MaskLLM: Learnable Semi-Structured Sparsity for Large Language Models
作者: Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, Xinchao Wang
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-09-26 (更新: 2024-12-07)
备注: NeurIPS 2024 Spotlight
🔗 代码/项目: GITHUB
💡 一句话要点
MaskLLM:面向大语言模型的可学习半结构化稀疏方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 稀疏化 剪枝 半结构化稀疏 Gumbel Softmax 可学习掩码 模型压缩 推理加速
📋 核心要点
- 现有大语言模型参数冗余,推理计算开销大,需要高效的稀疏化方法。
- MaskLLM将N:M稀疏模式建模为可学习分布,通过Gumbel Softmax采样学习高质量掩码。
- 实验表明,MaskLLM在LLaMA-2、Nemotron-4和GPT-3上显著优于现有稀疏化方法,降低了困惑度。
📝 摘要(中文)
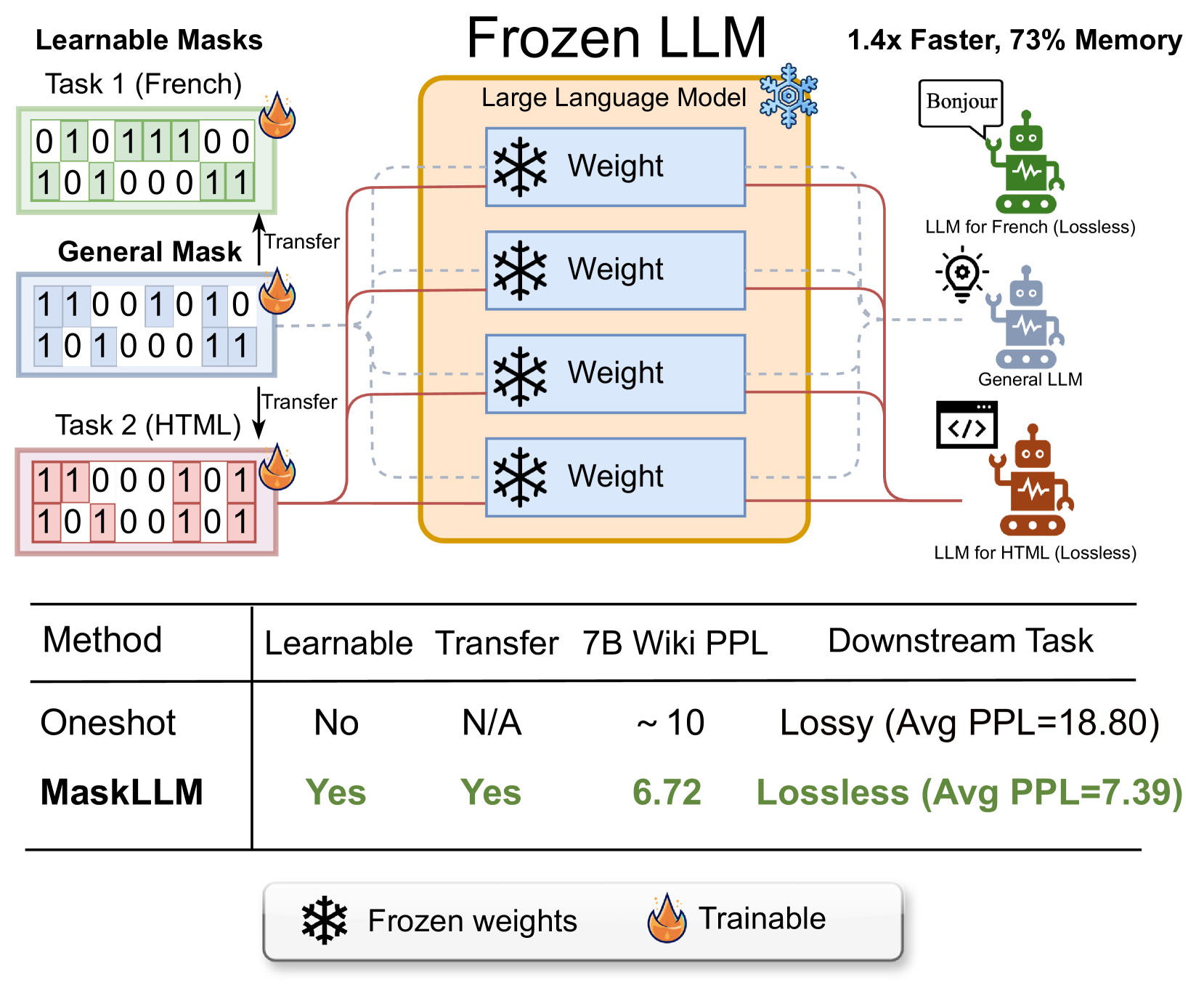
大型语言模型(LLM)以其庞大的参数量为特征,这通常导致显著的冗余。本文介绍了MaskLLM,一种可学习的剪枝方法,它在大语言模型中建立半结构化(或“N:M”)稀疏性,旨在减少推理期间的计算开销。MaskLLM没有开发新的重要性准则,而是通过Gumbel Softmax采样将N:M模式显式地建模为可学习的分布。这种方法有助于大规模数据集上的端到端训练,并提供两个显著的优势:1)高质量的掩码——我们的方法有效地扩展到大型数据集并学习准确的掩码;2)可迁移性——掩码分布的概率建模能够实现跨领域或任务的稀疏性迁移学习。我们使用2:4稀疏性在各种LLM上评估了MaskLLM,包括LLaMA-2、Nemotron-4和GPT-3,参数规模从843M到15B,我们的实验结果表明,相对于最先进的方法,MaskLLM取得了显著的改进。例如,领先的方法在Wikitext上的困惑度(PPL)达到10或更高,而密集模型的PPL为5.12,但MaskLLM仅通过学习具有冻结权重的掩码就实现了显著降低的6.72 PPL。此外,MaskLLM的可学习特性允许为下游任务或领域定制掩码,从而实现2:4稀疏性的无损应用。
🔬 方法详解
问题定义:大语言模型参数量巨大,存在大量冗余,导致推理时计算开销过高。现有的稀疏化方法,例如基于重要性准则的剪枝,难以在大规模数据集上有效学习稀疏模式,且难以迁移到不同的任务或领域。
