DOI: 10.1016/j.knosys.2024.112446
💡 一句话要点
提出语义环境地图集(SEA),增强具身智能体在对象目标导航中的视觉导航能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 语义地图 视觉导航 对象目标导航 具身智能体 环境理解
📋 核心要点
- 现有视觉导航方法在复杂环境中难以有效利用语义信息,导致定位精度和导航效率受限。
- SEA通过构建语义图地图,显式地建模地点和物体之间的关系,从而增强导航上下文理解。
- 实验表明,SEA在视觉定位和对象目标导航任务中均取得了显著提升,尤其是在噪声环境下。
📝 摘要(中文)
本文介绍了一种新颖的地图构建方法——语义环境地图集(SEA),旨在提升具身智能体的视觉导航能力。SEA利用语义图地图,精细地描绘了地点和物体之间的关系,从而丰富了导航上下文。这些地图由图像观测构建,并将视觉地标作为环境中的稀疏编码节点捕获。SEA集成了来自多个环境的语义地图,保留了地点-物体关系的记忆,这对于视觉定位和导航等任务非常有价值。我们开发了有效利用SEA的导航框架,并通过视觉定位和对象目标导航任务对这些框架进行了评估。基于SEA的定位框架显著优于现有方法,能够从单个查询图像中准确识别位置。在Habitat场景中的实验结果表明,我们的方法不仅实现了39.0%的成功率,比当前最先进水平提高了12.4%,而且在嘈杂的里程计和驱动条件下保持了鲁棒性,同时保持了较低的计算成本。
🔬 方法详解
问题定义:现有基于视觉的导航方法,尤其是在对象目标导航任务中,常常面临环境理解不足的问题。它们难以有效地利用环境中的语义信息,例如物体之间的关系和物体与地点的关联,导致定位精度下降,导航路径规划效率降低,尤其是在环境存在噪声的情况下,鲁棒性较差。
核心思路:本文的核心思路是构建一个语义环境地图集(SEA),该地图集能够显式地表示地点和物体之间的关系。通过将环境表示为语义图,智能体可以更好地理解环境的结构和语义信息,从而提高定位和导航的准确性和效率。SEA通过整合多个环境的语义地图,实现知识的迁移和泛化。
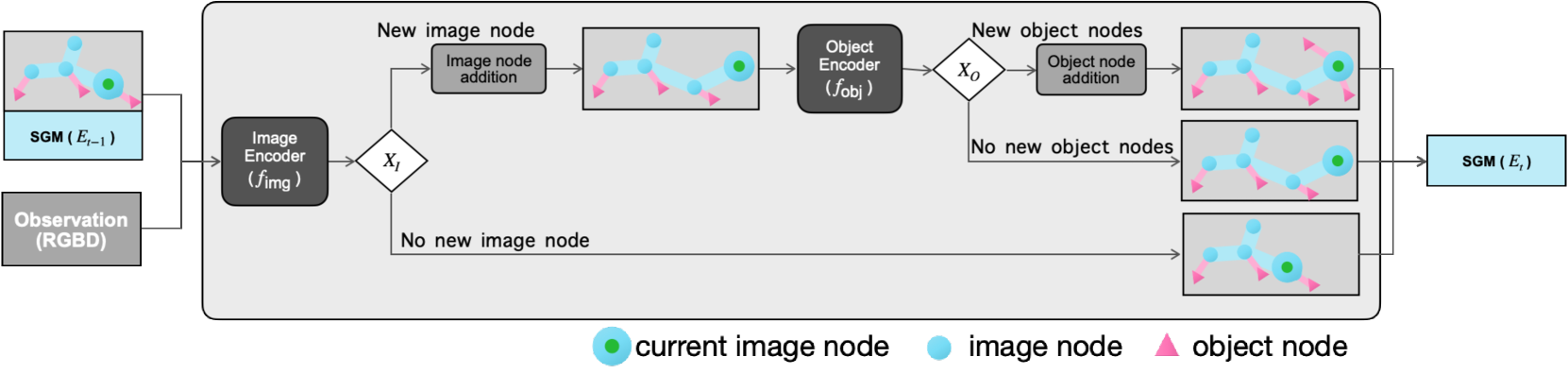
技术框架:SEA的构建和应用主要包含以下几个阶段:1) 图像观测:智能体通过视觉传感器获取环境图像。2) 语义地图构建:从图像中提取视觉地标和语义信息,构建局部语义地图,表示地点和物体之间的关系。3) 地图集成:将多个局部语义地图集成到SEA中,形成全局的语义环境表示。4) 视觉定位:利用SEA进行视觉定位,确定智能体在环境中的位置。5) 对象目标导航:基于SEA规划导航路径,引导智能体到达目标物体。
关键创新:SEA的关键创新在于其语义图地图的表示方式,它不仅包含了视觉信息,还显式地建模了地点和物体之间的关系。这种表示方式使得智能体能够更好地理解环境的语义信息,从而提高定位和导航的性能。此外,SEA通过集成多个环境的语义地图,实现了知识的迁移和泛化,提高了智能体的适应性。
关键设计:SEA使用稀疏编码节点来表示视觉地标,降低了计算复杂度。在语义地图构建过程中,使用了[未知]方法来提取语义信息和建立地点-物体关系。在视觉定位过程中,使用了[未知]方法进行图像匹配和位置估计。损失函数的设计目标是最小化定位误差和导航路径长度。网络结构使用了[未知]结构,以实现高效的语义信息提取和地图构建。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于SEA的定位框架显著优于现有方法,能够从单个查询图像中准确识别位置。在Habitat场景中的对象目标导航任务中,该方法实现了39.0%的成功率,比当前最先进水平提高了12.4%。此外,该方法在嘈杂的里程计和驱动条件下保持了鲁棒性,同时保持了较低的计算成本。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。例如,在家庭服务机器人中,SEA可以帮助机器人更好地理解家居环境,从而更准确地完成清洁、物品搬运等任务。在自动驾驶领域,SEA可以提供更丰富的环境语义信息,提高自动驾驶系统的安全性和可靠性。在虚拟现实领域,SEA可以用于构建更逼真的虚拟环境,提升用户体验。
📄 摘要(原文)
In this paper, we introduce the Semantic Environment Atlas (SEA), a novel mapping approach designed to enhance visual navigation capabilities of embodied agents. The SEA utilizes semantic graph maps that intricately delineate the relationships between places and objects, thereby enriching the navigational context. These maps are constructed from image observations and capture visual landmarks as sparsely encoded nodes within the environment. The SEA integrates multiple semantic maps from various environments, retaining a memory of place-object relationships, which proves invaluable for tasks such as visual localization and navigation. We developed navigation frameworks that effectively leverage the SEA, and we evaluated these frameworks through visual localization and object-goal navigation tasks. Our SEA-based localization framework significantly outperforms existing methods, accurately identifying locations from single query images. Experimental results in Habitat scenarios show that our method not only achieves a success rate of 39.0%, an improvement of 12.4% over the current state-of-the-art, but also maintains robustness under noisy odometry and actuation conditions, all while keeping computational costs low.