TICKing All the Boxes: Generated Checklists Improve LLM Evaluation and Generation
作者: Jonathan Cook, Tim Rocktäschel, Jakob Foerster, Dennis Aumiller, Alex Wang
分类: cs.AI, cs.CL, cs.HC, cs.LG
发布日期: 2024-10-04
💡 一句话要点
TICK:通过生成式检查清单改进LLM评估与生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 指令遵循 检查清单生成 自动化评估 自我完善
📋 核心要点
- 现有LLM评估方法依赖人工或LLM直接评分,缺乏可解释性,且人工成本高昂,LLM评分可靠性不足。
- TICK方法利用LLM生成指令相关的检查清单,将复杂指令分解为一系列可验证的YES/NO问题,结构化评估过程。
- 实验表明,TICK显著提升了LLM评估与人类偏好的一致性,并能通过自我完善和Best-of-N选择提高LLM生成质量。
📝 摘要(中文)
鉴于大型语言模型(LLM)的广泛应用,对其指令遵循能力进行灵活且可解释的评估至关重要。尽管偏好判断已成为事实上的评估标准,但它将复杂、多方面的偏好提炼为单一排名。此外,由于人工标注速度慢且成本高昂,LLM越来越多地被用于做出这些判断,但牺牲了可靠性和可解释性。本文提出了TICK(Targeted Instruct-evaluation with ChecKlists),一种全自动、可解释的评估协议,它使用LLM生成的、特定于指令的检查清单来构建评估。我们首先表明,给定一条指令,LLM可以可靠地生成高质量、定制化的评估检查清单,将指令分解为一系列YES/NO问题。每个问题询问候选响应是否满足指令的特定要求。我们证明,与直接让LLM对输出进行评分相比,使用TICK可以显著提高LLM判断与人类偏好之间完全一致的频率(46.4% $\to$ 52.2%)。然后,我们展示了STICK(Self-TICK)可以通过自我完善和Best-of-N选择来提高多个基准测试中的生成质量。在LiveBench推理任务上进行STICK自我完善可带来+7.8%的绝对收益,而使用STICK进行Best-of-N选择可在真实世界的指令数据集WildBench上获得+6.3%的绝对改进。鉴于此,结构化的、多方面的自我改进被证明是进一步提升LLM能力的一种有希望的方式。最后,通过向负责直接评分LLM对WildBench指令的响应的人工评估员提供LLM生成的检查清单,我们显著提高了注释者间的一致性(0.194 $\to$ 0.256)。
🔬 方法详解
问题定义:现有LLM评估方法,如直接评分或偏好判断,难以解释模型决策过程,且依赖人工标注成本高昂。使用LLM进行自动评估时,其可靠性和与人类偏好的一致性存在问题。因此,需要一种自动化、可解释且与人类偏好对齐的LLM评估方法。
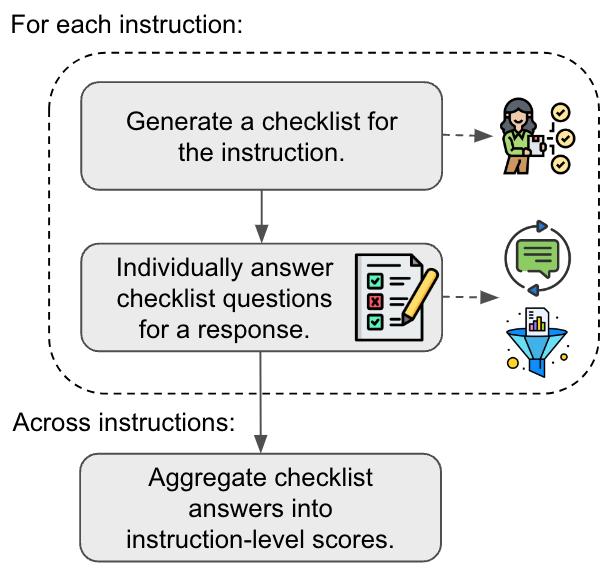
核心思路:核心思想是利用LLM的生成能力,针对特定指令生成一个详细的检查清单,将复杂的指令分解为一系列更小、更易于评估的子任务(YES/NO问题)。通过检查清单,可以更细粒度地评估LLM的响应,并提高评估的可解释性和准确性。这样设计的目的是为了模拟人类评估过程中的分解任务和逐步验证的思维模式。
技术框架:TICK包含以下主要阶段:1) 检查清单生成:给定一条指令,使用LLM生成一个包含多个YES/NO问题的检查清单,每个问题对应指令的一个特定要求。2) 响应评估:对于LLM生成的响应,使用检查清单中的问题逐一进行评估,判断响应是否满足每个要求。3) 综合评分:根据检查清单的评估结果,综合计算出一个总分,作为对响应质量的评估。STICK(Self-TICK)在此基础上增加了自我完善和Best-of-N选择的机制,用于提高LLM的生成质量。
关键创新:最重要的创新点在于利用LLM生成特定于指令的检查清单,将复杂的评估任务分解为一系列简单的YES/NO问题。与传统的直接评分方法相比,TICK提供了更细粒度的评估结果,提高了评估的可解释性和准确性。此外,STICK通过自我完善和Best-of-N选择,实现了LLM生成质量的显著提升。
关键设计:检查清单生成过程中,需要精心设计提示词,以确保LLM能够生成高质量、与指令相关的检查清单。在STICK中,自我完善过程通过迭代地使用检查清单评估和改进LLM的响应来实现。Best-of-N选择则通过生成多个候选响应,并使用检查清单选择最佳响应来提高生成质量。具体参数设置和损失函数信息未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用TICK可以显著提高LLM判断与人类偏好之间完全一致的频率(46.4% $\to$ 52.2%)。STICK在LiveBench推理任务上实现了+7.8%的绝对收益,在WildBench数据集上实现了+6.3%的绝对改进。此外,通过提供LLM生成的检查清单,人工评估员的注释者间一致性从0.194提高到0.256。