核心思路:MaskLLM的核心思路是将N:M稀疏模式建模为一个可学习的概率分布,通过学习这个分布来确定哪些权重应该被剪枝。这种方法允许模型在训练过程中自动学习最优的稀疏模式,并且可以通过迁移学习将学到的稀疏模式应用到新的任务或领域。
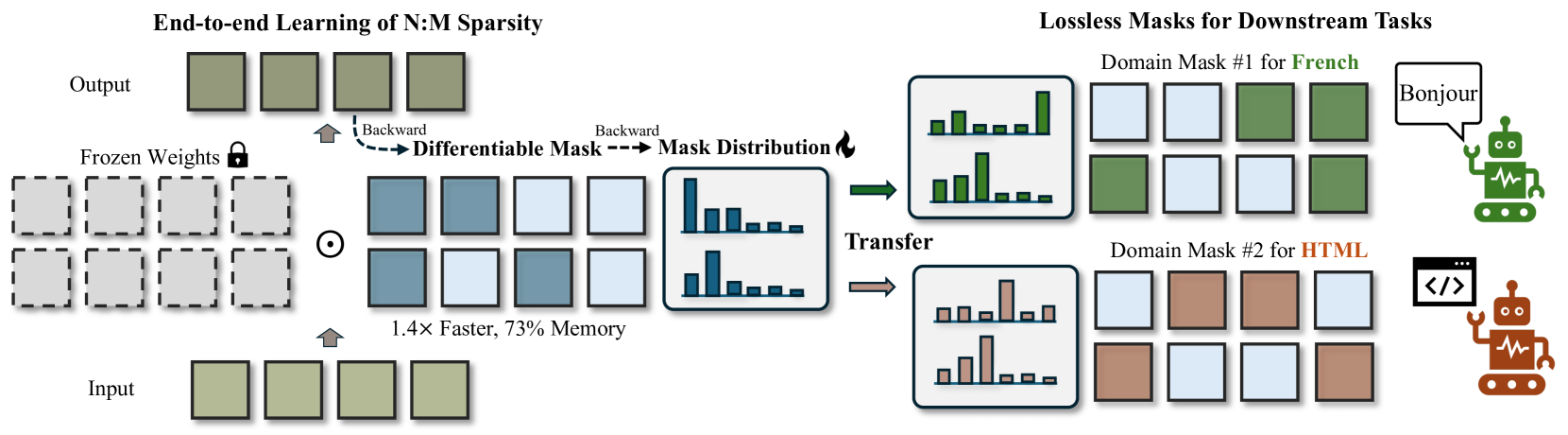
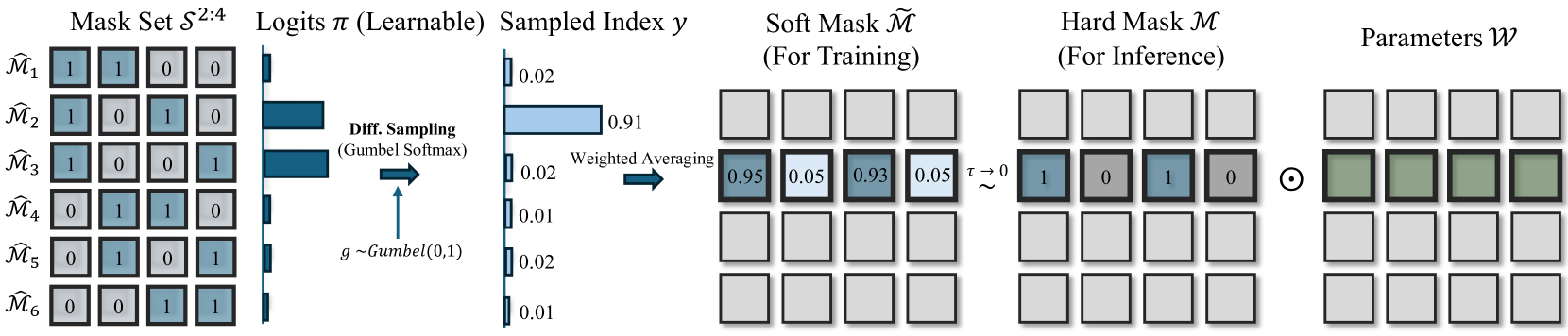
技术框架:MaskLLM的技术框架主要包括以下几个模块:1) N:M稀疏模式建模:使用一个可学习的概率分布来表示N:M稀疏模式。2) Gumbel Softmax采样:使用Gumbel Softmax采样从概率分布中生成二值掩码,用于剪枝权重。3) 端到端训练:在大型数据集上进行端到端训练,同时学习模型权重和稀疏模式。4) 迁移学习:将学到的稀疏模式迁移到新的任务或领域。
关键创新:MaskLLM最重要的技术创新点在于将N:M稀疏模式建模为一个可学习的概率分布。与传统的基于重要性准则的剪枝方法相比,MaskLLM能够更好地适应不同的任务和领域,并且能够学习到更有效的稀疏模式。
关键设计:MaskLLM的关键设计包括:1) N:M稀疏模式的概率分布:使用一个参数化的概率分布来表示N:M稀疏模式,例如,可以使用一个高斯分布或一个混合高斯分布。2) Gumbel Softmax采样的温度参数:Gumbel Softmax采样的温度参数控制了采样的随机性,需要仔细调整以获得最佳性能。3) 损失函数:使用一个损失函数来鼓励模型学习稀疏的权重,例如,可以使用L1正则化或L0正则化。
🖼️ 关键图片
📊 实验亮点
MaskLLM在LLaMA-2、Nemotron-4和GPT-3等多个大型语言模型上进行了评估,实验结果表明,MaskLLM显著优于现有的稀疏化方法。例如,在Wikitext数据集上,MaskLLM仅通过学习掩码就将困惑度从现有方法的10以上降低到6.72,接近密集模型的5.12。此外,MaskLLM还展示了良好的可迁移性,能够将学到的稀疏模式应用到新的任务和领域。
🎯 应用场景
MaskLLM可应用于各种需要高效推理的大语言模型场景,例如移动设备上的本地部署、边缘计算和低功耗设备。通过降低计算开销,MaskLLM可以使大语言模型在资源受限的环境中更易于部署和使用,并加速AI技术在各行业的落地。
📄 摘要(原文)
Large Language Models (LLMs) are distinguished by their massive parameter counts, which typically result in significant redundancy. This work introduces MaskLLM, a learnable pruning method that establishes Semi-structured (or ``N:M'') Sparsity in LLMs, aimed at reducing computational overhead during inference. Instead of developing a new importance criterion, MaskLLM explicitly models N:M patterns as a learnable distribution through Gumbel Softmax sampling. This approach facilitates end-to-end training on large-scale datasets and offers two notable advantages: 1) High-quality Masks - our method effectively scales to large datasets and learns accurate masks; 2) Transferability - the probabilistic modeling of mask distribution enables the transfer learning of sparsity across domains or tasks. We assessed MaskLLM using 2:4 sparsity on various LLMs, including LLaMA-2, Nemotron-4, and GPT-3, with sizes ranging from 843M to 15B parameters, and our empirical results show substantial improvements over state-of-the-art methods. For instance, leading approaches achieve a perplexity (PPL) of 10 or greater on Wikitext compared to the dense model's 5.12 PPL, but MaskLLM achieves a significantly lower 6.72 PPL solely by learning the masks with frozen weights. Furthermore, MaskLLM's learnable nature allows customized masks for lossless application of 2:4 sparsity to downstream tasks or domains. Code is available at https://github.com/NVlabs/MaskLLM.