Semantic Alignment-Enhanced Code Translation via an LLM-Based Multi-Agent System
作者: Zhiqiang Yuan, Weitong Chen, Hanlin Wang, Kai Yu, Xin Peng, Yiling Lou
分类: cs.SE, cs.AI
发布日期: 2024-09-30 (更新: 2025-09-17)
💡 一句话要点
提出TRANSAGENT,利用多Agent协同和语义对齐提升LLM代码翻译质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码翻译 大型语言模型 多Agent系统 语义对齐 错误修复
📋 核心要点
- 现有基于LLM的代码翻译方法在处理语法和语义错误时存在挑战,尤其是在缺乏有效调试机制的情况下。
- TRANSAGENT通过多Agent协同,利用代码对齐缩小错误定位范围,从而降低LLM修复错误的难度。
- TRANSAGENT在新建基准测试中,翻译效果和效率均优于UniTrans,并在不同LLM上表现出良好的泛化能力。
📝 摘要(中文)
代码翻译是将代码从一种编程语言转换为另一种编程语言,同时保持其原始功能,这对于软件迁移、系统重构和跨平台开发至关重要。传统基于规则的方法依赖于手动编写的规则,这非常耗时,并且通常导致代码可读性较差。为了克服这个问题,已经开发了基于学习的方法,利用并行数据来训练模型以进行自动代码翻译。最近,大型语言模型(LLM)的进步进一步推动了基于学习的代码翻译。尽管前景广阔,但LLM翻译的程序仍然存在各种质量问题(例如,语法错误和语义错误)。特别是,当仅提供相应的错误消息时,LLM可能难以自行调试这些错误。在这项工作中,我们提出了一种新颖的基于LLM的多Agent系统TRANSAGENT,它通过四个基于LLM的Agent(包括初始代码翻译器、语法错误修复器、代码对齐器和语义错误修复器)之间的协同作用来修复语法错误和语义错误,从而增强了基于LLM的代码翻译。TRANSAGENT的主要思想是首先基于目标程序和源程序之间的执行对齐来定位目标程序中的错误代码块,这可以缩小修复范围,从而降低修复难度。为了评估TRANSAGENT,我们首先从最新的编程任务中构建了一个新的基准,以减轻潜在的数据泄露问题。在我们的基准测试中,TRANSAGENT在翻译有效性和效率方面均优于最新的基于LLM的代码翻译技术UniTrans;此外,我们对不同LLM的评估表明了TRANSAGENT的泛化性,并且我们的消融研究表明了每个Agent的贡献。
🔬 方法详解
问题定义:代码翻译旨在将一种编程语言的代码自动转换为另一种语言,同时保持其功能不变。现有的基于LLM的方法虽然取得了进展,但容易产生语法和语义错误,且缺乏有效的自我调试机制,导致翻译质量不高。直接让LLM根据错误信息进行修复,效果往往不佳,因为搜索空间太大,难以准确定位错误根源。
核心思路:TRANSAGENT的核心思路是利用多Agent协同工作,并引入代码对齐技术来辅助错误定位。通过将翻译任务分解为多个步骤,并让不同的Agent负责不同的子任务(如初始翻译、语法修复、语义修复),可以更有效地利用LLM的能力。代码对齐则用于在源程序和目标程序之间建立对应关系,从而帮助定位语义错误。
