StreamEnsemble: Predictive Queries over Spatiotemporal Streaming Data
作者: Anderson Chaves, Eduardo Ogasawara, Patrick Valduriez, Fabio Porto
分类: stat.ML, cs.AI, cs.LG
发布日期: 2024-09-30
备注: 13 pages
💡 一句话要点
StreamEnsemble:针对时空流数据的预测查询,动态选择和分配机器学习模型。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 时空数据流 预测查询 机器学习集成 动态模型选择 数据分布分析
📋 核心要点
- 时空流数据具有复杂时空依赖性,单一模型难以适应其动态变化的数据分布,导致预测精度下降。
- StreamEnsemble动态选择和分配机器学习模型,以适应不同时空区域和时间段的数据分布,提升预测准确性。
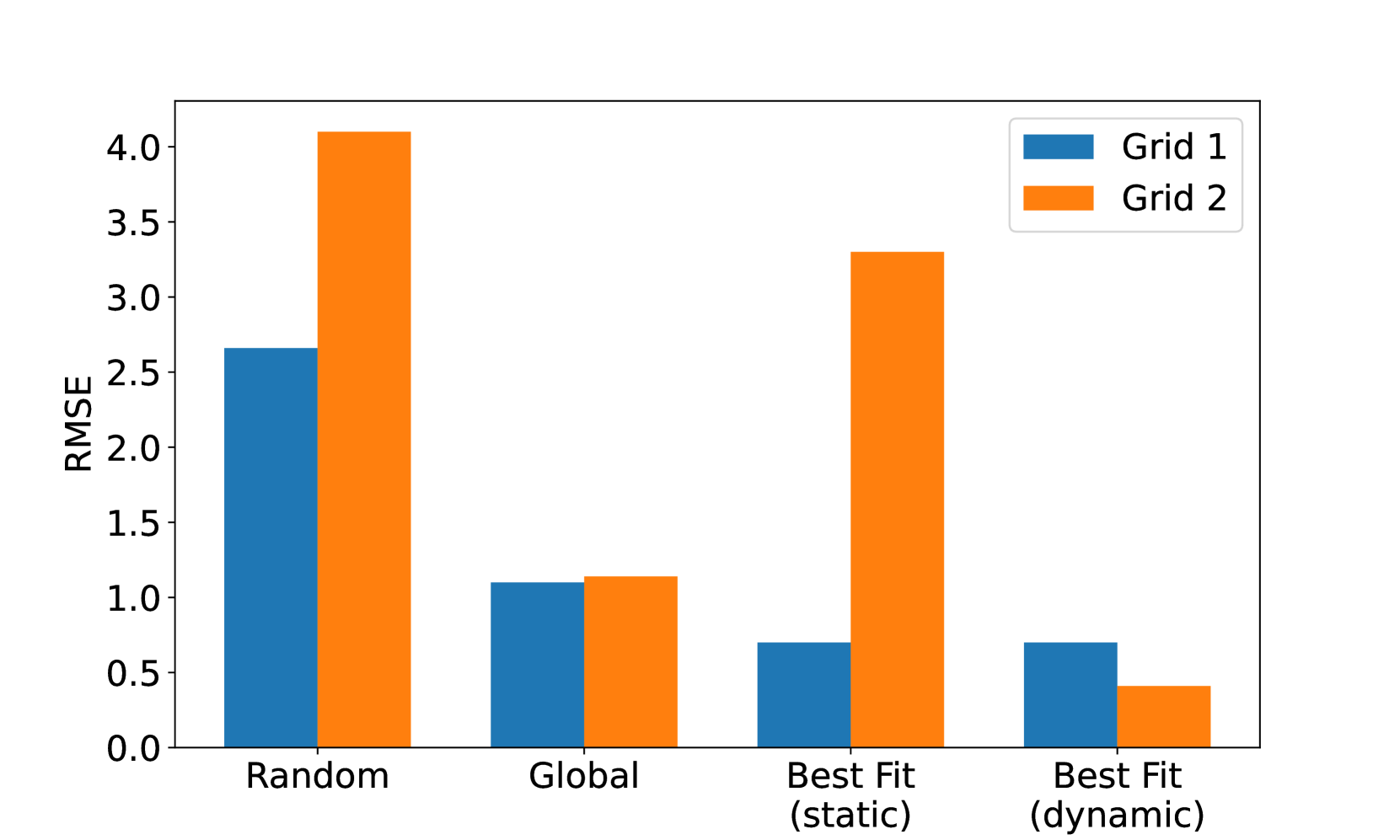
- 实验结果表明,StreamEnsemble在预测精度和时间效率上显著优于传统集成方法和单一模型方法,预测误差降低超过10倍。
📝 摘要(中文)
针对时空(ST)流数据的预测查询带来了显著的数据处理和分析挑战。时空数据流涉及一系列时间序列,其数据分布可能在空间和时间上变化,呈现出多种不同的模式。在这种情况下,假设单个机器学习模型能够充分处理这些变化很可能导致失败。为了解决这个挑战,我们提出了StreamEnsemble,这是一种针对时空数据预测查询的新方法,它根据底层时间序列分布和模型特征动态选择和分配机器学习模型。我们的实验评估表明,该方法在准确性和时间方面明显优于传统的集成方法和单一模型方法,与传统方法相比,预测误差显著降低了10倍以上。
🔬 方法详解
问题定义:论文旨在解决时空流数据预测查询中,由于数据分布随时间和空间变化而导致单一模型预测性能不佳的问题。现有方法,如单一模型或传统集成方法,无法有效捕捉时空数据的复杂动态变化,导致预测精度较低,计算开销较大。
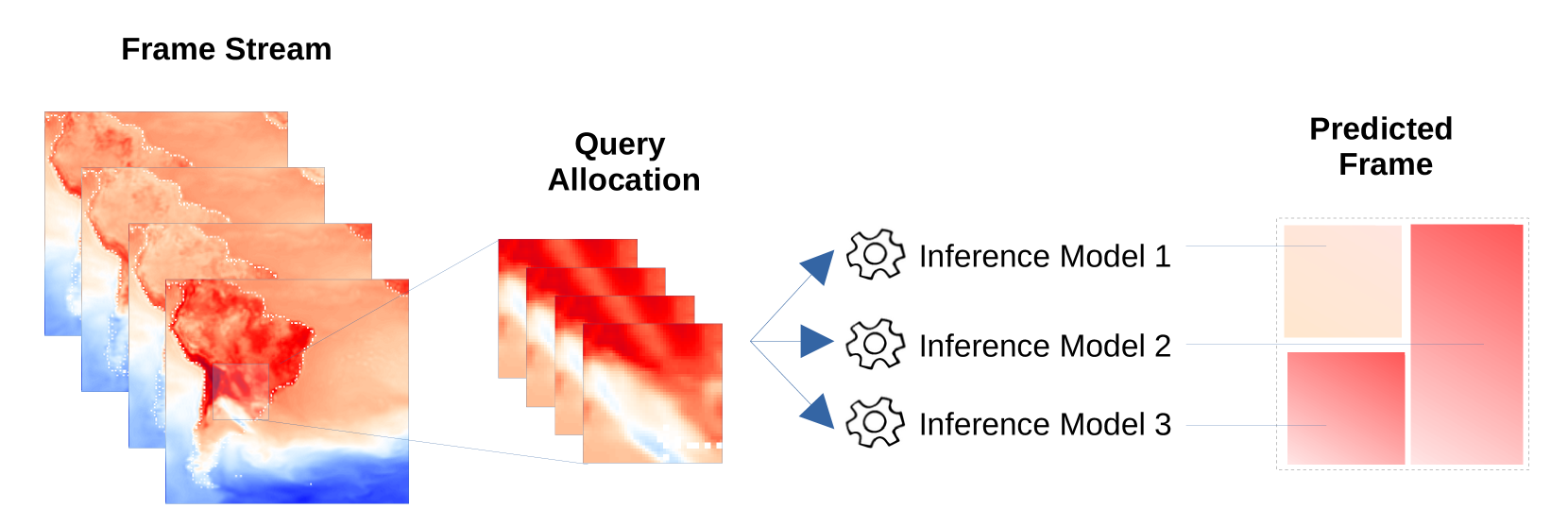
