AXCEL: Automated eXplainable Consistency Evaluation using LLMs
作者: P Aditya Sreekar, Sahil Verma, Suransh Chopra, Sarik Ghazarian, Abhishek Persad, Narayanan Sadagopan
分类: cs.AI, cs.CL
发布日期: 2024-09-25
💡 一句话要点
提出AXCEL,利用LLM实现自动化、可解释的一致性评估,无需特定任务提示。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 一致性评估 可解释性 自然语言推理 提示学习
📋 核心要点
- 现有文本一致性评估方法(如ROUGE、BLEU、NLI)与人类判断相关性弱,或缺乏可解释性和跨领域泛化能力。
- AXCEL提出一种基于LLM的提示方法,通过详细推理和定位不一致文本,实现自动化、可解释的一致性评估。
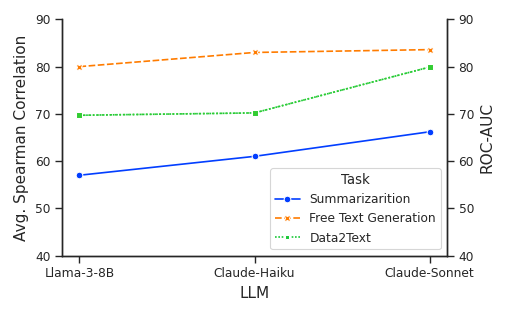
- 实验表明,AXCEL在摘要、文本生成和数据到文本任务中,显著优于现有方法,且适用于开源LLM。
📝 摘要(中文)
大型语言模型(LLMs)被广泛应用于工业界和学术界的各种任务中,但评估生成文本响应的一致性仍然是一个挑战。传统的指标如ROUGE和BLEU与人类判断的相关性较弱。使用自然语言推理(NLI)的更复杂的指标显示出更高的相关性,但实现起来很复杂,由于跨领域泛化能力差,需要特定领域的训练,并且缺乏可解释性。最近,出现了使用LLM作为评估器的基于提示的指标;虽然它们更容易实现,但仍然缺乏可解释性,并且依赖于特定任务的提示,这限制了它们的通用性。本文介绍了一种使用LLM的自动化可解释一致性评估方法(AXCEL),这是一种基于提示的一致性指标,它通过提供详细的推理和精确定位不一致的文本跨度来为一致性评分提供解释。AXCEL也是一种通用指标,可以应用于多个任务而无需更改提示。在检测摘要、自由文本生成和数据到文本转换任务中的不一致性方面,AXCEL优于非提示和基于提示的最新(SOTA)指标,分别提高了8.7%、6.2%和29.4%。我们还评估了底层LLM对基于提示的指标性能的影响,并使用最新的LLM重新校准了SOTA基于提示的指标,以进行公平的比较。此外,我们表明AXCEL在使用开源LLM时表现出强大的性能。
🔬 方法详解
问题定义:现有文本一致性评估方法,如ROUGE、BLEU等,无法准确反映人类对文本一致性的判断。基于NLI的方法虽然有所改进,但实现复杂,需要领域特定训练,且缺乏可解释性。最近出现的基于LLM提示的方法虽然易于实现,但仍然缺乏可解释性,且依赖于任务特定的提示,泛化能力不足。
核心思路:AXCEL的核心思路是利用LLM强大的推理能力,通过精心设计的提示,让LLM对文本的一致性进行判断,并给出判断的理由和不一致的具体位置。这种方法无需针对特定任务进行训练,具有良好的通用性和可解释性。
技术框架:AXCEL的整体框架包括以下几个步骤:1. 输入待评估的文本;2. 使用预定义的提示,将文本输入LLM;3. LLM根据提示,生成对文本一致性的判断,包括一致性得分、推理过程和不一致文本的位置;4. 输出一致性得分、推理过程和不一致文本的位置,作为评估结果。
关键创新:AXCEL的关键创新在于其通用性和可解释性。它使用统一的提示,可以应用于不同的任务,而无需针对每个任务进行调整。同时,它通过提供推理过程和不一致文本的位置,使得评估结果具有良好的可解释性。
关键设计:AXCEL的关键设计在于提示的设计。提示需要引导LLM进行一致性判断,并提供推理过程和不一致文本的位置。具体的提示内容未知,但根据论文描述,提示的设计目标是通用性和可解释性。
🖼️ 关键图片


📊 实验亮点
AXCEL在三个任务上显著优于现有方法:在摘要任务上提升8.7%,在自由文本生成任务上提升6.2%,在数据到文本转换任务上提升29.4%。此外,论文还验证了AXCEL在使用开源LLM时仍然表现出强大的性能,这表明AXCEL具有良好的通用性和实用性。
🎯 应用场景
AXCEL可应用于各种需要评估文本一致性的场景,例如机器翻译、文本摘要、对话系统、内容生成等。它可以帮助开发者快速评估模型的输出质量,提高模型的可靠性和可信度。未来,AXCEL可以进一步扩展到评估多模态内容的一致性,例如图像和文本的一致性。
📄 摘要(原文)
Large Language Models (LLMs) are widely used in both industry and academia for various tasks, yet evaluating the consistency of generated text responses continues to be a challenge. Traditional metrics like ROUGE and BLEU show a weak correlation with human judgment. More sophisticated metrics using Natural Language Inference (NLI) have shown improved correlations but are complex to implement, require domain-specific training due to poor cross-domain generalization, and lack explainability. More recently, prompt-based metrics using LLMs as evaluators have emerged; while they are easier to implement, they still lack explainability and depend on task-specific prompts, which limits their generalizability. This work introduces Automated eXplainable Consistency Evaluation using LLMs (AXCEL), a prompt-based consistency metric which offers explanations for the consistency scores by providing detailed reasoning and pinpointing inconsistent text spans. AXCEL is also a generalizable metric which can be adopted to multiple tasks without changing the prompt. AXCEL outperforms both non-prompt and prompt-based state-of-the-art (SOTA) metrics in detecting inconsistencies across summarization by 8.7%, free text generation by 6.2%, and data-to-text conversion tasks by 29.4%. We also evaluate the influence of underlying LLMs on prompt based metric performance and recalibrate the SOTA prompt-based metrics with the latest LLMs for fair comparison. Further, we show that AXCEL demonstrates strong performance using open source LLMs.