A Survey on Multimodal Benchmarks: In the Era of Large AI Models
作者: Lin Li, Guikun Chen, Hanrong Shi, Jun Xiao, Long Chen
分类: cs.AI, cs.MM
发布日期: 2024-09-21
备注: Ongoing project
💡 一句话要点
综述性分析多模态大模型评测基准,促进多模态人工智能发展
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 基准测试 模型评估 人工智能
📋 核心要点
- 现有研究主要集中于多模态大模型的架构和训练,缺乏对评估基准的系统性分析。
- 本研究通过系统回顾211个基准,深入分析任务设计、评估指标和数据集构建,填补了这一空白。
- 该综述旨在为多模态大模型研究提供全面的基准测试实践概述,并为未来研究方向提供参考。
📝 摘要(中文)
多模态大语言模型(MLLMs)的快速发展极大地推动了人工智能的进步,显著增强了理解和生成多模态内容的能力。虽然之前的研究主要集中在模型架构和训练方法上,但对用于评估这些模型的基准的全面分析仍然不足。本综述旨在弥补这一差距,系统地回顾了211个评估MLLM在理解、推理、生成和应用四个核心领域的基准。我们对跨不同模态的任务设计、评估指标和数据集构建进行了详细分析。我们希望本综述通过提供基准测试实践的全面概述,并确定未来工作的有希望的方向,为正在进行的多模态大语言模型研究做出贡献。相关的GitHub仓库收集了最新的论文。
🔬 方法详解
问题定义:当前多模态大语言模型(MLLMs)的研究热点主要集中在模型架构和训练方法上,而对用于评估这些模型的基准数据集的系统性分析相对不足。这导致研究者难以全面了解现有模型的优缺点,也阻碍了新模型的有效评估和比较。因此,亟需对现有的多模态基准进行梳理和分析,为后续研究提供指导。
核心思路:本研究的核心思路是通过大规模的文献调研,系统性地收集并分析现有的多模态基准数据集。通过对这些基准数据集的任务设计、评估指标和数据集构建方法进行深入剖析,总结出当前多模态评估的现状和挑战,并为未来的基准数据集设计提供参考。
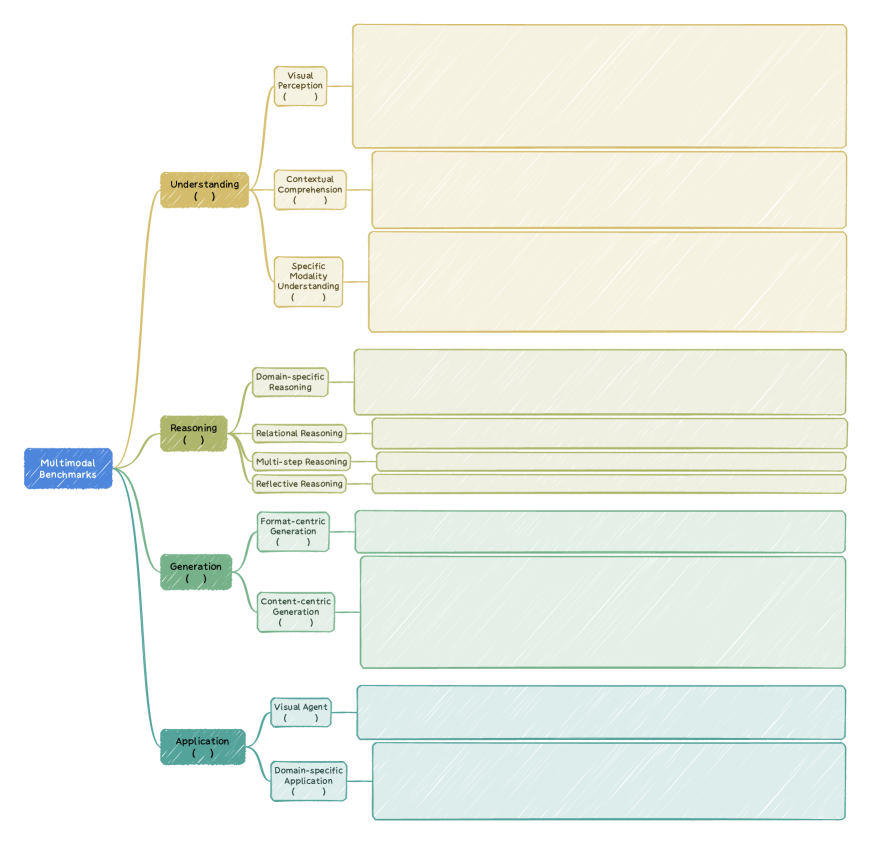
技术框架:本研究采用文献综述的方法,主要分为以下几个阶段:1) 确定研究范围,即多模态大语言模型的评估基准;2) 通过学术数据库和相关网站,收集相关的论文和数据集;3) 对收集到的基准数据集进行分类,按照理解、推理、生成和应用四个核心领域进行划分;4) 对每个基准数据集的任务设计、评估指标和数据集构建方法进行详细分析;5) 总结当前多模态评估的现状和挑战,并提出未来的研究方向。
关键创新:本研究的关键创新在于对多模态大语言模型评估基准的全面性和系统性分析。以往的研究往往只关注少数几个基准数据集,而本研究覆盖了211个基准,提供了更全面的视角。此外,本研究还对基准数据集的任务设计、评估指标和数据集构建方法进行了深入剖析,为未来的基准数据集设计提供了更具体的指导。
关键设计:本研究的关键设计在于对基准数据集的分类方式,即按照理解、推理、生成和应用四个核心领域进行划分。这种分类方式能够更清晰地反映不同基准数据集的侧重点,也方便研究者根据自己的研究方向选择合适的基准数据集。此外,本研究还关注了不同模态的数据集构建方法,例如图像、文本、音频和视频等,并分析了不同模态之间的关系。
🖼️ 关键图片
📊 实验亮点
该综述系统性地回顾了211个用于评估多模态大语言模型的基准,涵盖理解、推理、生成和应用四个核心领域。论文详细分析了任务设计、评估指标和数据集构建,为研究人员提供了全面的基准测试实践概述,并指出了未来研究的潜在方向。
🎯 应用场景
该研究成果可应用于多模态人工智能模型的开发与评估,帮助研究人员更好地理解和比较不同模型的性能。同时,该综述为多模态基准数据集的设计提供了指导,促进了相关数据集的构建和完善。最终,这将推动多模态人工智能技术在智能问答、图像生成、视频理解等领域的应用。
📄 摘要(原文)
The rapid evolution of Multimodal Large Language Models (MLLMs) has brought substantial advancements in artificial intelligence, significantly enhancing the capability to understand and generate multimodal content. While prior studies have largely concentrated on model architectures and training methodologies, a thorough analysis of the benchmarks used for evaluating these models remains underexplored. This survey addresses this gap by systematically reviewing 211 benchmarks that assess MLLMs across four core domains: understanding, reasoning, generation, and application. We provide a detailed analysis of task designs, evaluation metrics, and dataset constructions, across diverse modalities. We hope that this survey will contribute to the ongoing advancement of MLLM research by offering a comprehensive overview of benchmarking practices and identifying promising directions for future work. An associated GitHub repository collecting the latest papers is available.