Possible Principles for Aligned Structure Learning Agents
作者: Lancelot Da Costa, Tomáš Gavenčiak, David Hyland, Mandana Samiei, Cristian Dragos-Manta, Candice Pattisapu, Adeel Razi, Karl Friston
分类: cs.AI, q-bio.NC
发布日期: 2024-09-30 (更新: 2025-08-27)
备注: 24 pages of content, 33 with references; accepted version
💡 一句话要点
提出一种基于结构学习的人工智能对齐框架,旨在构建能理解人类偏好的智能体。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人工智能对齐 结构学习 因果表征学习 心智理论 世界模型
📋 核心要点
- 现有AI系统难以准确建模人类偏好,导致潜在的价值不对齐风险,这是可扩展AI发展的重要挑战。
- 论文提出通过结构学习,使AI agent能够学习世界模型和他人(包括人类)的模型,从而实现价值对齐。
- 论文结合数学、统计学和认知科学,探讨了核心知识、信息几何等在结构学习中的作用,并以阿西莫夫机器人定律为例进行了数学建模。
📝 摘要(中文)
本文为开发可扩展的、对齐的人工智能(AI)提供了一个路线图,该路线图基于对自然智能的第一性原理描述。简而言之,实现可扩展的对齐AI的一个可能路径在于使人工agent能够学习一个良好的世界模型,其中包括一个良好的对我们偏好的模型。为此,主要目标是创建能够学习表示世界和其他agent的世界模型的agent;这个问题属于结构学习(也称为因果表征学习或模型发现)。本文旨在阐述结构学习和对齐问题,并提出指导我们前进的原则,综合了数学、统计学和认知科学的各种思想。1) 我们讨论了核心知识、信息几何和模型约简在结构学习中的重要作用,并提出了核心结构模块来学习各种自然世界。2) 我们通过结构学习和心智理论概述了一种实现对齐agent的方法。作为一个说明性例子,我们用数学方法勾勒了阿西莫夫的机器人三定律,该定律规定agent谨慎行事,以尽量减少其他agent的不良状态。我们通过提出改进的对齐方法来补充这个例子。这些观察结果可以指导人工智能的发展,以帮助扩展现有的——或设计新的——对齐的结构学习系统。
🔬 方法详解
问题定义:论文旨在解决如何构建与人类价值观对齐的人工智能系统的问题。现有方法在让AI理解和内化人类偏好方面存在困难,导致AI的行为可能与人类期望不符,甚至产生危害。核心痛点在于AI缺乏对世界和人类行为的结构化理解,无法进行有效的因果推理和预测。
