Developing Assurance Cases for Adversarial Robustness and Regulatory Compliance in LLMs
作者: Tomas Bueno Momcilovic, Dian Balta, Beat Buesser, Giulio Zizzo, Mark Purcell
分类: cs.CR, cs.AI, cs.SE
发布日期: 2024-10-04
备注: Accepted to the ASSURE 2024 workshop
💡 一句话要点
提出LLM对抗鲁棒性保障框架,应对恶意攻击并满足法规遵从
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗鲁棒性 法规遵从 保障案例 动态风险管理
📋 核心要点
- 大型语言模型面临对抗攻击和法规遵从的双重挑战,现有方法难以有效应对LLM漏洞的快速演变。
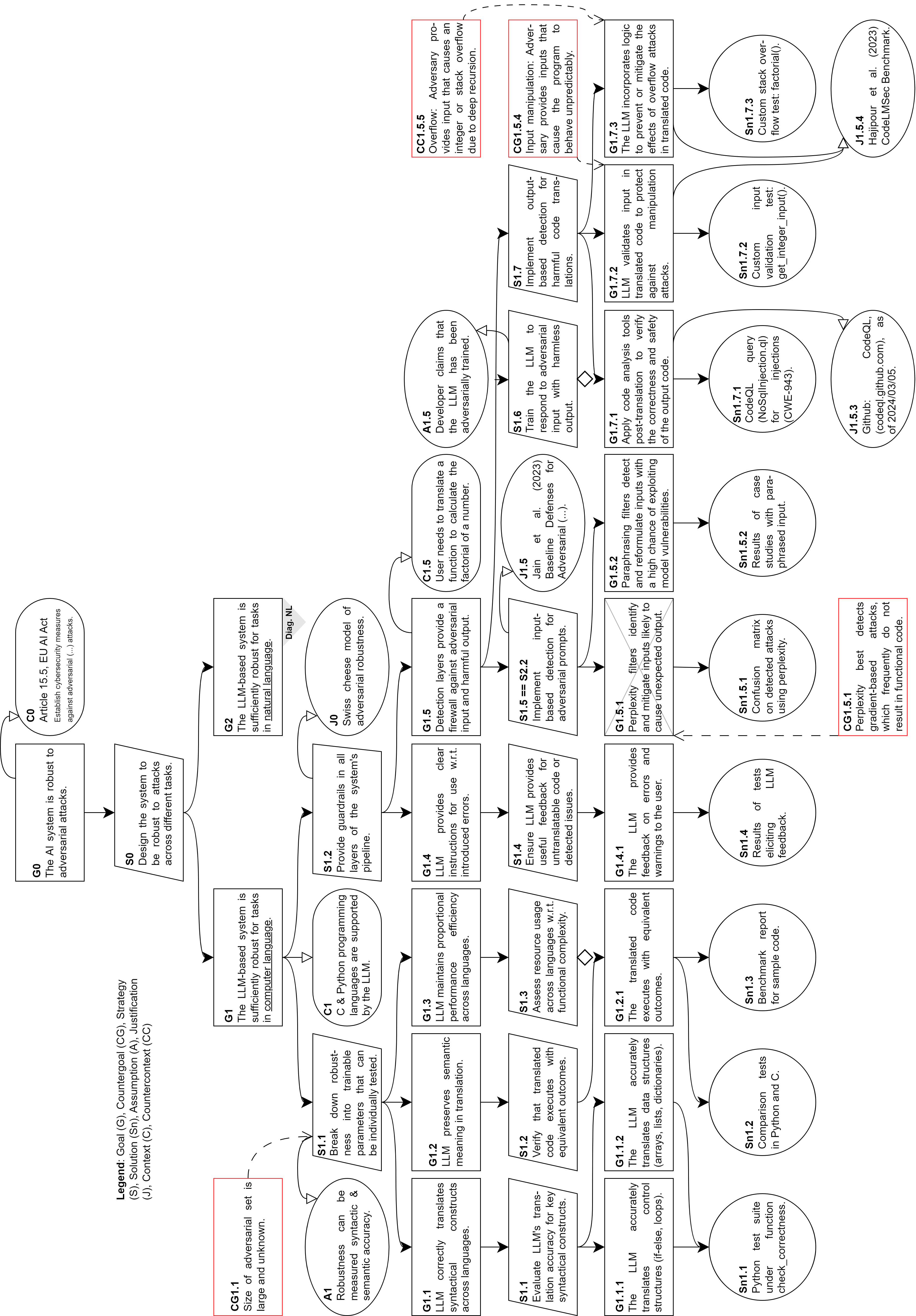
- 论文提出分层保障框架,在LLM部署各阶段设置防护措施,并引入元层进行动态风险管理和推理。
- 通过两个示例保障案例展示该方法,强调针对不同应用场景定制策略的重要性,以确保LLM的鲁棒性和合规性。
📝 摘要(中文)
本文提出了一种针对大型语言模型(LLM)对抗鲁棒性和法规遵从性的保障案例开发方法。通过关注自然语言和代码语言任务,我们探讨了这些模型面临的漏洞,包括基于越狱、启发式方法和随机化的对抗攻击。我们提出了一个分层框架,在LLM部署的各个阶段整合了防护措施,旨在缓解这些攻击并确保符合欧盟AI法案。我们的方法包括一个用于动态风险管理和推理的元层,这对于解决LLM漏洞的演变性质至关重要。我们用两个示例保障案例来说明我们的方法,强调了不同的上下文需要量身定制的策略,以确保鲁棒且合规的AI系统。
🔬 方法详解
问题定义:大型语言模型(LLM)在实际部署中面临着日益严峻的安全风险,包括对抗性攻击(如越狱攻击)和违反法规(如欧盟AI法案)的风险。现有的防御方法往往难以跟上对抗攻击的快速演变,缺乏动态风险管理能力,并且难以针对不同的应用场景进行定制。
核心思路:本文的核心思路是构建一个分层的保障框架,该框架不仅包含静态的防护措施,还引入了动态的风险管理和推理机制。通过在LLM部署的各个阶段设置防护措施,并利用元层进行动态监控和调整,可以有效地应对不断变化的对抗攻击,并确保LLM的合规性。
技术框架:该框架包含多个层次,具体包括:1) LLM本身;2) 部署在LLM周围的防护层,用于检测和阻止已知的攻击模式;3) 元层,用于动态监控LLM的性能和风险,并根据需要调整防护策略。元层能够进行风险评估、策略选择和执行,从而实现动态的风险管理。
关键创新:该方法最重要的创新点在于引入了元层进行动态风险管理和推理。传统的防御方法往往是静态的,无法适应对抗攻击的快速演变。而元层能够根据LLM的实际表现和风险状况,动态地调整防护策略,从而提高LLM的鲁棒性和安全性。此外,该框架强调针对不同的应用场景定制保障策略,从而更好地满足实际需求。
