The Role of Deductive and Inductive Reasoning in Large Language Models
作者: Chengkun Cai, Xu Zhao, Haoliang Liu, Zhongyu Jiang, Tianfang Zhang, Zongkai Wu, Jenq-Neng Hwang, Lei Li
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-10-03 (更新: 2025-07-07)
备注: 4 figures, accept at ACL2025 Main
💡 一句话要点
提出DID方法,通过动态融合演绎推理和归纳推理,提升大语言模型在复杂推理任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 演绎推理 归纳推理 复杂性评估 动态推理 认知科学
📋 核心要点
- 现有大语言模型在复杂推理任务中面临挑战,主要原因是其依赖静态提示结构,缺乏对复杂场景的适应性。
- DID方法通过动态整合演绎推理和归纳推理,并结合双重指标复杂性评估系统,使模型能自适应地调整推理路径。
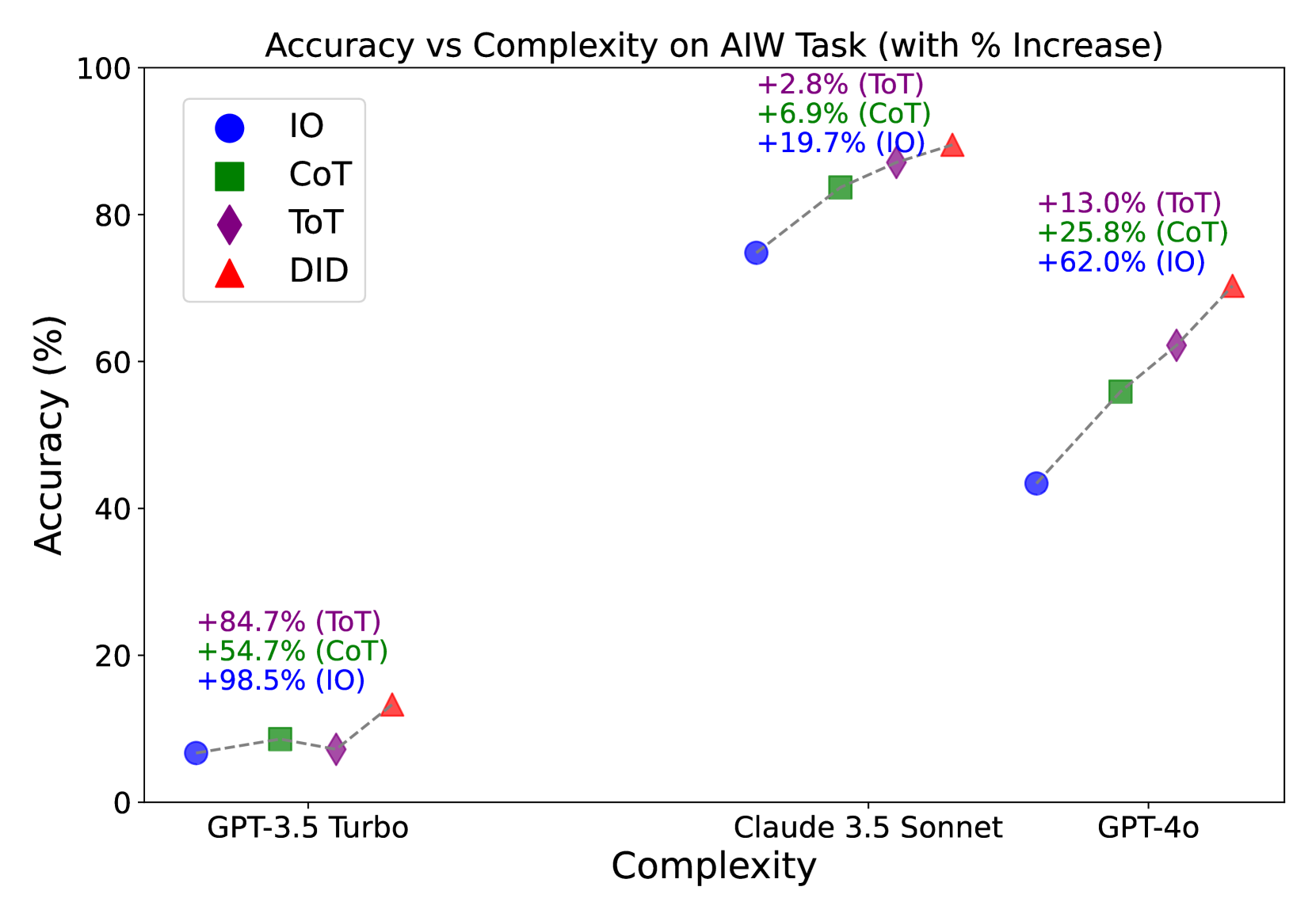
- 实验结果表明,DID方法在AIW等基准测试中显著提高了推理质量和准确性,同时保持了较低的计算成本。
📝 摘要(中文)
大型语言模型(LLMs)在推理任务中表现出令人印象深刻的能力,但它们对静态提示结构的依赖以及对复杂场景的有限适应性仍然是一个重大挑战。本文提出了演绎和归纳(DID)方法,这是一个新颖的框架,通过动态整合演绎和归纳推理方法来增强LLM推理。借鉴认知科学原理,DID实现了一个双重指标复杂性评估系统,该系统结合了Littlestone维度和信息熵,以精确评估任务难度并指导分解策略。DID使模型能够根据问题复杂性逐步调整其推理路径,从而反映人类的认知过程。我们在多个基准上评估了DID的有效性,包括AIW和MR-GSM8K,以及我们用于时间推理的自定义Holiday Puzzle数据集。