DOTS: Learning to Reason Dynamically in LLMs via Optimal Reasoning Trajectories Search
作者: Murong Yue, Wenlin Yao, Haitao Mi, Dian Yu, Ziyu Yao, Dong Yu
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-10-04 (更新: 2025-08-07)
备注: Accepted to ICLR 2025
💡 一句话要点
DOTS:通过最优推理轨迹搜索,使LLM具备动态推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 动态推理 推理轨迹搜索 指令调优 自适应推理
📋 核心要点
- 现有方法对所有问题采用静态推理策略,忽略了问题特性和LLM自身能力。
- DOTS通过搜索最优推理轨迹,使LLM能够根据问题动态调整推理过程。
- 实验表明,DOTS在多个推理任务上超越了静态推理方法和指令微调。
📝 摘要(中文)
近年来,提升大型语言模型(LLM)的推理能力备受关注。以往研究表明,各种提示策略(称为“推理动作”)有助于LLM进行推理,例如逐步思考、回答前反思、使用程序求解以及它们的组合。然而,这些方法通常对所有问题应用静态的、预定义的推理动作,而没有考虑每个问题的具体特征或任务求解LLM的能力。本文提出了DOTS,一种通过最优推理轨迹搜索,使LLM能够动态推理的方法,该方法针对每个问题的具体特征和任务求解LLM的固有能力量身定制。我们的方法包括三个关键步骤:i)定义可以组合成各种推理动作轨迹的原子推理动作模块;ii)通过迭代探索和评估,为每个训练问题搜索特定任务求解LLM的最优动作轨迹;iii)使用收集到的最优轨迹来训练LLM,以规划未见问题的推理轨迹。特别地,我们提出了两种学习范式,即微调外部LLM作为规划器来指导任务求解LLM,或者直接微调任务求解LLM,使其具有内在的推理动作规划能力。我们在八个推理任务上的实验表明,我们的方法始终优于静态推理技术和原始指令调优方法。进一步的分析表明,我们的方法使LLM能够根据问题的复杂性调整其计算,为更难的问题分配更深入的思考和推理。
🔬 方法详解
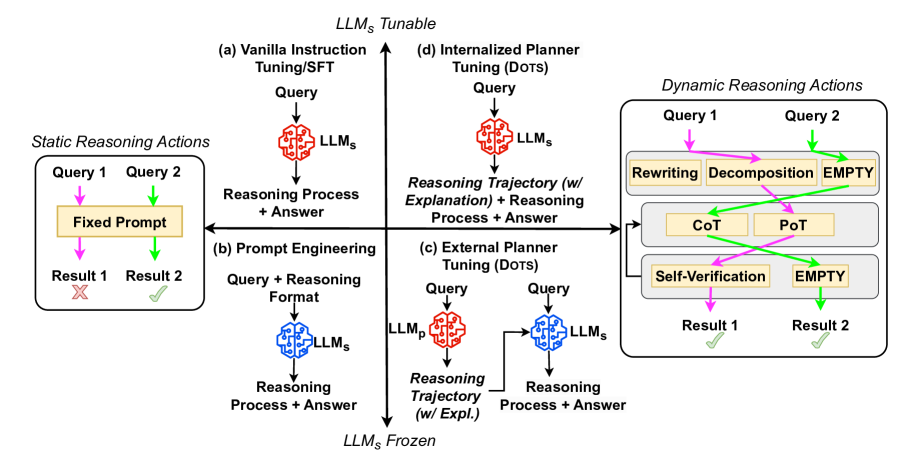
问题定义:论文旨在解决大型语言模型在推理过程中缺乏动态性和自适应性的问题。现有方法通常采用预定义的、静态的推理策略,无法根据不同问题的复杂度和LLM自身的能力进行调整,导致推理效率和准确性受限。
核心思路:论文的核心思路是通过搜索最优的推理轨迹,使LLM能够根据问题的特性动态地选择和组合不同的推理动作。这种方法允许LLM针对不同的问题采用不同的推理策略,从而提高推理的效率和准确性。
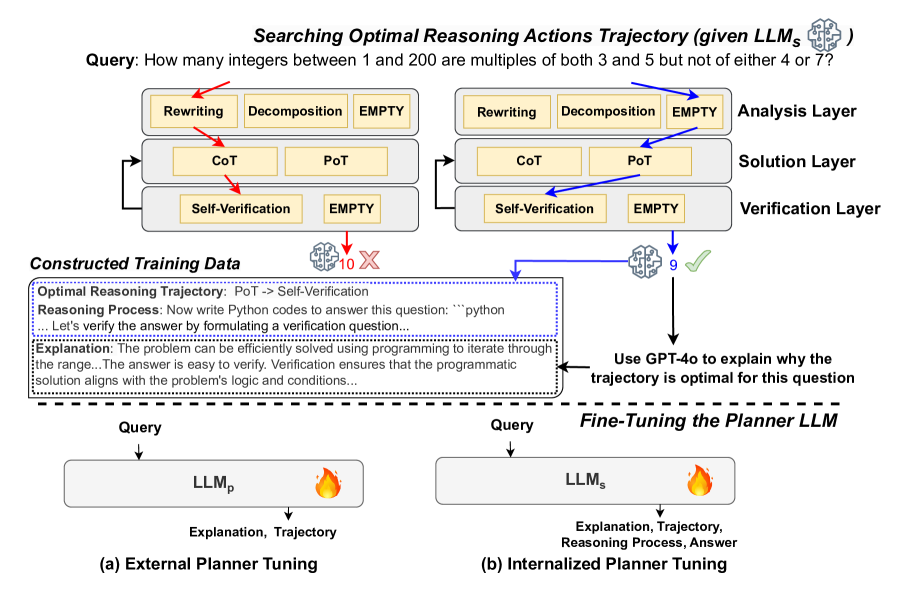
技术框架:DOTS包含三个主要步骤:1) 定义原子推理动作模块,这些模块可以组合成不同的推理轨迹;2) 针对每个训练问题,通过迭代探索和评估,搜索最优的推理轨迹;3) 使用收集到的最优轨迹训练LLM,使其能够规划未见问题的推理轨迹。论文提出了两种训练范式:一种是微调外部LLM作为规划器,指导任务求解LLM;另一种是直接微调任务求解LLM,使其具备内在的推理动作规划能力。
关键创新:DOTS的关键创新在于引入了动态推理轨迹搜索的概念,使LLM能够根据问题的特性自适应地选择推理策略。与现有方法相比,DOTS不再依赖于预定义的、静态的推理策略,而是通过搜索最优的推理轨迹,实现更高效和准确的推理。
关键设计:论文的关键设计包括:1) 原子推理动作模块的定义,这些模块需要足够灵活和通用,以便能够组合成各种不同的推理轨迹;2) 推理轨迹搜索算法的设计,该算法需要在搜索效率和搜索质量之间进行权衡;3) LLM的训练方法,包括如何利用收集到的最优轨迹来训练LLM,使其能够规划未见问题的推理轨迹。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DOTS在八个推理任务上 consistently 优于静态推理技术和原始指令调优方法。具体而言,DOTS能够根据问题的复杂性调整计算资源,为更难的问题分配更多的思考和推理时间。这表明DOTS能够有效地提高LLM的推理能力和效率。
🎯 应用场景
