Dynamic Policy Fusion for User Alignment Without Re-Interaction
作者: Ajsal Shereef Palattuparambil, Thommen George Karimpanal, Santu Rana
分类: cs.AI, cs.LG
发布日期: 2024-09-30 (更新: 2025-09-19)
💡 一句话要点
提出动态策略融合方法,无需重交互实现用户偏好对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 用户偏好对齐 动态策略融合 人机交互 零样本学习
📋 核心要点
- 深度强化学习策略难以直接对齐用户个性化偏好,重新训练成本高昂。
- 通过轨迹级反馈推断用户意图,并使用动态策略融合方法调整已有策略。
- 该方法无需额外环境交互,即可在多个环境中实现任务目标并满足用户偏好。
📝 摘要(中文)
深度强化学习(RL)策略虽然在任务奖励方面表现最优,但可能与人类用户的个人偏好不一致。为了确保这种一致性,一个直接的解决方案是使用编码用户特定偏好的奖励函数来重新训练智能体。然而,这样的奖励函数通常不易获得,因此从头开始重新训练智能体的成本可能非常高。我们提出了一种更实用的方法——借助人类反馈,使已训练的策略适应用户特定的需求。为此,我们通过轨迹级别的反馈来推断用户的意图,并通过理论上可靠的动态策略融合方法将其与已训练的任务策略相结合。由于我们的方法在用于学习任务策略的相同轨迹上收集人类反馈,因此它不需要与环境进行任何额外的交互,从而成为一种零样本方法。我们在多个环境中通过实验证明,我们提出的动态策略融合方法始终如一地实现了预期的任务,同时满足了用户特定的需求。
🔬 方法详解
问题定义:现有深度强化学习策略虽然能优化任务奖励,但往往忽略了个体用户的偏好,导致策略与用户期望不符。直接使用用户偏好重新训练智能体成本高昂,因为用户偏好通常难以显式建模为奖励函数。因此,如何在不进行大量重新训练的情况下,使策略适应用户偏好是一个关键问题。
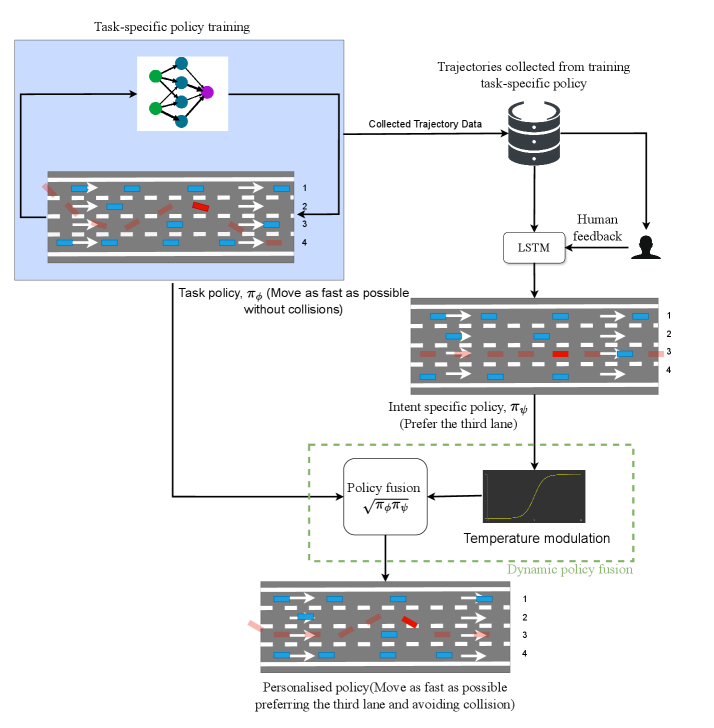
核心思路:该论文的核心思路是利用用户在已有策略产生的轨迹上的反馈,推断用户的潜在意图,然后将推断出的用户意图与原始任务策略进行融合,从而得到一个既能完成任务又能满足用户偏好的新策略。这种方法避免了从头开始重新训练,降低了计算成本,并且只需要用户对已有轨迹进行反馈,无需额外的环境交互。
技术框架:整体框架包含以下几个主要步骤:1) 使用深度强化学习训练一个初始的任务策略。2) 使用该策略与环境交互,生成一系列轨迹。3) 收集用户对这些轨迹的反馈(例如,对轨迹的偏好排序或打分)。4) 基于用户反馈,推断用户的意图(例如,学习一个奖励函数或偏好模型)。5) 使用动态策略融合方法,将推断出的用户意图与初始任务策略进行融合,得到最终的策略。
关键创新:该论文的关键创新在于提出了一种动态策略融合方法,该方法能够有效地将用户意图融入到已有的任务策略中,而无需进行大量的重新训练或额外的环境交互。这种方法特别适用于用户偏好难以显式建模的场景,并且能够快速适应不同用户的个性化需求。此外,使用轨迹级别的反馈而非动作级别的反馈,降低了用户标注的负担。
关键设计:动态策略融合的具体实现方式未知,论文中可能涉及以下关键设计:1) 用户意图的表示方式(例如,奖励函数、偏好模型等)。2) 策略融合的具体算法(例如,加权平均、策略梯度等)。3) 如何保证融合后的策略既能完成任务,又能满足用户偏好。4) 如何处理用户反馈中的噪声和不确定性。这些细节决定了策略融合的效果和鲁棒性。
