StateAct: Enhancing LLM Base Agents via Self-prompting and State-tracking
作者: Nikolai Rozanov, Marek Rei
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-09-21 (更新: 2025-04-08)
备注: 9 pages, 5 pages appendix, 7 figures, 5 tables
🔗 代码/项目: GITHUB
💡 一句话要点
StateAct:通过自提示和状态追踪增强LLM基础Agent
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 自主Agent 长上下文推理 状态追踪 自提示 链式思考 决策制定
📋 核心要点
- 现有LLM Agent在长上下文推理和持续目标导向方面面临挑战,限制了其在复杂任务中的应用。
- StateAct通过自提示机制强化每一步的任务目标,并利用链式状态追踪长期状态变化,提升决策质量。
- 实验表明,StateAct在多个任务上显著优于ReAct等基线方法,且能与高级Agent方法结合进一步提升性能。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用作自主Agent,处理从机器人到Web导航等任务。它们的性能取决于底层的基础Agent。然而,现有方法在长上下文推理和目标坚持方面存在困难。我们引入了StateAct,一种新颖而高效的基础Agent,它通过(1)自提示(在每个步骤中强化任务目标)和(2)链式状态(chain-of-states,链式思考的扩展,随时间跟踪状态信息)来增强决策能力。在多个前沿LLM上,StateAct在Alfworld上优于之前的最佳基础Agent ReAct超过10%,在Textcraft上超过30%,在Webshop上超过7%。我们还证明了StateAct可以作为ReAct的直接替代品,用于高级LLM Agent方法,例如测试时缩放,从而在Textcraft上获得额外的12%的收益。通过提高效率和长程推理能力,而无需额外的训练或检索,StateAct为LLM Agent提供了一个可扩展的基础。我们开源了我们的代码,以支持进一步的研究,地址为https://github.com/ai-nikolai/stateact。
🔬 方法详解
问题定义:现有基于LLM的Agent在处理需要长期记忆和推理的任务时,容易偏离目标,并且难以有效利用上下文信息。ReAct等方法虽然引入了行动和观察的交替,但在复杂环境中仍然面临状态追踪不准确和目标强化不足的问题。
