Post-hoc Reward Calibration: A Case Study on Length Bias
作者: Zeyu Huang, Zihan Qiu, Zili Wang, Edoardo M. Ponti, Ivan Titov
分类: cs.AI, cs.CL
发布日期: 2024-09-25 (更新: 2025-09-21)
备注: ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出后验奖励校准方法,无需额外数据和训练即可有效缓解奖励模型中的长度偏差。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 偏差校准 后验校准 长度偏差 强化学习 大型语言模型 人类反馈 局部加权回归
📋 核心要点
- 奖励模型易受训练数据中虚假相关性影响,产生偏差,导致LLM对齐效果不佳。
- 提出后验奖励校准方法,通过估计和消除偏差项,在不增加额外数据和训练的情况下校准奖励模型。
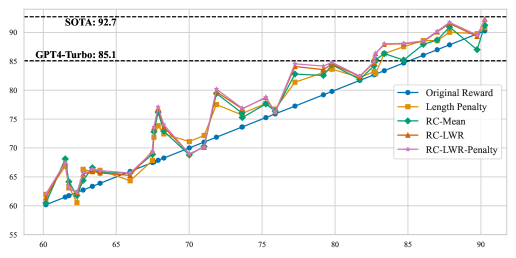
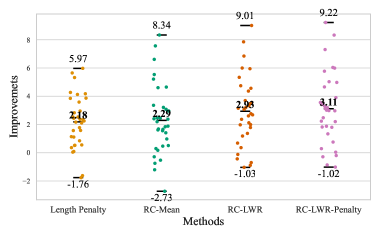
- 实验表明,该方法在多个基准测试中均能有效缓解长度偏差,提高奖励模型的性能和对齐效果。
📝 摘要(中文)
本文提出了一种后验奖励校准方法,旨在解决大型语言模型(LLM)对齐过程中奖励模型(RM)存在的偏差问题。奖励模型通过将人类反馈转化为训练信号来优化LLM的行为,但容易受到训练数据中虚假相关性的影响,例如偏好基于长度或风格而非真实质量的输出。这种偏差会导致错误的输出排序、次优的模型评估以及LLM对齐中不良行为的放大。本文的核心思想是在不增加额外数据和训练的情况下,通过估计并移除偏差项来校准奖励,从而逼近真实的奖励。进一步,将该方法扩展到更通用和鲁棒的局部加权回归形式。针对普遍存在的长度偏差,在三个实验环境中验证了所提出方法的有效性,结果表明性能得到了一致的提升:在RewardBench数据集上的33个奖励模型上平均性能提升3.11;基于AlpacaEval基准,RM排序与GPT-4评估和人类偏好的一致性得到增强;在多个LLM-RM组合中,RLHF过程的长度控制胜率得到提高。该方法计算效率高,可推广到其他类型的偏差和RM,为缓解LLM对齐中的偏差提供了一种可扩展且鲁棒的解决方案。
🔬 方法详解
问题定义:论文旨在解决奖励模型(RM)中存在的偏差问题,特别是长度偏差。现有的奖励模型容易受到训练数据中长度等虚假相关性的影响,导致模型偏好较长的回复,即使这些回复的质量不高。这种偏差会影响LLM的训练效果,使其生成冗长但质量不高的文本。现有方法通常需要额外的训练数据或复杂的模型结构来缓解偏差,成本较高。
核心思路:论文的核心思路是通过后验校准的方式,在不重新训练奖励模型的前提下,估计并消除奖励模型中的偏差项。具体来说,假设奖励模型输出的奖励值由真实奖励和偏差项组成,通过统计方法估计偏差项,并从原始奖励值中减去偏差项,从而得到校准后的奖励值。这种方法简单有效,且不需要额外的训练数据。
技术框架:该方法主要包含两个阶段:偏差估计和奖励校准。首先,利用训练数据或验证数据,分析奖励模型输出的奖励值与长度等偏差因素之间的关系,建立偏差模型。然后,利用偏差模型估计每个样本的偏差值,并从原始奖励值中减去偏差值,得到校准后的奖励值。论文提出了两种偏差估计方法:一种是直观的偏差估计方法,另一种是基于局部加权回归的更通用和鲁棒的方法。
关键创新:该论文的关键创新在于提出了后验奖励校准的概念,并设计了相应的算法。与现有方法相比,该方法不需要额外的训练数据和模型训练,计算效率高,易于实现。此外,该方法具有通用性,可以应用于不同类型的偏差和奖励模型。
关键设计:论文提出了两种偏差估计方法。第一种方法是直接估计偏差项,例如,可以将奖励值与长度之间的线性关系作为偏差模型。第二种方法是基于局部加权回归(LWR)的方法,该方法可以更灵活地建模偏差项与长度等因素之间的复杂关系。LWR方法通过对每个样本附近的样本进行加权回归,估计该样本的偏差值。论文中没有明确指出具体的损失函数或网络结构,因为该方法主要关注偏差估计和校准,而不是奖励模型的训练。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在RewardBench数据集上的33个奖励模型上平均性能提升3.11。在AlpacaEval基准测试中,校准后的奖励模型与GPT-4评估和人类偏好的一致性得到增强。在多个LLM-RM组合中,RLHF过程的长度控制胜率得到提高。这些结果表明,该方法能够有效缓解长度偏差,提高奖励模型的性能和对齐效果。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的对齐训练中,尤其是在需要利用奖励模型进行强化学习的场景下。通过消除奖励模型中的偏差,可以提高LLM生成文本的质量和安全性,使其更好地符合人类的价值观和偏好。此外,该方法还可以应用于其他机器学习模型的偏差校准,具有一定的通用性。
📄 摘要(原文)
Reinforcement Learning from Human Feedback aligns the outputs of Large Language Models with human values and preferences. Central to this process is the reward model (RM), which translates human feedback into training signals for optimising LLM behaviour. However, RMs can develop biases by exploiting spurious correlations in their training data, such as favouring outputs based on length or style rather than true quality. These biases can lead to incorrect output rankings, sub-optimal model evaluations, and the amplification of undesirable behaviours in LLMs alignment. This paper addresses the challenge of correcting such biases without additional data and training, introducing the concept of Post-hoc Reward Calibration. We first propose an intuitive approach to estimate the bias term and, thus, remove it to approximate the underlying true reward. We then extend the approach to a more general and robust form with the Locally Weighted Regression. Focusing on the prevalent length bias, we validate our proposed approaches across three experimental settings, demonstrating consistent improvements: (1) a 3.11 average performance gain across 33 reward models on the RewardBench dataset; (2) enhanced alignment of RM rankings with GPT-4 evaluations and human preferences based on the AlpacaEval benchmark; and (3) improved Length-Controlled win rate of the RLHF process in multiple LLM--RM combinations. Our method is computationally efficient and generalisable to other types of bias and RMs, offering a scalable and robust solution for mitigating biases in LLM alignment. Our code and results are available at https://github.com/ZeroYuHuang/Reward-Calibration.