🖼️ 关键图片

📊 实验亮点
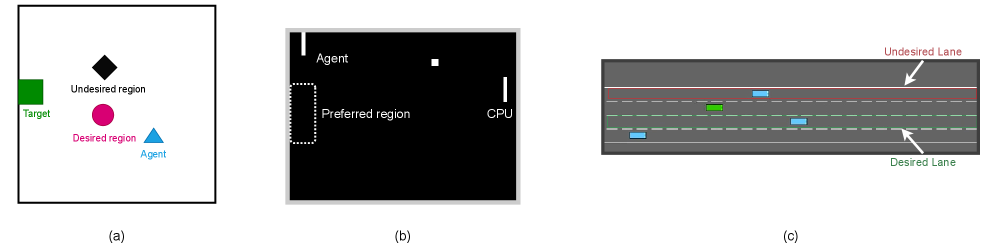
论文在多个模拟环境中验证了所提出的动态策略融合方法的有效性。实验结果表明,该方法能够在不进行额外环境交互的情况下,有效地将用户意图融入到已有的任务策略中,并且能够同时实现任务目标和满足用户偏好。具体的性能数据和对比基线未知,但论文强调该方法在多个环境中表现一致。
🎯 应用场景
该研究成果可应用于人机协作机器人、个性化推荐系统、自动驾驶等领域。例如,在人机协作机器人中,可以根据用户的操作习惯和偏好,动态调整机器人的行为策略,提高协作效率和用户满意度。在个性化推荐系统中,可以根据用户的历史行为和反馈,动态调整推荐策略,提高推荐的准确性和用户体验。
📄 摘要(原文)
Deep reinforcement learning (RL) policies, although optimal in terms of task rewards, may not align with the personal preferences of human users. To ensure this alignment, a naive solution would be to retrain the agent using a reward function that encodes the user's specific preferences. However, such a reward function is typically not readily available, and as such, retraining the agent from scratch can be prohibitively expensive. We propose a more practical approach - to adapt the already trained policy to user-specific needs with the help of human feedback. To this end, we infer the user's intent through trajectory-level feedback and combine it with the trained task policy via a theoretically grounded dynamic policy fusion approach. As our approach collects human feedback on the very same trajectories used to learn the task policy, it does not require any additional interactions with the environment, making it a zero-shot approach. We empirically demonstrate in a number of environments that our proposed dynamic policy fusion approach consistently achieves the intended task while simultaneously adhering to user-specific needs.