"Oh LLM, I'm Asking Thee, Please Give Me a Decision Tree": Zero-Shot Decision Tree Induction and Embedding with Large Language Models
作者: Ricardo Knauer, Mario Koddenbrock, Raphael Wallsberger, Nicholas M. Brisson, Georg N. Duda, Deborah Falla, David W. Evans, Erik Rodner
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-09-27 (更新: 2025-05-27)
备注: KDD 2025 Research Track
🔗 代码/项目: GITHUB
💡 一句话要点
利用大语言模型零样本生成决策树,提升小样本表格数据预测性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 零样本学习 决策树 表格数据 可解释性
📋 核心要点
- 传统机器学习在数据有限时表现不佳,且模型可解释性弱,难以利用先验知识。
- 利用LLM压缩的世界知识,零样本生成可解释的决策树模型,无需训练数据。
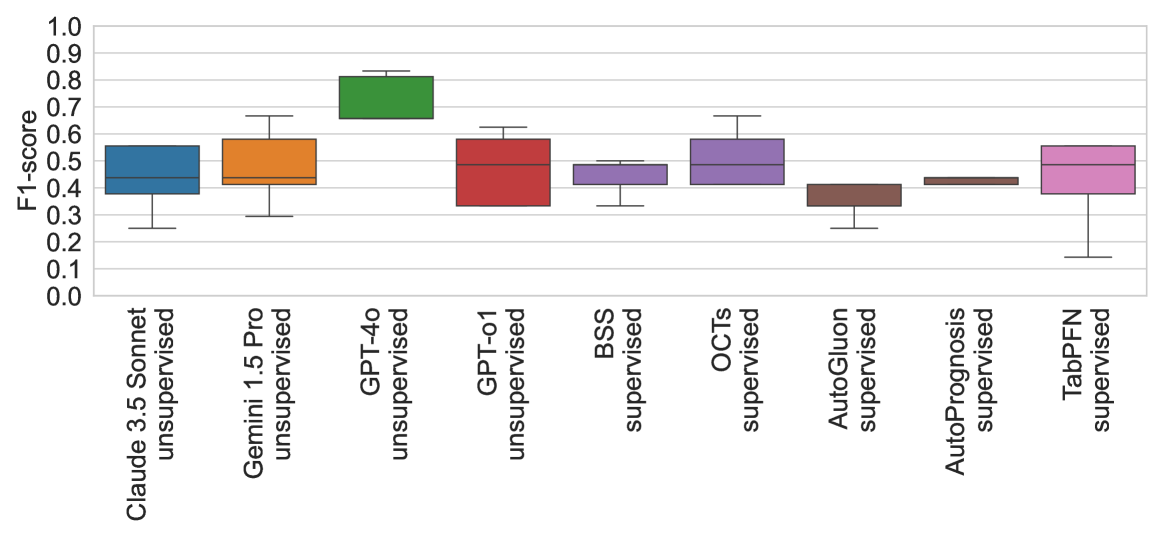
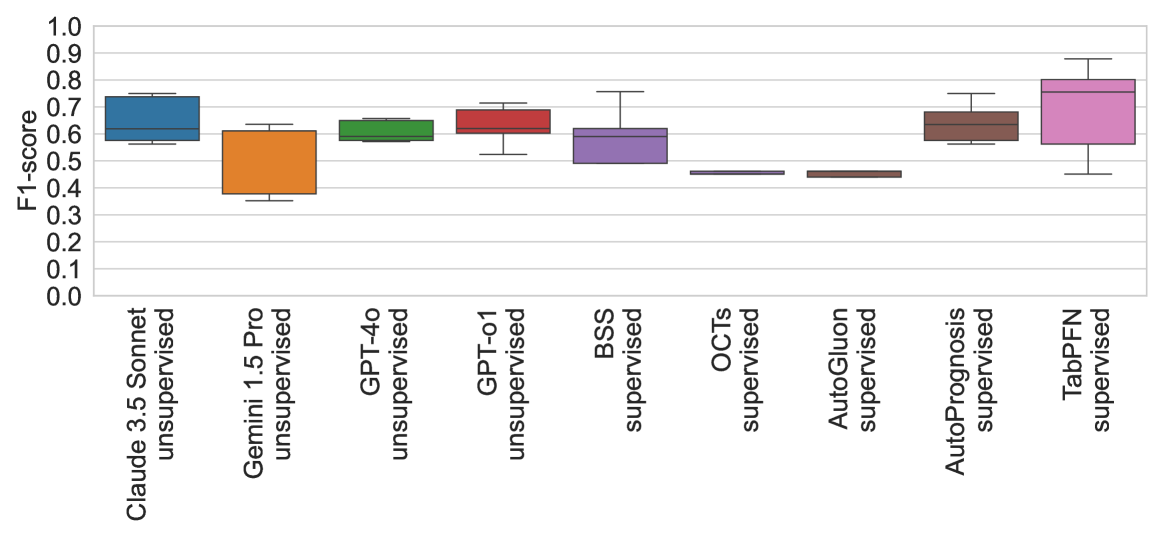
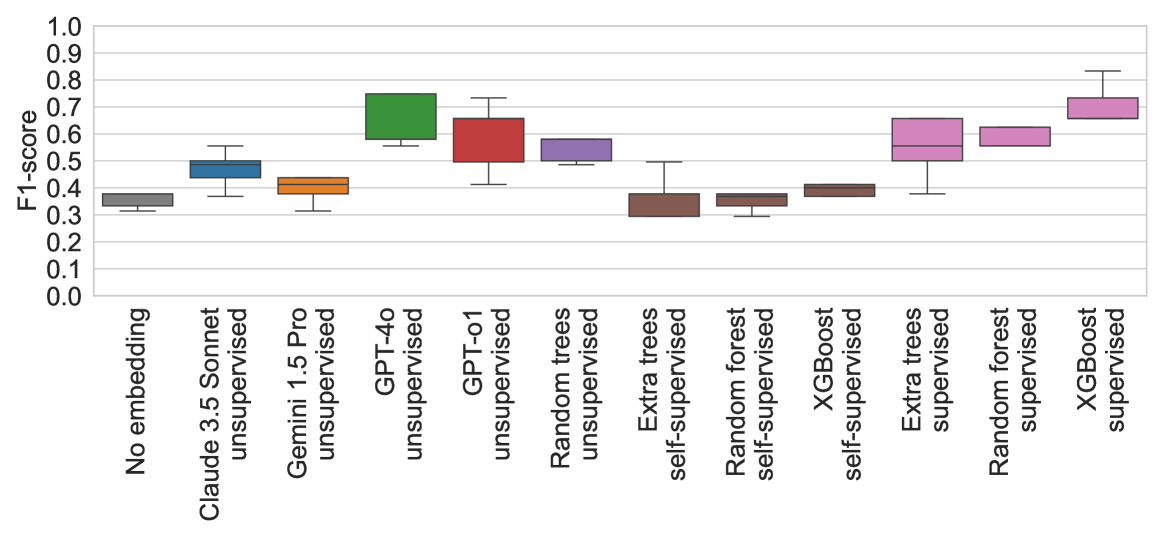
- 实验表明,该方法在小样本数据集上超越数据驱动方法,并能生成更好的嵌入。
📝 摘要(中文)
本文提出了一种利用大型语言模型(LLM)生成决策树的方法,无需任何训练数据。研究表明,这些零样本决策树在一些小规模表格数据集上甚至可以超越数据驱动的决策树。此外,从这些树中导出的嵌入向量也优于数据驱动的基于树的嵌入向量。因此,本文提出的决策树归纳和嵌入方法可以作为低数据场景下数据驱动机器学习方法的新型知识驱动基线。更重要的是,它们提供了一种利用LLM中丰富的世界知识来解决表格机器学习任务的途径。代码和结果已公开。
🔬 方法详解
问题定义:论文旨在解决小样本表格数据上的预测建模问题。传统的数据驱动方法在数据量不足时容易过拟合,泛化能力差,并且难以利用已有的世界知识。此外,许多机器学习模型的可解释性较差,难以理解模型的决策过程。
核心思路:论文的核心思路是利用大型语言模型(LLM)中蕴含的丰富世界知识,直接生成决策树,而无需任何训练数据。通过精心设计的提示(prompt),引导LLM根据其已有的知识来判断特征的重要性,并构建决策树的结构。这样可以有效利用先验知识,提高模型在小样本数据上的泛化能力,并提供可解释的决策过程。
技术框架:该方法主要包含以下几个阶段:1) 特征选择:利用LLM根据特征的描述和任务目标,判断特征的重要性,并选择用于构建决策树的特征。2) 分裂节点确定:对于每个选定的特征,利用LLM确定最佳的分裂阈值或类别。3) 决策树构建:根据特征选择和分裂节点确定的结果,递归地构建决策树的结构。4) 嵌入生成:利用生成的决策树,将数据点映射到叶节点,并生成相应的嵌入向量。