技术框架:TRANSAGENT包含四个主要Agent:1) Initial Code Translator:负责将源程序翻译成目标程序。2) Syntax Error Fixer:负责修复翻译后代码的语法错误。3) Code Aligner:负责对齐源程序和目标程序的执行轨迹,找出语义不一致的代码块。4) Semantic Error Fixer:负责修复语义错误,确保翻译后的代码与源程序的功能一致。整个流程是:首先由Initial Code Translator进行初步翻译,然后Syntax Error Fixer修复语法错误。接着,Code Aligner进行代码对齐,找出潜在的语义错误区域。最后,Semantic Error Fixer根据对齐信息和错误信息,修复语义错误。
关键创新:TRANSAGENT的关键创新在于:1) 引入了多Agent协同机制,将复杂的代码翻译任务分解为多个子任务,并让不同的Agent负责不同的子任务,从而提高了翻译质量。2) 利用代码对齐技术来辅助错误定位,缩小了错误修复的搜索空间,提高了修复效率。3) 构建了一个新的代码翻译基准测试,以解决现有基准测试可能存在的数据泄露问题。
关键设计:Code Aligner模块是关键。它通过执行源程序和目标程序,并比较它们的执行轨迹(例如,变量的值、函数调用等),来找出语义不一致的代码块。具体的对齐算法和相似度度量方式(例如,动态时间规整DTW)需要根据具体的编程语言和任务进行调整。Semantic Error Fixer在修复语义错误时,会参考对齐信息、错误信息和源程序代码,生成修复建议。LLM的prompt设计也至关重要,需要清晰地描述任务目标、输入信息和输出格式。
🖼️ 关键图片
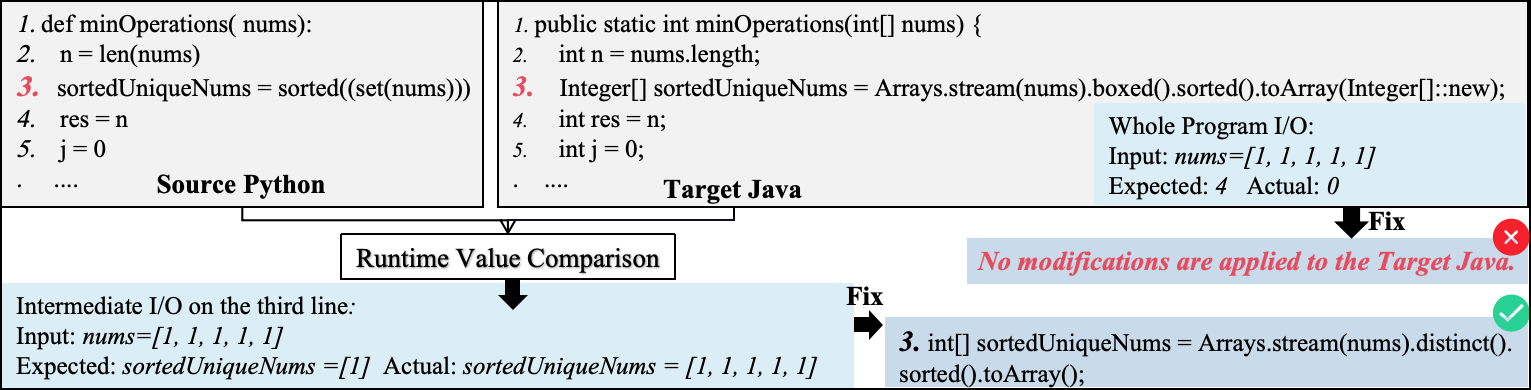

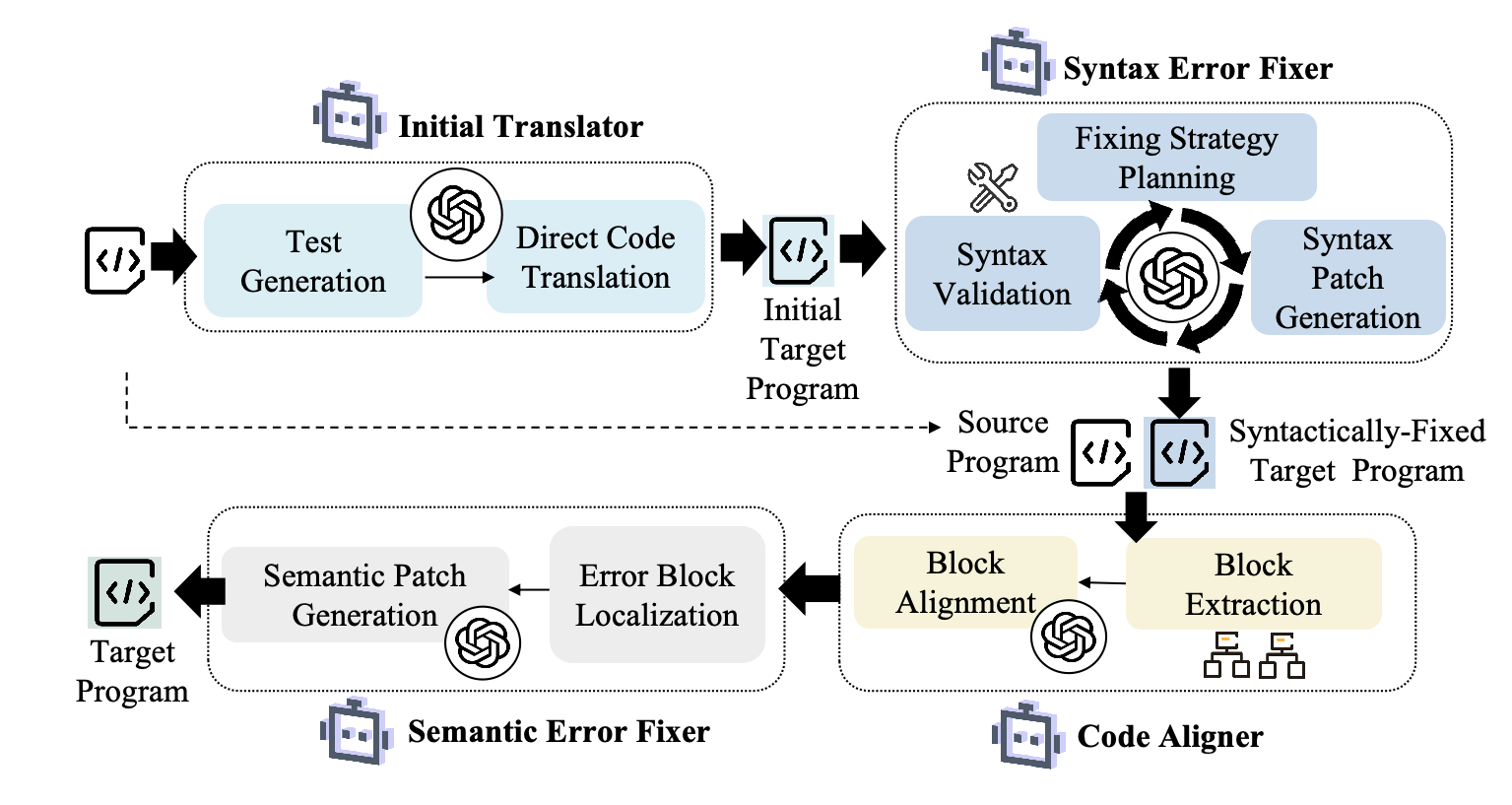
📊 实验亮点
TRANSAGENT在自建基准测试中,显著优于UniTrans等现有方法。具体而言,在翻译有效性和效率方面均取得了提升。消融实验表明,每个Agent都对最终的翻译质量做出了贡献。此外,实验结果还表明TRANSAGENT具有良好的泛化能力,可以在不同的LLM上取得良好的效果。
🎯 应用场景
TRANSAGENT可应用于软件迁移、系统重构和跨平台开发等领域。它可以帮助开发者将遗留系统或应用程序从一种编程语言迁移到另一种编程语言,从而降低维护成本和提高开发效率。此外,TRANSAGENT还可以用于自动化代码审查和代码生成等任务,具有广泛的应用前景。
📄 摘要(原文)
Code translation converts code from one programming language to another while maintaining its original functionality, which is crucial for software migration, system refactoring, and cross-platform development. Traditional rule-based methods rely on manually-written rules, which can be time-consuming and often result in less readable code. To overcome this, learning-based methods have been developed, leveraging parallel data to train models for automated code translation. More recently, the advance of Large Language Models (LLMs) further boosts learning-based code translation. Although promising, LLM-translated program still suffers from diverse quality issues (e.g., syntax errors and semantic errors). In particular, it can be challenging for LLMs to self-debug these errors when simply provided with the corresponding error messages. In this work, we propose a novel LLM-based multi-agent system TRANSAGENT, which enhances LLM-based code translation by fixing the syntax errors and semantic errors with the synergy between four LLM-based agents, including Initial Code Translator, Syntax Error Fixer, Code Aligner, and Semantic Error Fixer. The main insight of TRANSAGENT is to first localize the error code block in the target program based on the execution alignment between the target and source program, which can narrow down the fixing space and thus lower down the fixing difficulties. To evaluate TRANSAGENT, we first construct a new benchmark from recent programming tasks to mitigate the potential data leakage issue. On our benchmark, TRANSAGENT outperforms the latest LLM-based code translation technique UniTrans in both translation effectiveness and efficiency; additionally, our evaluation on different LLMs show the generalization of TRANSAGENT and our ablation study shows the contribution of each agent.