我们的结果表明,推理质量和解决方案准确性得到了显著提高——在AIW上实现了70.3%的准确率(相比之下,思维树为62.2%),同时保持了较低的计算成本。DID在提高LLM性能的同时保持计算效率的成功,为开发更符合认知且更强大的语言模型提供了有希望的方向。我们的工作贡献了一种理论上扎实的、以输入为中心的方法来增强LLM推理能力,为传统的输出探索方法提供了一种有效的替代方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在复杂推理任务中表现出的局限性。现有方法,如思维链(Chain-of-Thought)和思维树(Tree-of-Thought),主要依赖于预定义的静态提示结构,难以适应不同复杂度的推理问题,且计算成本较高。
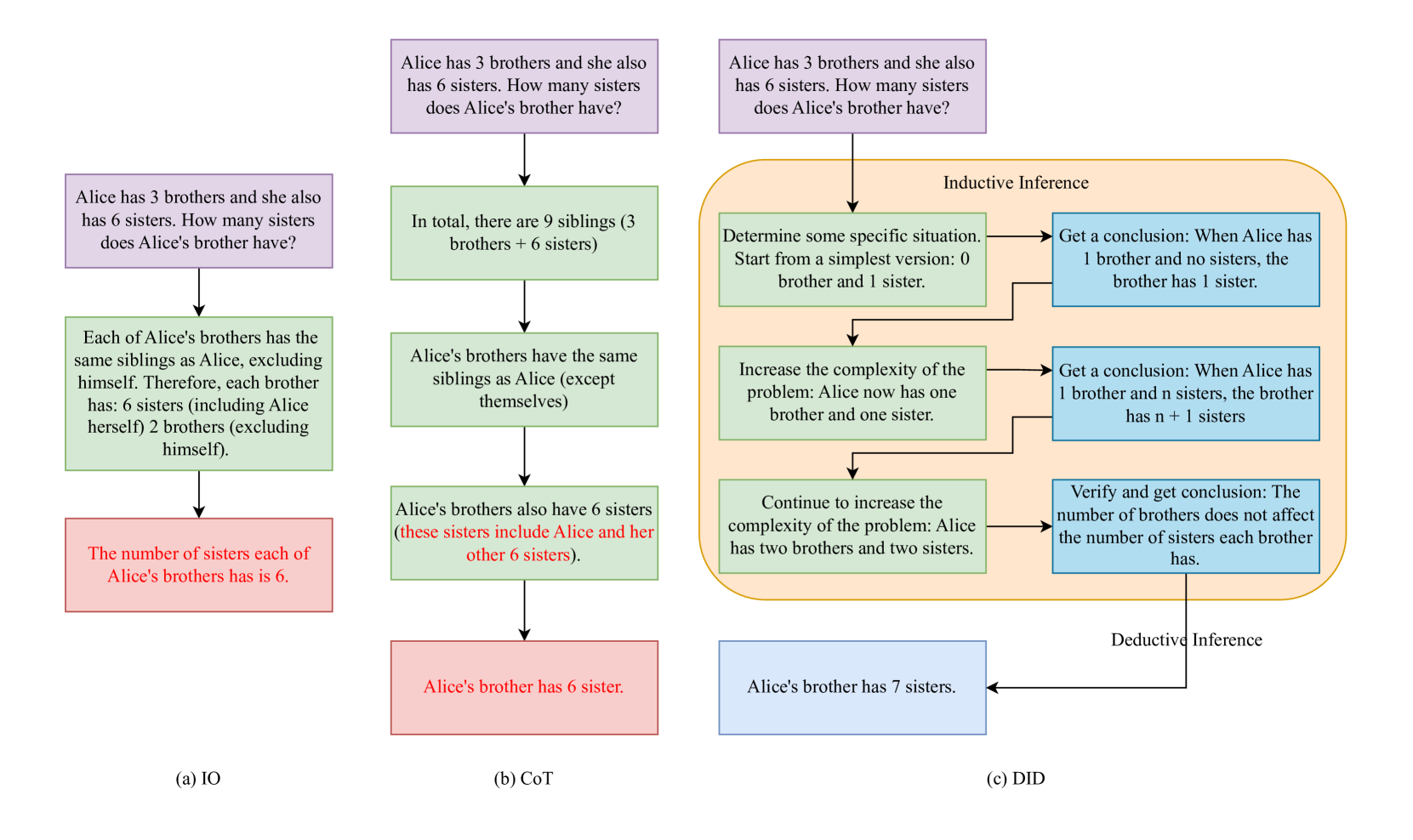
核心思路:论文的核心思路是模仿人类的认知过程,将演绎推理和归纳推理相结合,并根据问题的复杂程度动态调整推理策略。通过这种方式,模型可以更灵活、更有效地解决复杂推理问题。
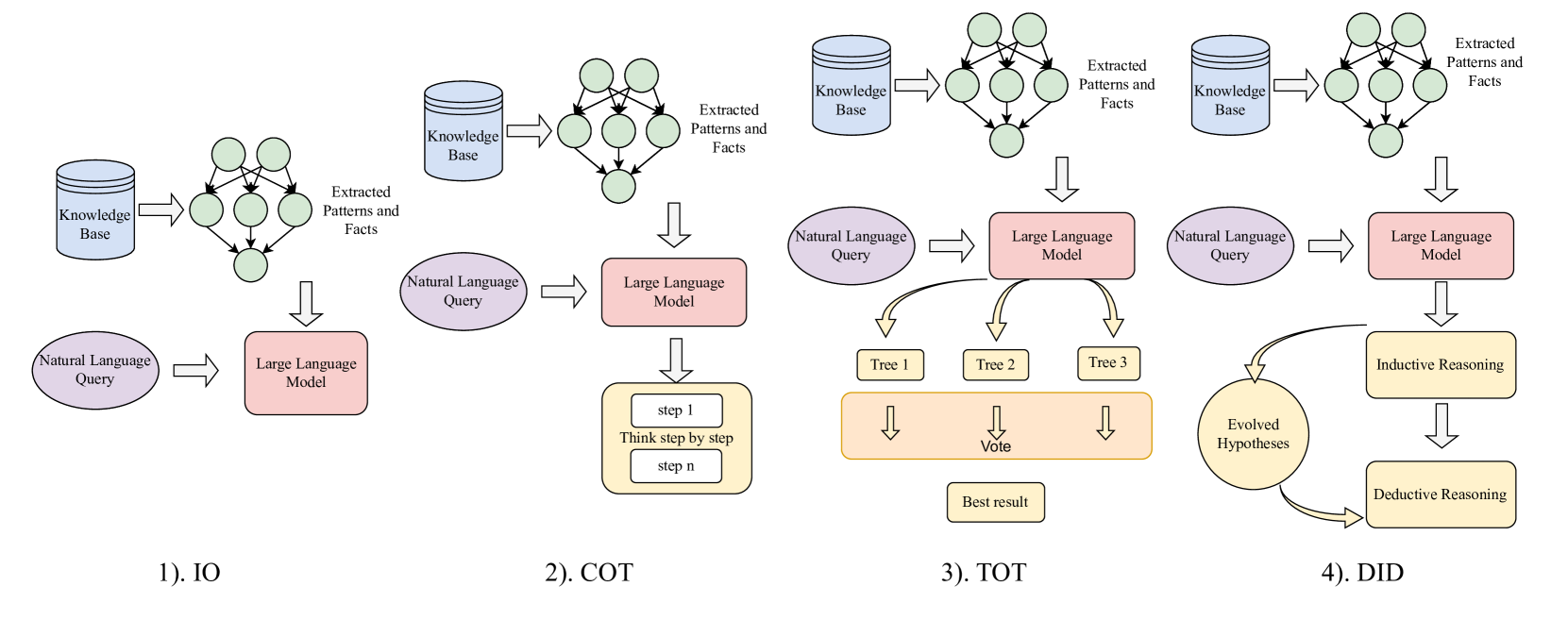
技术框架:DID方法包含以下主要模块:1) 复杂性评估模块:使用Littlestone维度和信息熵来评估输入问题的复杂性。2) 推理策略选择模块:根据复杂性评估结果,动态选择演绎推理或归纳推理策略。3) 推理执行模块:根据选择的策略,执行相应的推理过程。4) 结果整合模块:将演绎推理和归纳推理的结果进行整合,得到最终答案。
关键创新:DID方法的关键创新在于其动态推理策略选择机制。与传统的静态推理方法不同,DID能够根据输入问题的复杂性自适应地选择合适的推理策略,从而提高推理效率和准确性。此外,双重指标复杂性评估系统也是一个创新点,它能够更准确地评估问题的难度。
关键设计:复杂性评估模块中,Littlestone维度用于衡量问题的可学习性,信息熵用于衡量问题的不确定性。推理策略选择模块使用一个阈值来判断问题是更适合演绎推理还是归纳推理。该阈值的具体数值需要根据实验进行调整。推理执行模块可以使用现有的LLM推理方法,如思维链或思维树。结果整合模块可以使用简单的投票机制或更复杂的加权平均方法。
