PathSeeker: Exploring LLM Security Vulnerabilities with a Reinforcement Learning-Based Jailbreak Approach
作者: Zhihao Lin, Wei Ma, Mingyi Zhou, Yanjie Zhao, Haoyu Wang, Yang Liu, Jun Wang, Li Li
分类: cs.CR, cs.AI
发布日期: 2024-09-21 (更新: 2024-10-03)
备注: update the abstract and cite a new related work
💡 一句话要点
PathSeeker:一种基于强化学习的越狱方法,用于探索LLM安全漏洞
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全漏洞 越狱攻击 强化学习 多智能体系统
📋 核心要点
- 现有越狱攻击方法依赖模型内部信息或探索不安全行为时存在局限性,通用性不足。
- PathSeeker将LLM视为“安全迷宫”,利用多智能体强化学习引导LLM变异输入,寻找越狱路径。
- 实验表明,PathSeeker在多个LLM上优于现有攻击方法,尤其在强对齐商业模型上攻击成功率高。
📝 摘要(中文)
近年来,大型语言模型(LLMs)得到广泛应用,其安全性问题日益突出。传统的越狱攻击通常依赖模型内部信息,或者在探索目标模型的不安全行为时存在局限性,从而限制了它们的通用性。本文提出PathSeeker,一种新颖的黑盒越狱方法,其灵感来源于老鼠逃离迷宫的游戏。我们将每个LLM视为一个独特的“安全迷宫”,攻击者试图通过学习接收到的反馈和积累的经验来找到出口,从而攻破目标LLM的安全防御。我们的方法利用多智能体强化学习,其中较小的模型协同引导主LLM执行变异操作以实现攻击目标。通过基于模型反馈逐步修改输入,我们的系统诱导出更丰富、更有害的响应。在手动尝试执行越狱攻击期间,我们发现目标模型响应的词汇逐渐变得更加丰富,并最终产生有害响应。基于这一观察,我们还引入了一种奖励机制,该机制利用LLM响应中词汇丰富度的扩展来削弱安全约束。在13个商业和开源LLM上进行的测试表明,我们的方法优于五种最先进的攻击技术,实现了高攻击成功率,尤其是在像GPT-4o-mini、Claude-3.5和GLM-4-air这样具有强大安全对齐的商业模型中。本研究旨在提高对LLM安全漏洞的理解,我们希望这项研究能够为开发更强大的防御措施做出贡献。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的安全性问题,特别是如何有效地进行越狱攻击,绕过LLM的安全防御机制。现有方法通常依赖于模型内部信息(白盒攻击)或在探索不安全行为时存在局限性,导致通用性较差,难以应对不断增强的LLM安全对齐。
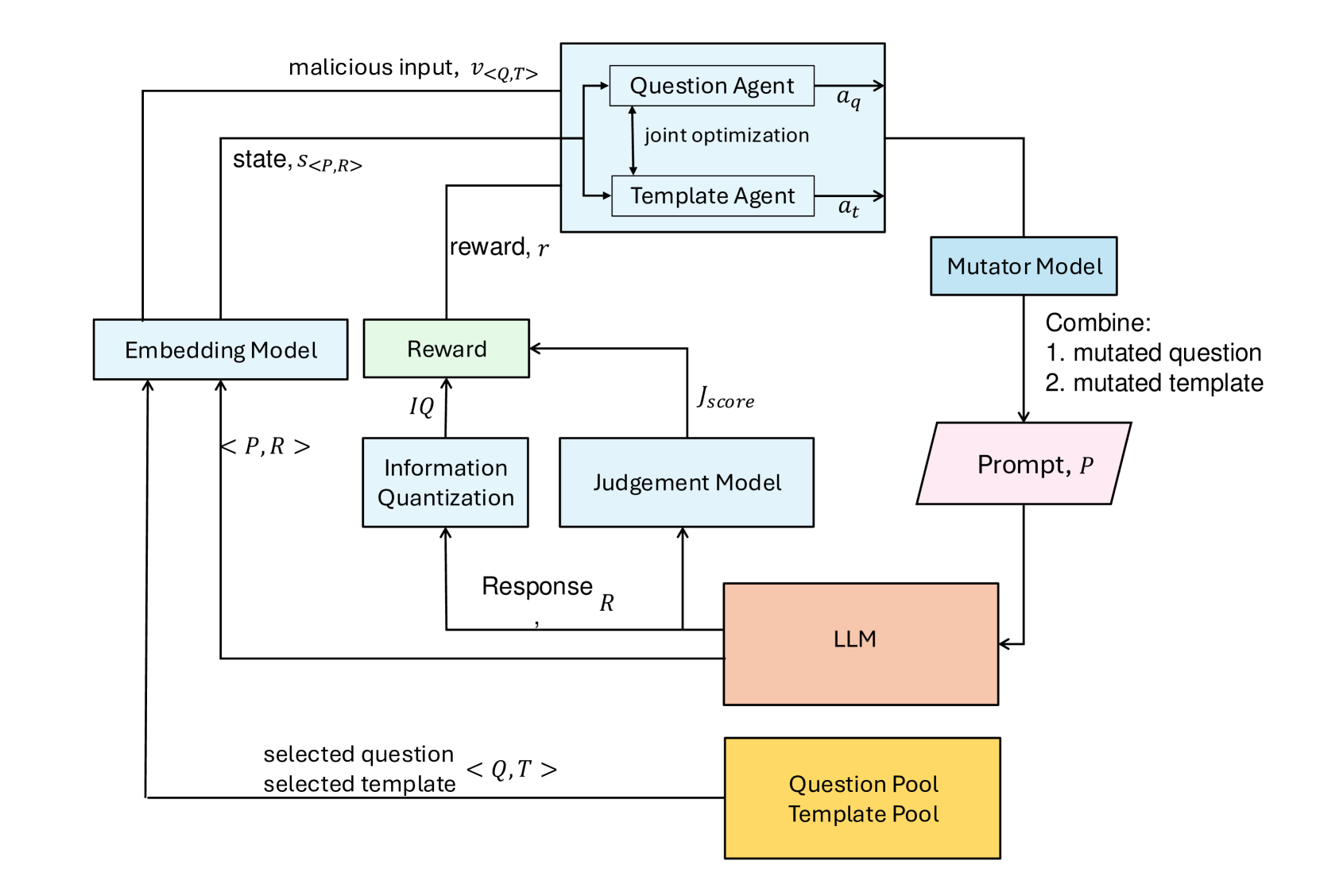
核心思路:论文的核心思路是将LLM的安全性防御视为一个“安全迷宫”,攻击者的目标是找到从迷宫中逃脱的路径(即成功越狱)。通过模仿老鼠逃离迷宫的过程,利用强化学习让智能体在与LLM的交互中学习,逐步探索并发现LLM的漏洞。这种黑盒攻击方式不依赖于模型内部信息,更具通用性和实用性。
技术框架:PathSeeker采用多智能体强化学习框架。整体流程如下:1) 初始化:构建一个主LLM和多个辅助LLM智能体。2) 交互:辅助智能体生成变异操作,作用于输入提示词,主LLM根据变异后的提示词生成响应。3) 奖励:根据主LLM的响应,计算奖励信号,包括攻击成功率和词汇丰富度。4) 学习:辅助智能体根据奖励信号更新策略,优化变异操作。重复2-4步,直到达到攻击目标或达到最大迭代次数。
关键创新:PathSeeker的关键创新在于:1) 将LLM越狱问题建模为迷宫探索问题,提供了一种新的攻击视角。2) 采用多智能体强化学习,利用多个智能体协同探索攻击策略,提高了攻击效率和成功率。3) 引入基于词汇丰富度的奖励机制,鼓励生成更具多样性和潜在危害性的响应,有效削弱安全约束。
关键设计:PathSeeker的关键设计包括:1) 变异操作:辅助智能体负责生成各种变异操作,如插入、替换、删除等,以改变输入提示词。2) 奖励函数:奖励函数综合考虑攻击成功率和词汇丰富度,其中词汇丰富度通过计算响应中不同词的数量来衡量。3) 强化学习算法:采用合适的强化学习算法(如Proximal Policy Optimization, PPO)训练辅助智能体,使其能够根据LLM的反馈自适应地调整变异策略。
🖼️ 关键图片


📊 实验亮点