核心思路:StateAct的核心思路是通过显式地维护和更新Agent的状态信息,并在每一步决策时利用自提示机制强化任务目标,从而提高Agent的长期推理能力和目标导向性。这种方法旨在克服现有方法在长上下文推理和目标坚持方面的不足。
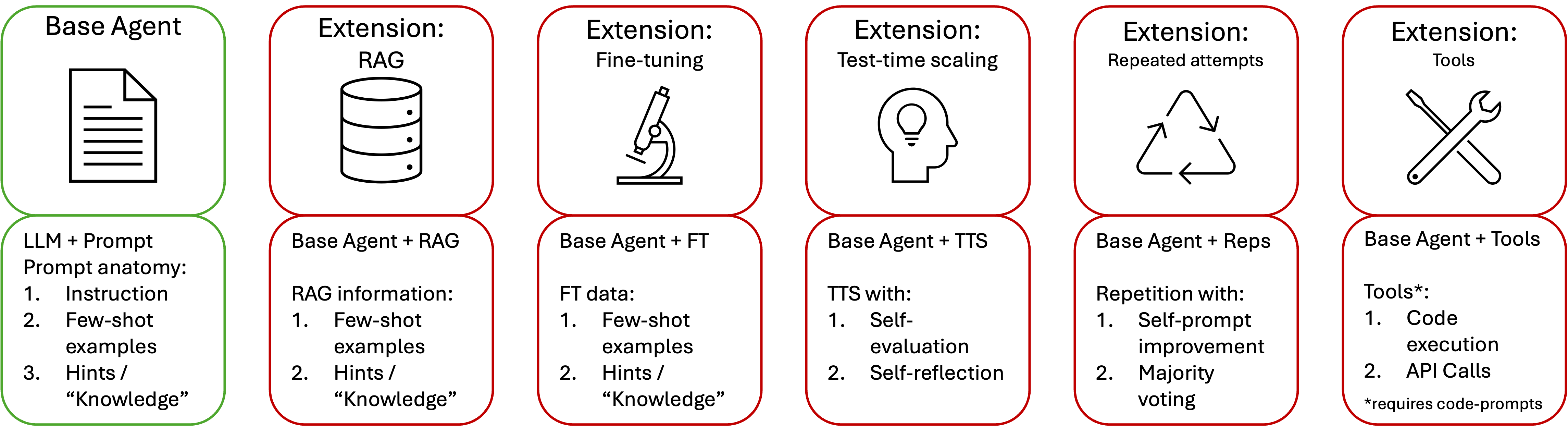
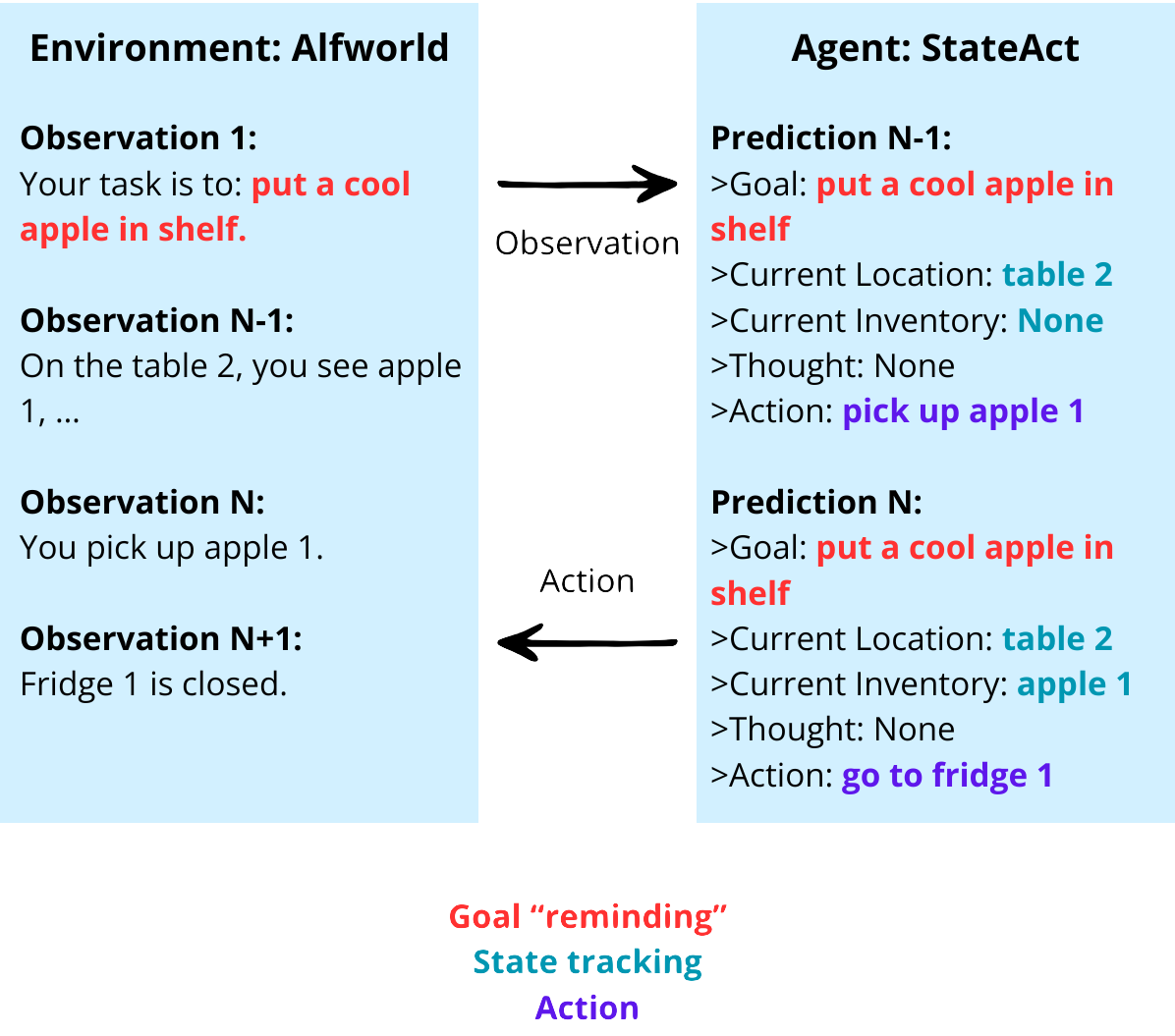
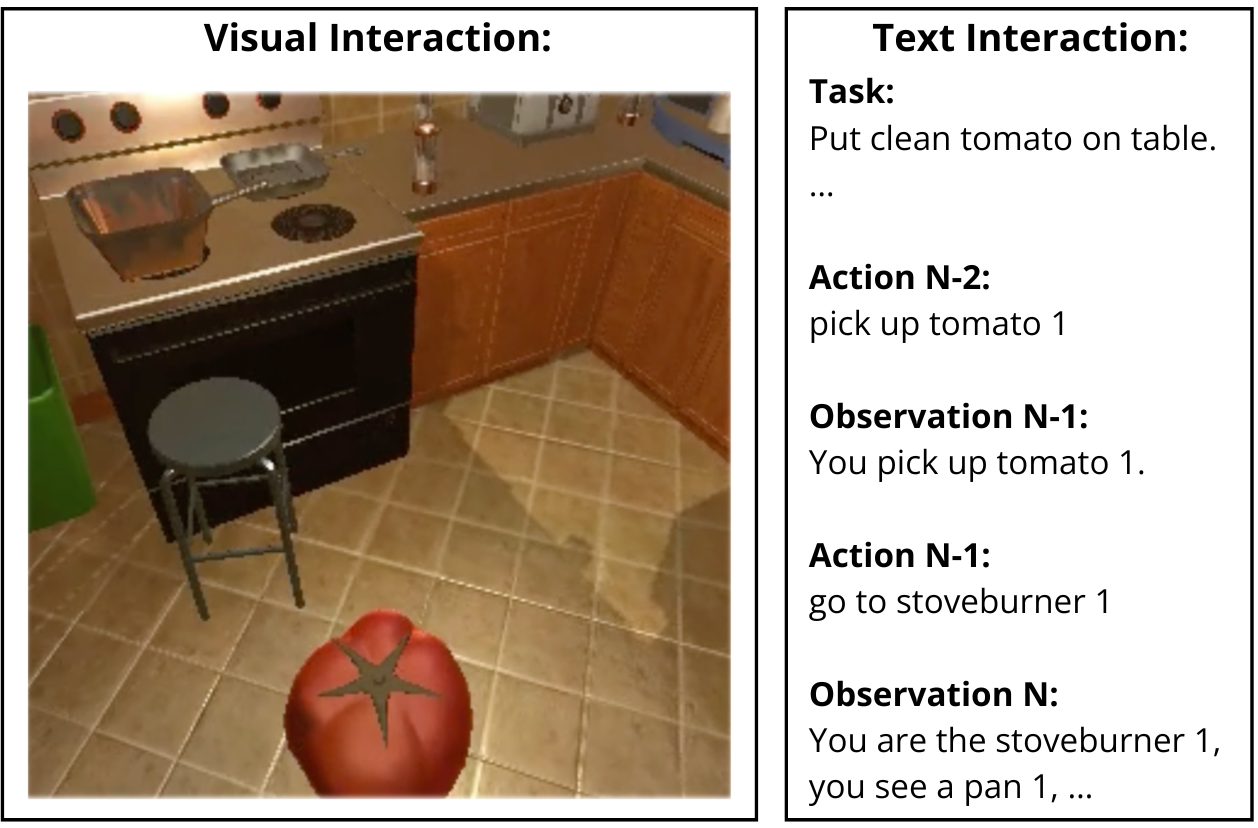
技术框架:StateAct的整体框架基于标准的LLM Agent架构,主要包含三个阶段:观察(Observation)、思考(State-tracking & Self-prompting)和行动(Action)。与ReAct不同的是,StateAct在思考阶段引入了链式状态(Chain-of-States)和自提示(Self-Prompting)机制。链式状态用于记录和更新Agent的状态信息,自提示则用于在每一步决策前,将任务目标和当前状态信息显式地添加到LLM的输入中。
关键创新:StateAct的关键创新在于链式状态和自提示机制的结合。链式状态通过维护一个状态列表,记录Agent在环境中的行动和观察,从而提供更丰富的上下文信息。自提示则通过在每一步决策前,将任务目标和当前状态信息显式地添加到LLM的输入中,从而强化Agent的目标导向性。
关键设计:StateAct的关键设计包括状态信息的表示方式和自提示的prompt模板。状态信息可以采用自然语言描述或结构化表示,自提示的prompt模板需要包含任务目标、当前状态信息和下一步行动的指导。论文中没有明确提及具体的参数设置或损失函数,因为StateAct主要关注的是Agent的推理框架,而不是LLM的训练。
🖼️ 关键图片
📊 实验亮点
StateAct在Alfworld、Textcraft和Webshop等任务上显著优于ReAct。具体来说,在Alfworld上提升超过10%,在Textcraft上提升超过30%,在Webshop上提升超过7%。此外,StateAct可以作为ReAct的直接替代品,与测试时缩放等高级LLM Agent方法结合,在Textcraft上获得额外的12%的收益。这些结果表明StateAct具有很强的通用性和可扩展性。
🎯 应用场景
StateAct的潜在应用领域包括机器人控制、Web导航、游戏AI和智能助手等。通过提高LLM Agent的长期推理能力和目标导向性,StateAct可以帮助Agent更好地完成复杂的任务,例如在虚拟环境中进行物品搜索和操作,或者在Web上完成信息收集和预订等任务。该研究的实际价值在于提供了一种更有效的基础Agent框架,可以促进LLM Agent在更多领域的应用。未来,StateAct可以与其他先进的Agent技术结合,进一步提升Agent的性能。
📄 摘要(原文)
Large language models (LLMs) are increasingly used as autonomous agents, tackling tasks from robotics to web navigation. Their performance depends on the underlying base agent. Existing methods, however, struggle with long-context reasoning and goal adherence. We introduce StateAct, a novel and efficient base agent that enhances decision-making through (1) self-prompting, which reinforces task goals at every step, and (2) chain-of-states, an extension of chain-of-thought that tracks state information over time. StateAct outperforms ReAct, the previous best base agent, by over 10% on Alfworld, 30% on Textcraft, and 7% on Webshop across multiple frontier LLMs. We also demonstrate that StateAct can be used as a drop-in replacement for ReAct with advanced LLM agent methods such as test-time scaling, yielding an additional 12% gain on Textcraft. By improving efficiency and long-range reasoning without requiring additional training or retrieval, StateAct provides a scalable foundation for LLM agents. We open source our code to support further research at https://github.com/ai-nikolai/stateact .