关键设计:元层的设计是关键。它需要能够收集LLM的性能数据、检测潜在的攻击模式、评估风险,并根据评估结果选择合适的防护策略。具体的实现方式可能包括使用机器学习模型进行异常检测、使用规则引擎进行策略选择等。此外,保障案例的设计也至关重要,需要根据具体的应用场景和风险状况,制定详细的保障目标、策略和证据。
🖼️ 关键图片


📊 实验亮点
论文通过两个示例保障案例展示了该方法的有效性。虽然具体的性能数据未在摘要中给出,但强调了针对不同上下文定制策略的重要性,表明该框架具有良好的适应性和可扩展性。元层的引入为动态风险管理提供了可能,是提升LLM对抗鲁棒性的关键。
🎯 应用场景
该研究成果可广泛应用于需要高安全性和合规性的LLM部署场景,例如金融、医疗、法律等领域。通过该框架,可以有效降低LLM被恶意利用的风险,并确保其符合相关法规要求,从而促进LLM在各行业的安全可靠应用。未来,该方法有望进一步扩展到其他类型的AI系统,提升整体的AI安全水平。
📄 摘要(原文)
This paper presents an approach to developing assurance cases for adversarial robustness and regulatory compliance in large language models (LLMs). Focusing on both natural and code language tasks, we explore the vulnerabilities these models face, including adversarial attacks based on jailbreaking, heuristics, and randomization. We propose a layered framework incorporating guardrails at various stages of LLM deployment, aimed at mitigating these attacks and ensuring compliance with the EU AI Act. Our approach includes a meta-layer for dynamic risk management and reasoning, crucial for addressing the evolving nature of LLM vulnerabilities. We illustrate our method with two exemplary assurance cases, highlighting how different contexts demand tailored strategies to ensure robust and compliant AI systems.