DOTS方法可应用于各种需要复杂推理的场景,如问答系统、智能助手、代码生成等。通过使LLM具备动态推理能力,可以显著提高这些应用在处理复杂问题时的性能和用户体验。未来,该方法有望推动LLM在更广泛领域的应用,例如科学研究、金融分析等。
📄 摘要(原文)
Enhancing the capability of large language models (LLMs) in reasoning has gained significant attention in recent years. Previous studies have demonstrated the effectiveness of various prompting strategies in aiding LLMs in reasoning (called "reasoning actions"), such as step-by-step thinking, reflecting before answering, solving with programs, and their combinations. However, these approaches often applied static, predefined reasoning actions uniformly to all questions, without considering the specific characteristics of each question or the capability of the task-solving LLM. In this paper, we propose DOTS, an approach enabling LLMs to reason dynamically via optimal reasoning trajectory search, tailored to the specific characteristics of each question and the inherent capability of the task-solving LLM. Our approach involves three key steps: i) defining atomic reasoning action modules that can be composed into various reasoning action trajectories; ii) searching for the optimal action trajectory for each training question through iterative exploration and evaluation for the specific task-solving LLM; and iii) using the collected optimal trajectories to train an LLM to plan for the reasoning trajectories of unseen questions. In particular, we propose two learning paradigms, i.e., fine-tuning an external LLM as a planner to guide the task-solving LLM, or directly fine-tuning the task-solving LLM with an internalized capability for reasoning actions planning. Our experiments across eight reasoning tasks show that our method consistently outperforms static reasoning techniques and the vanilla instruction tuning approach. Further analysis reveals that our method enables LLMs to adjust their computation based on problem complexity, allocating deeper thinking and reasoning to harder problems.