核心思路:论文的核心思路是构建一个动态的模型集成框架,该框架能够根据时空数据的分布特征,自适应地选择和分配合适的机器学习模型。通过集成多个模型,可以更好地捕捉数据的多样性和复杂性,从而提高预测精度。
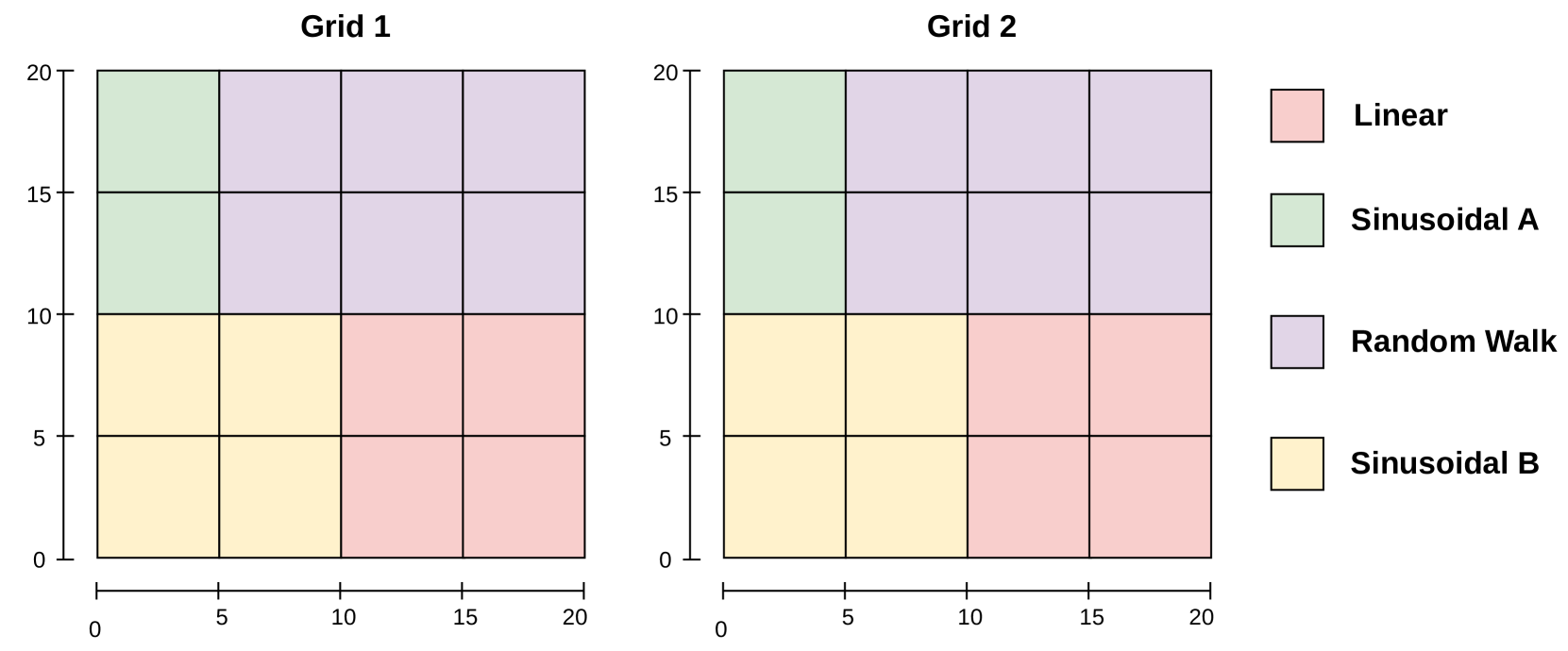
技术框架:StreamEnsemble框架主要包含以下几个模块:1) 数据流输入模块:负责接收和处理时空数据流。2) 特征提取模块:提取时空数据的相关特征,例如时间戳、空间位置等。3) 数据分布分析模块:分析数据的时空分布特征,例如均值、方差等。4) 模型选择模块:根据数据分布特征,选择合适的机器学习模型。5) 模型分配模块:将选择的模型分配给相应的时空区域或时间段。6) 模型集成模块:将多个模型的预测结果进行集成,得到最终的预测结果。
关键创新:StreamEnsemble的关键创新在于其动态模型选择和分配机制。与传统的静态模型集成方法不同,StreamEnsemble能够根据数据的实时分布特征,自适应地调整模型组合,从而更好地适应数据的动态变化。此外,该方法还考虑了模型特征,例如模型的预测精度、计算复杂度等,以优化模型选择和分配策略。
关键设计:模型选择模块可以采用多种策略,例如基于规则的方法、基于聚类的方法或基于机器学习的方法。模型分配模块可以采用基于空间划分的方法、基于时间窗口的方法或基于数据驱动的方法。模型集成模块可以采用简单的平均方法、加权平均方法或更复杂的集成学习方法。具体的参数设置、损失函数和网络结构取决于所选择的机器学习模型和集成策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,StreamEnsemble在预测精度和时间效率上显著优于传统的集成方法和单一模型方法。具体而言,StreamEnsemble的预测误差比传统方法降低了10倍以上,并且在处理大规模时空数据流时具有更高的效率。这些结果验证了StreamEnsemble的有效性和优越性。
🎯 应用场景
StreamEnsemble可应用于智慧交通、环境监测、智慧城市等领域。例如,在交通领域,可以预测交通流量、车辆速度等,从而优化交通调度和管理。在环境监测领域,可以预测空气质量、水质等,从而及时预警和采取应对措施。该研究具有重要的实际价值,有助于提高时空数据预测的准确性和效率,为相关领域的决策提供支持。
📄 摘要(原文)
Predictive queries over spatiotemporal (ST) stream data pose significant data processing and analysis challenges. ST data streams involve a set of time series whose data distributions may vary in space and time, exhibiting multiple distinct patterns. In this context, assuming a single machine learning model would adequately handle such variations is likely to lead to failure. To address this challenge, we propose StreamEnsemble, a novel approach to predictive queries over ST data that dynamically selects and allocates Machine Learning models according to the underlying time series distributions and model characteristics. Our experimental evaluation reveals that this method markedly outperforms traditional ensemble methods and single model approaches in terms of accuracy and time, demonstrating a significant reduction in prediction error of more than 10 times compared to traditional approaches.