PathSeeker在13个商业和开源LLM上进行了测试,实验结果表明,PathSeeker优于五种最先进的攻击技术,尤其是在像GPT-4o-mini、Claude-3.5和GLM-4-air这样具有强大安全对齐的商业模型中,实现了更高的攻击成功率。具体数据未知,但强调了其在强对齐模型上的优势。
🎯 应用场景
PathSeeker的研究成果可应用于评估和提升大型语言模型的安全性。通过发现LLM的安全漏洞,可以帮助开发者及时修复漏洞,提高模型的鲁棒性,防止恶意利用。此外,该方法还可以用于构建更安全的LLM应用,例如聊天机器人、智能助手等,降低潜在的安全风险。
📄 摘要(原文)
In recent years, Large Language Models (LLMs) have gained widespread use, raising concerns about their security. Traditional jailbreak attacks, which often rely on the model internal information or have limitations when exploring the unsafe behavior of the victim model, limiting their reducing their general applicability. In this paper, we introduce PathSeeker, a novel black-box jailbreak method, which is inspired by the game of rats escaping a maze. We think that each LLM has its unique "security maze", and attackers attempt to find the exit learning from the received feedback and their accumulated experience to compromise the target LLM's security defences. Our approach leverages multi-agent reinforcement learning, where smaller models collaborate to guide the main LLM in performing mutation operations to achieve the attack objectives. By progressively modifying inputs based on the model's feedback, our system induces richer, harmful responses. During our manual attempts to perform jailbreak attacks, we found that the vocabulary of the response of the target model gradually became richer and eventually produced harmful responses. Based on the observation, we also introduce a reward mechanism that exploits the expansion of vocabulary richness in LLM responses to weaken security constraints. Our method outperforms five state-of-the-art attack techniques when tested across 13 commercial and open-source LLMs, achieving high attack success rates, especially in strongly aligned commercial models like GPT-4o-mini, Claude-3.5, and GLM-4-air with strong safety alignment. This study aims to improve the understanding of LLM security vulnerabilities and we hope that this sturdy can contribute to the development of more robust defenses.