核心思路:论文的核心思路是利用结构学习(Structure Learning)方法,使AI agent能够学习一个包含人类偏好的世界模型。通过学习世界中的因果关系和agent之间的交互模式,AI可以更好地理解人类的意图和价值观,从而做出更符合人类期望的决策。这种方法强调了AI对环境和自身行为的理解能力,而非仅仅依赖于预设的规则或奖励函数。
技术框架:论文提出的技术框架包含以下几个关键模块:1) 结构学习模块:负责学习世界模型,包括对象、关系和因果结构。这可以通过因果表征学习或模型发现等技术实现。2) 心智理论模块:负责学习其他agent(包括人类)的模型,理解他们的信念、意图和偏好。3) 对齐模块:利用学习到的世界模型和心智理论,调整AI的行为,使其与人类价值观对齐。该模块可能涉及优化目标函数或约束条件,以确保AI的行为不会对人类造成伤害。
关键创新:论文的关键创新在于将结构学习和心智理论结合起来,用于解决AI对齐问题。与传统的基于规则或奖励函数的对齐方法相比,这种方法更加灵活和通用,能够适应复杂多变的环境和人类行为。此外,论文还强调了核心知识和信息几何在结构学习中的作用,为构建更有效的世界模型提供了理论指导。
关键设计:论文以阿西莫夫的机器人三定律为例,进行了数学建模,展示了如何通过结构学习和心智理论来实现对齐。具体的数学细节(如损失函数、网络结构等)并未在摘要中详细描述,属于未知信息。论文提出了refined approaches to alignment,但具体细节未知。
🖼️ 关键图片

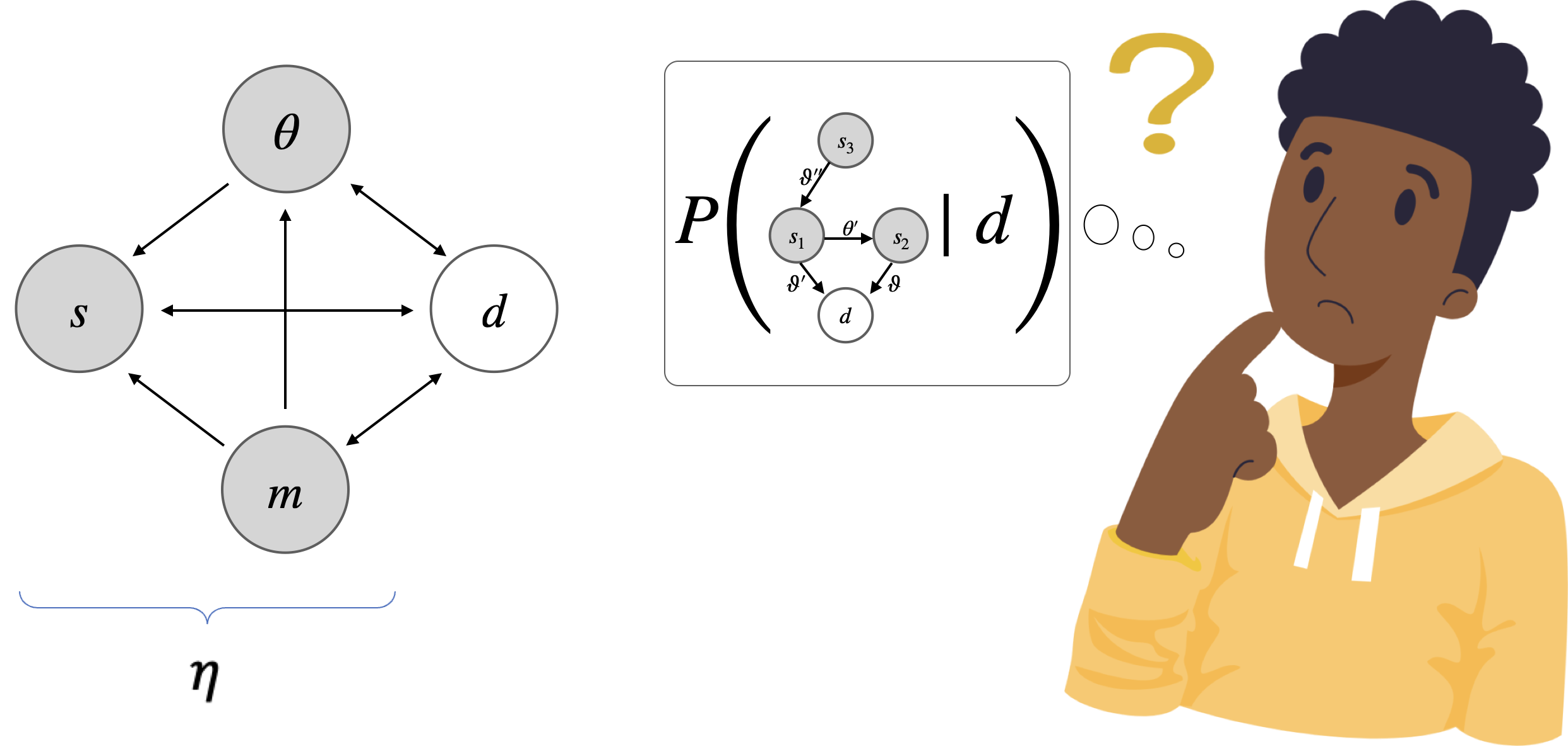
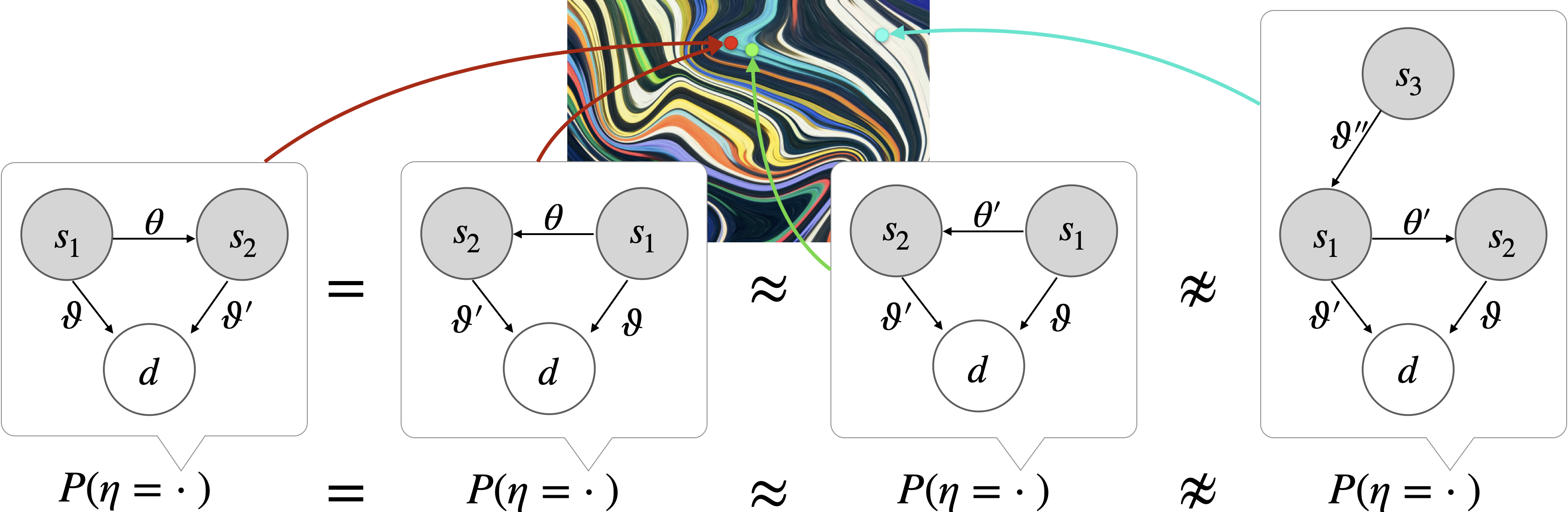
📊 实验亮点
论文通过数学建模的方式,初步验证了结构学习和心智理论在实现AI对齐方面的可行性。虽然没有提供具体的实验数据,但以阿西莫夫机器人定律为例的数学推导,为后续研究提供了理论基础和方向。论文强调了核心知识和信息几何在结构学习中的重要性,为构建更有效的世界模型提供了指导。
🎯 应用场景
该研究成果可应用于开发更安全、可靠和符合伦理规范的人工智能系统,例如自动驾驶、医疗诊断、金融风控等领域。通过使AI更好地理解人类价值观,可以避免潜在的风险和负面影响,促进人机协作,提升社会福祉。未来,该研究有望推动人工智能在各个领域的广泛应用。
📄 摘要(原文)
This paper offers a roadmap for the development of scalable aligned artificial intelligence (AI) from first principle descriptions of natural intelligence. In brief, a possible path toward scalable aligned AI rests upon enabling artificial agents to learn a good model of the world that includes a good model of our preferences. For this, the main objective is creating agents that learn to represent the world and other agents' world models; a problem that falls under structure learning (a.k.a. causal representation learning or model discovery). We expose the structure learning and alignment problems with this goal in mind, as well as principles to guide us forward, synthesizing various ideas across mathematics, statistics, and cognitive science. 1) We discuss the essential role of core knowledge, information geometry and model reduction in structure learning, and suggest core structural modules to learn a wide range of naturalistic worlds. 2) We outline a way toward aligned agents through structure learning and theory of mind. As an illustrative example, we mathematically sketch Asimov's Laws of Robotics, which prescribe agents to act cautiously to minimize the ill-being of other agents. We supplement this example by proposing refined approaches to alignment. These observations may guide the development of artificial intelligence in helping to scale existing -- or design new -- aligned structure learning systems.