MMMT-IF: A Challenging Multimodal Multi-Turn Instruction Following Benchmark
作者: Elliot L. Epstein, Kaisheng Yao, Jing Li, Xinyi Bai, Hamid Palangi
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-09-26
备注: 24 pages, 16 figures
💡 一句话要点
提出MMMT-IF基准测试,用于评估多模态多轮对话中指令遵循能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态对话 指令遵循 基准测试 程序化验证 长程依赖
📋 核心要点
- 现有方法在评估多模态多轮对话中的指令遵循能力时,面临人工评估耗时和LLM评估器偏差的问题。
- MMMT-IF通过添加全局指令约束答案格式,并使用代码执行客观验证指令,挑战模型在长对话中检索指令并推理。
- 实验表明,现有模型在长对话中指令遵循能力显著下降,且指令检索是关键瓶颈。
📝 摘要(中文)
评估多模态、多轮对话中的指令遵循能力极具挑战。由于输入模型上下文中可能存在多条指令,人工评估非常耗时,并且基于LLM的评估器对来自同一模型的答案存在偏差。我们提出了MMMT-IF,这是一个基于图像的多轮问答评估集,在问题之间添加了全局指令,约束了答案格式。这挑战了模型检索分散在长对话中的指令,并在指令约束下进行推理。所有指令都可以通过代码执行进行客观验证。我们引入了程序化指令遵循(PIF)指标,以衡量在执行推理任务时正确遵循指令的比例。PIF-N-K指标集通过测量语料库中至少K个模型响应达到PIF分数为1的样本比例,进一步评估了鲁棒性。PIF指标与人类指令遵循评分一致,显示出60%的相关性。实验表明,Gemini 1.5 Pro、GPT-4o和Claude 3.5 Sonnet的PIF指标从第一轮的平均0.81下降到第20轮的0.64。在所有轮次中,当每个响应重复4次(PIF-4-4)时,GPT-4o和Gemini仅在11%的时间内成功遵循所有指令。当所有指令也附加到模型输入上下文的末尾时,PIF指标平均提高了22.3个百分点,表明该任务的挑战不仅在于遵循指令,还在于检索分散在模型上下文中的指令。我们计划开源MMMT-IF数据集和指标计算代码。
🔬 方法详解
问题定义:论文旨在解决多模态多轮对话中指令遵循能力的评估问题。现有方法依赖人工评估,成本高昂且主观;而使用LLM进行自动评估时,容易对来自同一模型的答案产生偏差,导致评估结果不准确。因此,需要一个客观、高效的评估基准来衡量模型在复杂对话场景下的指令理解和执行能力。
核心思路:论文的核心思路是构建一个可编程验证的指令遵循评估基准。通过在多轮对话中穿插全局指令,并要求模型在回答问题时遵循这些指令,从而模拟真实场景下的复杂交互。关键在于指令的设计,使其能够通过代码执行进行客观验证,避免主观偏差。
技术框架:MMMT-IF基准测试包含以下几个关键组成部分:1) 基于图像的多轮问答对话;2) 分散在对话中的全局指令,约束答案格式;3) 用于客观验证指令遵循情况的代码执行环境;4) 程序化指令遵循(PIF)指标,用于量化模型遵循指令的程度;5) PIF-N-K指标集,用于评估模型的鲁棒性。整体流程是:模型接收包含图像和对话历史的输入,生成答案,然后通过代码执行验证答案是否符合指令要求,最后计算PIF和PIF-N-K指标。
关键创新:该论文的关键创新在于提出了一个可编程验证的指令遵循评估框架。与传统的依赖人工评估或LLM评估的方法不同,MMMT-IF通过代码执行来客观验证指令遵循情况,避免了主观偏差。此外,PIF和PIF-N-K指标能够更细粒度地衡量模型的指令遵循能力和鲁棒性。
关键设计:指令的设计是关键。指令需要足够明确,能够通过代码执行进行验证,并且能够约束答案的格式。例如,指令可以要求答案必须包含特定的关键词,或者必须按照特定的格式排列。PIF指标的计算方式是:对于每个样本,计算模型生成的答案中符合指令要求的比例。PIF-N-K指标的计算方式是:对于每个样本,重复生成N个答案,然后计算至少K个答案的PIF分数为1的样本比例。
🖼️ 关键图片
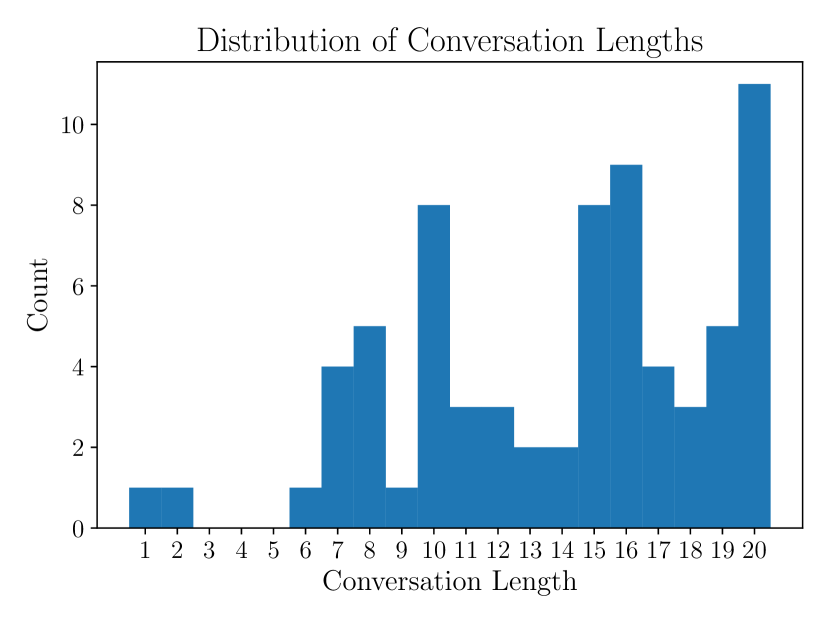
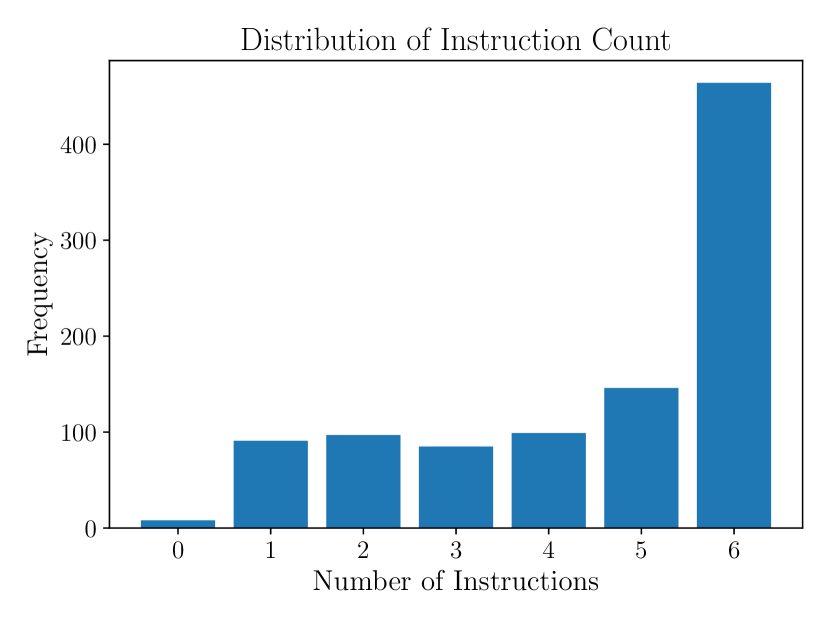
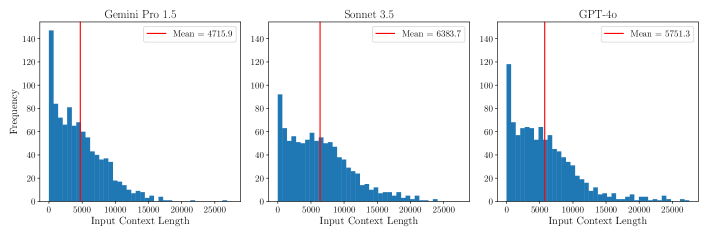
📊 实验亮点
实验结果表明,现有大型语言模型(如Gemini 1.5 Pro、GPT-4o和Claude 3.5 Sonnet)在MMMT-IF基准测试中表现出指令遵循能力随对话轮数增加而下降的趋势。PIF指标从第一轮的平均0.81下降到第20轮的0.64。当每个响应重复4次(PIF-4-4)时,GPT-4o和Gemini仅在11%的时间内成功遵循所有指令。将所有指令附加到模型输入上下文末尾后,PIF指标平均提高了22.3个百分点,表明指令检索是关键瓶颈。
