On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
作者: Kevin Wang, Junbo Li, Neel P. Bhatt, Yihan Xi, Qiang Liu, Ufuk Topcu, Zhangyang Wang
分类: cs.AI, cs.LG, cs.RO
发布日期: 2024-09-30 (更新: 2024-10-14)
备注: Code available at https://github.com/VITA-Group/o1-planning
🔗 代码/项目: GITHUB
💡 一句话要点
评估OpenAI o1模型在规划任务中的可行性、最优性和泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 规划能力 可行性 最优性 泛化性 约束满足 空间推理
📋 核心要点
- 大型语言模型在复杂推理任务中展现潜力,但其规划能力仍待探索,尤其是在约束和空间推理方面。
- 论文通过评估o1模型在多种规划任务中的表现,分析其可行性、最优性和泛化能力,揭示其优势与不足。
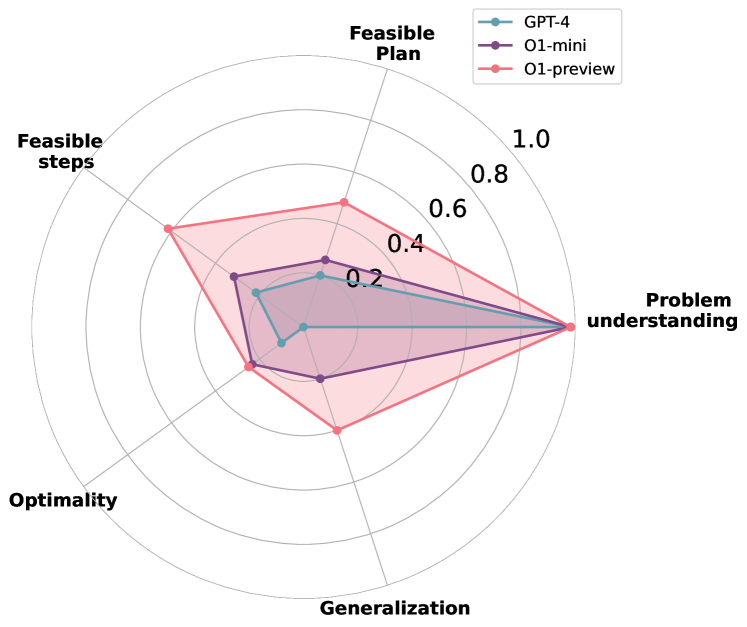
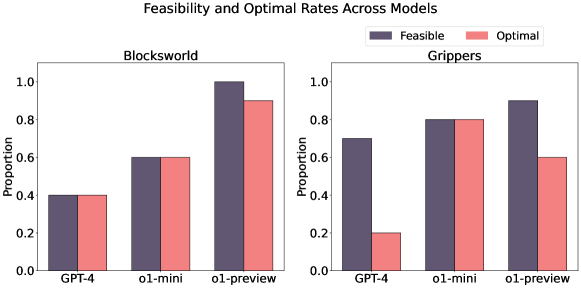
- 实验表明o1-preview在约束遵循方面优于GPT-4,但在空间推理和生成最优解方面存在局限性,为未来研究提供方向。
📝 摘要(中文)
本文评估了OpenAI的o1模型在各种基准任务中的规划能力,重点关注可行性、最优性和泛化性三个关键方面。通过对约束性任务(如$ extit{Barman}$、$ extit{Tyreworld}$)和空间复杂环境(如$ extit{Termes}$、$ extit{Floortile}$)的实证评估,突出了o1-preview在自我评估和约束遵循方面的优势,同时也发现了决策和记忆管理方面的瓶颈,尤其是在需要强大的空间推理的任务中。结果表明,o1-preview在遵循任务约束和管理结构化环境中的状态转换方面优于GPT-4。然而,该模型经常生成具有冗余动作的次优解决方案,并且难以在空间复杂的任务中有效地泛化。这项初步研究为LLM的规划局限性提供了基础性的见解,为未来改进基于LLM的规划中的记忆管理、决策和泛化的研究提供了关键方向。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在规划任务中的能力,特别是OpenAI的o1模型。现有方法,即直接应用LLMs进行规划,在处理具有复杂约束和空间推理的任务时表现出局限性,例如生成不符合约束的计划或无法在复杂环境中找到最优路径。这些痛点源于LLMs在记忆管理、决策制定和泛化能力上的不足。