关键创新:该方法最重要的创新点在于利用LLM的零样本学习能力,直接生成决策树,而无需任何训练数据。这与传统的数据驱动方法形成了鲜明对比,为小样本学习提供了一种新的思路。此外,该方法还提供了一种将LLM的知识迁移到表格数据上的有效途径。
关键设计:关键设计包括:1) 提示工程:设计合适的提示(prompt)是至关重要的,需要引导LLM理解任务目标,并有效地利用其已有的知识。2) 特征描述:提供清晰、准确的特征描述,有助于LLM判断特征的重要性。3) 分裂阈值确定:采用多种策略来确定分裂阈值,例如,直接询问LLM,或者利用LLM生成候选阈值,然后选择最佳阈值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在一些小规模表格数据集上,零样本决策树的性能甚至可以超越数据驱动的决策树。此外,从零样本决策树中导出的嵌入向量,在平均水平上优于数据驱动的基于树的嵌入向量。这些结果表明,该方法在低数据场景下具有显著的优势,可以作为数据驱动方法的有效补充。
🎯 应用场景
该研究成果可应用于医疗诊断、金融风控、推荐系统等领域,尤其是在数据稀缺或获取成本高昂的场景下。例如,在罕见疾病诊断中,由于病例数量有限,传统机器学习方法难以有效训练,而该方法可以利用LLM的医学知识,辅助医生进行诊断。此外,该方法生成的可解释决策树,有助于用户理解模型的决策过程,增强信任感。
📄 摘要(原文)
Large language models (LLMs) provide powerful means to leverage prior knowledge for predictive modeling when data is limited. In this work, we demonstrate how LLMs can use their compressed world knowledge to generate intrinsically interpretable machine learning models, i.e., decision trees, without any training data. We find that these zero-shot decision trees can even surpass data-driven trees on some small-sized tabular datasets and that embeddings derived from these trees perform better than data-driven tree-based embeddings on average. Our decision tree induction and embedding approaches can therefore serve as new knowledge-driven baselines for data-driven machine learning methods in the low-data regime. Furthermore, they offer ways to harness the rich world knowledge within LLMs for tabular machine learning tasks. Our code and results are available at https://github.com/ml-lab-htw/llm-trees.