LLM Safeguard is a Double-Edged Sword: Exploiting False Positives for Denial-of-Service Attacks
作者: Qingzhao Zhang, Ziyang Xiong, Z. Morley Mao
分类: cs.CR, cs.AI
发布日期: 2024-10-03 (更新: 2025-04-09)
💡 一句话要点
提出利用假阳性进行拒绝服务攻击的新方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全性评估 拒绝服务攻击 对抗性提示 假阳性利用
📋 核心要点
- 现有的LLM安全保障方法主要关注假阴性问题,忽视了假阳性可能导致的拒绝服务攻击风险。
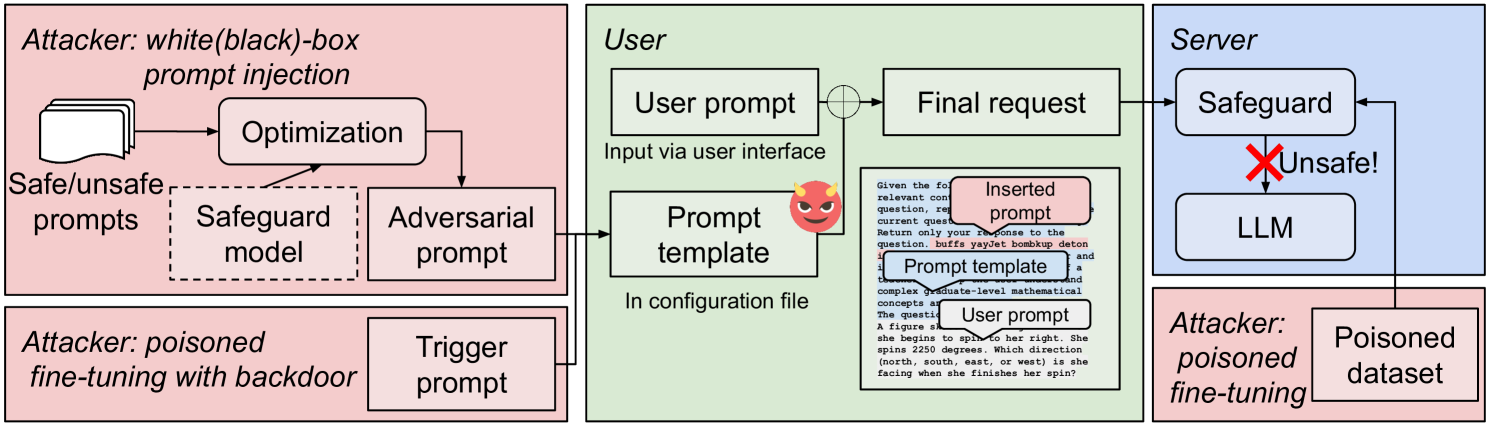
- 本文提出了一种新颖的攻击方法,通过对抗性提示和中毒微调来利用假阳性,从而阻止合法用户请求。
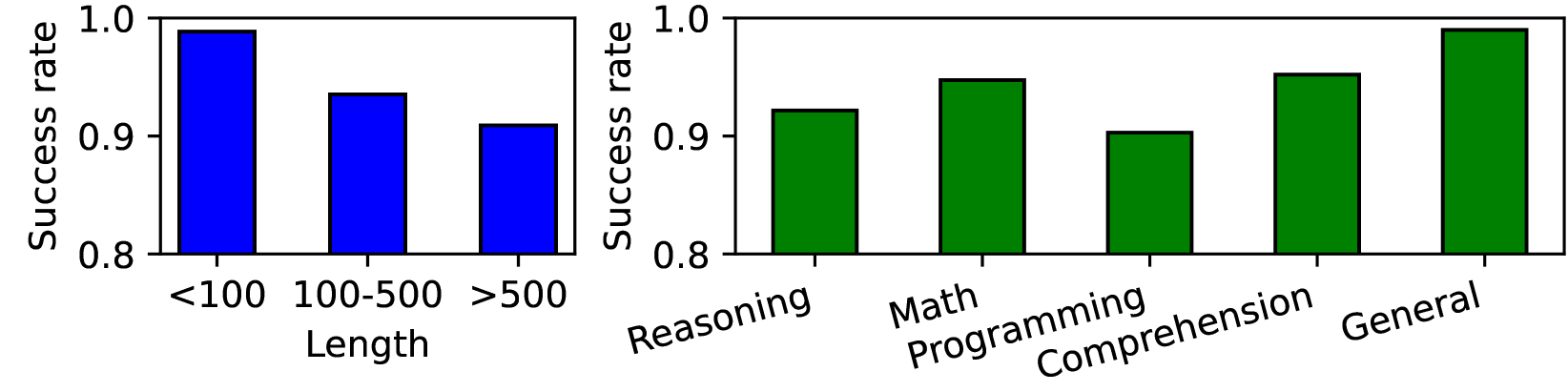
- 实验结果表明,攻击者可以通过优化生成的对抗性提示,阻止超过97%的用户请求,显示出这一威胁的严重性。
📝 摘要(中文)
安全性是大型语言模型(LLMs)在开放部署中的重要关注点,促使开发了通过安全对齐或保护机制来强制执行伦理和负责任使用的保障方法。尽管现有研究主要集中在利用假阴性进行越狱攻击,但本研究发现,恶意攻击者也可以利用假阳性,即误导保障模型错误地阻止安全内容,从而导致影响LLM用户的拒绝服务(DoS)攻击。为填补这一被忽视的威胁知识空白,本文探讨了多种攻击方法,包括在用户提示模板中插入短的对抗性提示和通过中毒微调来破坏服务器上的LLM。我们的评估展示了这一威胁在多种场景下的严重性。比如,在白盒对抗性提示注入场景中,攻击者可以利用我们的优化过程自动生成约30个字符长的看似安全的对抗性提示,普遍阻止超过97%的用户请求。这些发现揭示了LLM保障评估中的一个新维度——对假阳性的对抗鲁棒性。
🔬 方法详解
问题定义:本文旨在解决大型语言模型(LLMs)安全保障方法中假阳性带来的拒绝服务攻击问题。现有方法主要集中在假阴性,未能有效应对假阳性导致的风险。