🎯 应用场景
该研究成果可应用于LLM的自动化评估、调试和优化。通过TICK,可以更高效、更可靠地评估LLM的指令遵循能力,并指导LLM的训练和改进。此外,该方法还可以用于提高人机协作的效率,例如,为人工评估员提供LLM生成的检查清单,以提高评估的一致性和准确性。
📄 摘要(原文)
Given the widespread adoption and usage of Large Language Models (LLMs), it is crucial to have flexible and interpretable evaluations of their instruction-following ability. Preference judgments between model outputs have become the de facto evaluation standard, despite distilling complex, multi-faceted preferences into a single ranking. Furthermore, as human annotation is slow and costly, LLMs are increasingly used to make these judgments, at the expense of reliability and interpretability. In this work, we propose TICK (Targeted Instruct-evaluation with ChecKlists), a fully automated, interpretable evaluation protocol that structures evaluations with LLM-generated, instruction-specific checklists. We first show that, given an instruction, LLMs can reliably produce high-quality, tailored evaluation checklists that decompose the instruction into a series of YES/NO questions. Each question asks whether a candidate response meets a specific requirement of the instruction. We demonstrate that using TICK leads to a significant increase (46.4% $\to$ 52.2%) in the frequency of exact agreements between LLM judgements and human preferences, as compared to having an LLM directly score an output. We then show that STICK (Self-TICK) can be used to improve generation quality across multiple benchmarks via self-refinement and Best-of-N selection. STICK self-refinement on LiveBench reasoning tasks leads to an absolute gain of $+$7.8%, whilst Best-of-N selection with STICK attains $+$6.3% absolute improvement on the real-world instruction dataset, WildBench. In light of this, structured, multi-faceted self-improvement is shown to be a promising way to further advance LLM capabilities. Finally, by providing LLM-generated checklists to human evaluators tasked with directly scoring LLM responses to WildBench instructions, we notably increase inter-annotator agreement (0.194 $\to$ 0.256).