🖼️ 关键图片
📊 实验亮点
DID方法在AIW数据集上实现了70.3%的准确率,相比于Tree of Thought的62.2%有显著提升。同时,DID方法在MR-GSM8K数据集和自定义的Holiday Puzzle数据集上也取得了良好的效果。重要的是,DID方法在提高推理性能的同时,保持了较低的计算成本,使其更具实用价值。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的场景,例如智能问答系统、自动定理证明、代码生成和调试等。通过提高LLM的推理能力,可以使其在这些领域发挥更大的作用,并推动人工智能技术的进一步发展。此外,该方法在教育领域也有潜在应用价值,可以帮助学生更好地理解和解决复杂问题。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning tasks, yet their reliance on static prompt structures and limited adaptability to complex scenarios remains a significant challenge. In this paper, we propose the Deductive and InDuctive(DID) method, a novel framework that enhances LLM reasoning by dynamically integrating both deductive and inductive reasoning approaches. Drawing from cognitive science principles, DID implements a dual-metric complexity evaluation system that combines Littlestone dimension and information entropy to precisely assess task difficulty and guide decomposition strategies. DID enables the model to progressively adapt its reasoning pathways based on problem complexity, mirroring human cognitive processes. We evaluate DID's effectiveness across multiple benchmarks, including the AIW and MR-GSM8K, as well as our custom Holiday Puzzle dataset for temporal reasoning. Our results demonstrate significant improvements in reasoning quality and solution accuracy - achieving 70.3% accuracy on AIW (compared to 62.2% for Tree of Thought) while maintaining lower computational costs. The success of DID in improving LLM performance while preserving computational efficiency suggests promising directions for developing more cognitively aligned and capable language models. Our work contributes a theoretically grounded, input-centric approach to enhancing LLM reasoning capabilities, offering an efficient alternative to traditional output-exploration methods.