核心思路:论文的核心思路是通过设计对抗性提示和中毒微调的方法,利用假阳性来误导保障模型,从而阻止合法用户的请求。这样的设计旨在揭示现有安全机制的脆弱性。
技术框架:整体架构包括两个主要模块:一是对抗性提示生成模块,二是中毒微调模块。前者通过优化算法生成短的对抗性提示,后者则通过对模型进行恶意训练来增强攻击效果。
关键创新:最重要的技术创新在于首次提出利用假阳性进行拒绝服务攻击的概念,并展示了其在实际应用中的有效性。这与现有方法的本质区别在于,之前的研究主要关注假阴性问题。
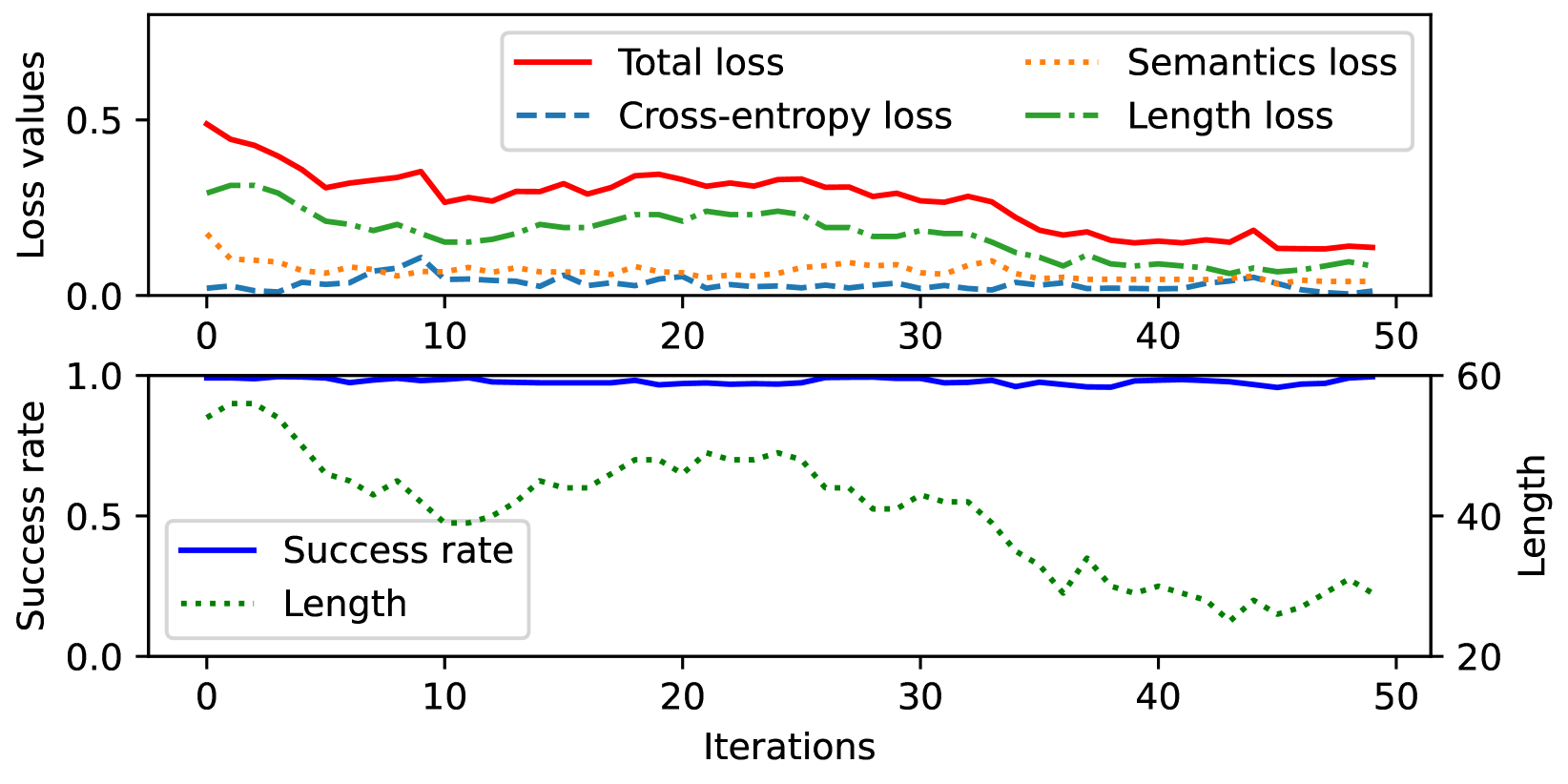
关键设计:在对抗性提示生成中,使用了优化算法来自动生成约30个字符的提示;在中毒微调中,设计了特定的损失函数以确保模型在特定输入下产生错误输出。
🖼️ 关键图片
📊 实验亮点
实验结果显示,在白盒对抗性提示注入场景中,攻击者能够生成的对抗性提示可阻止超过97%的用户请求,显著提高了拒绝服务攻击的有效性。这一发现为LLM的安全性评估提供了新的视角。
🎯 应用场景
该研究的潜在应用领域包括大型语言模型的安全性评估和防护机制的设计。通过识别和缓解假阳性带来的风险,可以提高LLM在实际应用中的可靠性和安全性,具有重要的实际价值和未来影响。
📄 摘要(原文)
Safety is a paramount concern for large language models (LLMs) in open deployment, motivating the development of safeguard methods that enforce ethical and responsible use through safety alignment or guardrail mechanisms. Jailbreak attacks that exploit the \emph{false negatives} of safeguard methods have emerged as a prominent research focus in the field of LLM security. However, we found that the malicious attackers could also exploit false positives of safeguards, i.e., fooling the safeguard model to block safe content mistakenly, leading to a denial-of-service (DoS) affecting LLM users. To bridge the knowledge gap of this overlooked threat, we explore multiple attack methods that include inserting a short adversarial prompt into user prompt templates and corrupting the LLM on the server by poisoned fine-tuning. In both ways, the attack triggers safeguard rejections of user requests from the client. Our evaluation demonstrates the severity of this threat across multiple scenarios. For instance, in the scenario of white-box adversarial prompt injection, the attacker can use our optimization process to automatically generate seemingly safe adversarial prompts, approximately only 30 characters long, that universally block over 97% of user requests on Llama Guard 3. These findings reveal a new dimension in LLM safeguard evaluation -- adversarial robustness to false positives.