核心思路:论文的核心思路是通过设计一系列具有不同挑战性的规划任务,系统性地评估o1模型在可行性(是否能生成有效计划)、最优性(计划是否高效)和泛化性(在不同环境下的适应性)三个方面的表现。通过分析模型的成功和失败案例,揭示其内在优势和局限性,从而为改进LLM的规划能力提供指导。
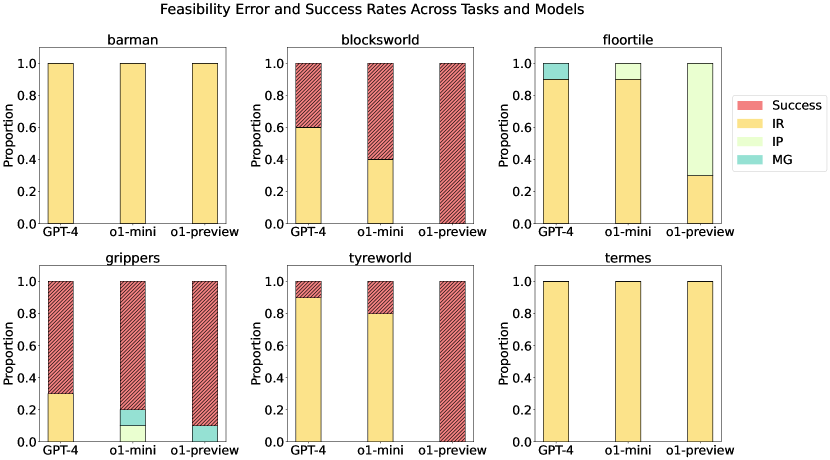
技术框架:论文采用实证研究的方法,选择了一系列具有代表性的规划任务,包括约束性任务(Barman, Tyreworld)和空间复杂环境(Termes, Floortile)。研究流程包括:1) 使用o1模型生成规划方案;2) 评估方案的可行性、最优性和泛化性;3) 分析模型在不同任务上的表现差异,识别其优势和不足。
关键创新:论文的关键创新在于对LLM规划能力的系统性评估框架。它不仅关注模型是否能生成可行的计划,还深入分析了计划的最优性和泛化能力。此外,论文还通过对比o1模型和GPT-4在不同任务上的表现,揭示了o1模型在约束遵循方面的优势。
关键设计:论文的关键设计包括:1) 任务选择:选择具有不同挑战性的规划任务,以全面评估模型的规划能力;2) 评估指标:设计了可行性、最优性和泛化性三个评估指标,以量化模型的规划表现;3) 对比实验:通过对比o1模型和GPT-4在不同任务上的表现,分析模型的优势和不足。
🖼️ 关键图片
📊 实验亮点
实验结果表明,o1-preview在遵循任务约束和管理状态转换方面优于GPT-4。然而,o1-preview生成的解决方案通常是次优的,包含冗余动作,并且在空间复杂的任务中泛化能力较弱。例如,在Floortile任务中,o1模型难以找到最优路径,导致规划效率降低。这些发现揭示了LLM在规划能力上的局限性,为未来的研究提供了改进方向。
🎯 应用场景
该研究成果可应用于机器人导航、任务调度、自动化流程设计等领域。通过提升LLM的规划能力,可以实现更智能、更高效的自动化系统,例如,在复杂环境中自主导航的机器人、能够优化资源分配的智能调度系统等。未来的研究可以进一步探索如何利用LLM的知识和推理能力,构建更强大的规划系统。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $\textit{Barman}$, $\textit{Tyreworld}$) and spatially complex environments (e.g., $\textit{Termes}$, $\textit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning. Code available at https://github.com/VITA-Group/o1-planning.