🎯 应用场景
该研究成果可应用于开发更智能的对话系统、智能助手和机器人。通过使用MMMT-IF基准测试评估和改进模型的指令遵循能力,可以提升这些系统在复杂交互场景下的表现,使其能够更好地理解用户意图并执行相应的任务。未来,该基准测试可以扩展到更多模态和更复杂的指令类型,进一步推动多模态对话系统的发展。
📄 摘要(原文)
Evaluating instruction following capabilities for multimodal, multi-turn dialogue is challenging. With potentially multiple instructions in the input model context, the task is time-consuming for human raters and we show LLM based judges are biased towards answers from the same model. We propose MMMT-IF, an image based multi-turn Q$\&$A evaluation set with added global instructions between questions, constraining the answer format. This challenges models to retrieve instructions dispersed across long dialogues and reason under instruction constraints. All instructions are objectively verifiable through code execution. We introduce the Programmatic Instruction Following ($\operatorname{PIF}$) metric to measure the fraction of the instructions that are correctly followed while performing a reasoning task. The $\operatorname{PIF-N-K}$ set of metrics further evaluates robustness by measuring the fraction of samples in a corpus where, for each sample, at least K out of N generated model responses achieve a $\operatorname{PIF}$ score of one. The $\operatorname{PIF}$ metric aligns with human instruction following ratings, showing 60 percent correlation. Experiments show Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet, have a $\operatorname{PIF}$ metric that drops from 0.81 on average at turn 1 across the models, to 0.64 at turn 20. Across all turns, when each response is repeated 4 times ($\operatorname{PIF-4-4}$), GPT-4o and Gemini successfully follow all instructions only $11\%$ of the time. When all the instructions are also appended to the end of the model input context, the $\operatorname{PIF}$ metric improves by 22.3 points on average, showing that the challenge with the task lies not only in following the instructions, but also in retrieving the instructions spread out in the model context. We plan to open source the MMMT-IF dataset and metric computation code.