Autoformalization of Game Descriptions using Large Language Models
作者: Agnieszka Mensfelt, Kostas Stathis, Vince Trencsenyi
分类: cs.AI, cs.GT
发布日期: 2024-09-18
备注: code: https://github.com/dicelab-rhul/game-formaliser
💡 一句话要点
提出基于大语言模型的博弈论场景自动形式化框架,提升形式推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动形式化 大语言模型 博弈论 形式推理 自然语言处理
📋 核心要点
- 现有博弈论场景通常以自然语言描述,难以直接应用形式推理工具进行分析。
- 利用大语言模型的代码生成能力,结合求解器的反馈,迭代优化自然语言描述到形式逻辑的转换。
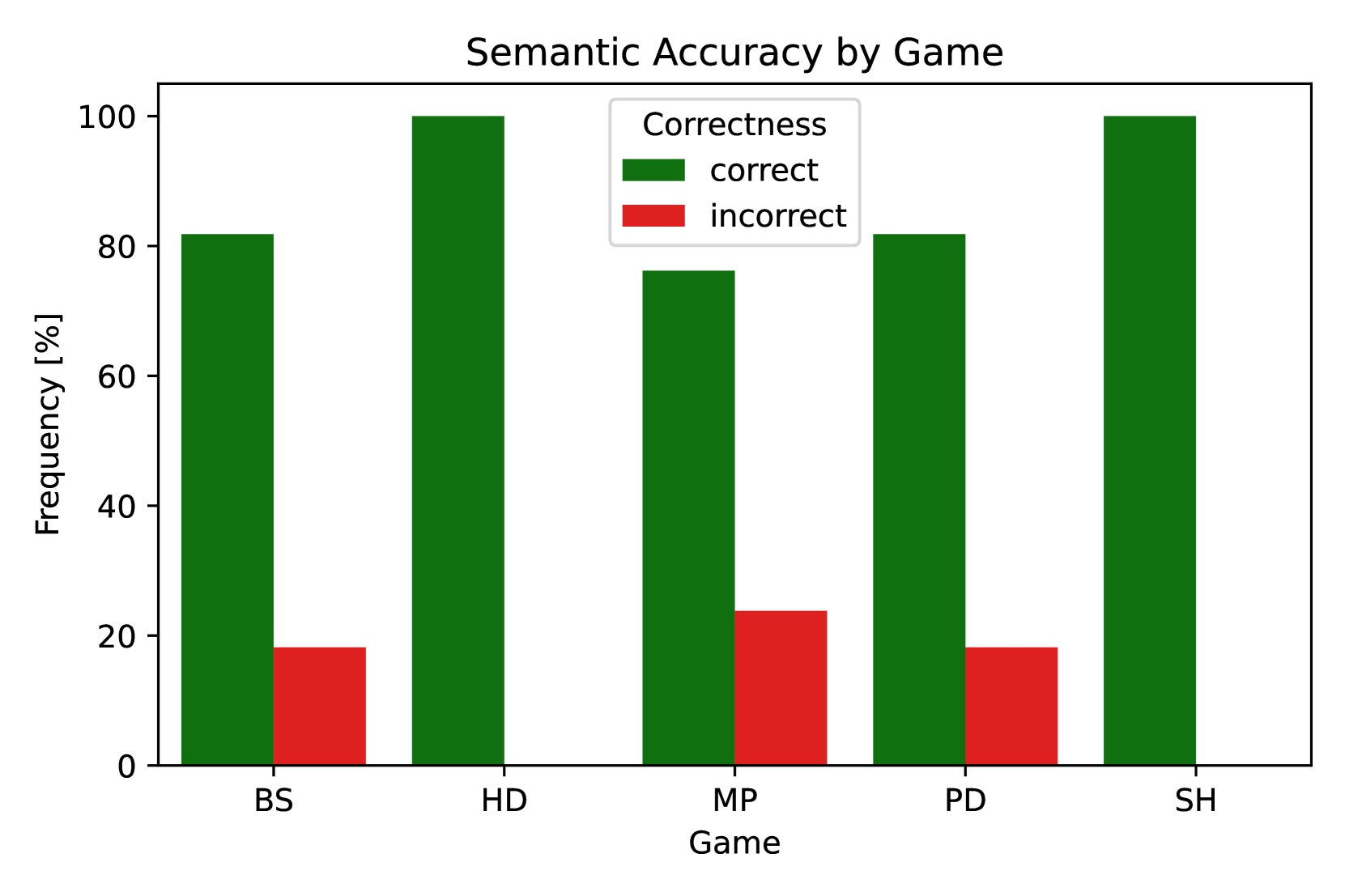
- 实验表明,该框架在博弈论场景的形式化任务中取得了显著的语法和语义正确率,验证了其有效性。
📝 摘要(中文)
本文提出了一种博弈论场景自动形式化的框架,旨在将自然语言描述转化为适用于形式求解器的形式逻辑表示。该方法利用单样本提示(one-shot prompting)和一个能提供语法正确性反馈的求解器,使大语言模型(LLMs)能够改进代码。使用GPT-4o在一个自然语言问题描述数据集上评估该框架,实现了98%的语法正确性和88%的语义正确性。结果表明,大语言模型有潜力弥合现实战略互动与形式推理之间的差距。
🔬 方法详解
问题定义:论文旨在解决将自然语言描述的博弈论场景自动转化为形式逻辑表示的问题。现有方法难以处理自然语言的模糊性和多样性,导致无法直接应用形式求解器进行推理和分析。这限制了博弈论在现实世界战略互动中的应用。
核心思路:论文的核心思路是利用大语言模型强大的自然语言理解和代码生成能力,将自然语言描述转化为形式逻辑代码。通过求解器提供的语法正确性反馈,迭代优化大语言模型的输出,提高形式化结果的准确性。
技术框架:该框架主要包含两个核心模块:一是基于单样本提示的大语言模型(LLM),负责将自然语言描述转化为形式逻辑代码;二是形式求解器,用于验证LLM生成的代码的语法正确性,并提供反馈。LLM根据求解器的反馈进行迭代优化,直到生成符合要求的形式逻辑代码。
关键创新:该方法最重要的创新点在于利用求解器的反馈来指导大语言模型的代码生成过程。这种迭代优化的方式能够显著提高形式化结果的语法和语义正确性,克服了传统方法中自然语言理解的难题。
关键设计:论文采用单样本提示(one-shot prompting)来引导大语言模型生成代码。求解器提供的反馈信息包括语法错误类型和位置等。大语言模型根据这些反馈信息,调整代码生成策略,例如修改变量命名、调整逻辑结构等。具体的大语言模型采用GPT-4o,求解器类型未明确说明,但需要具备语法检查功能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用GPT-4o的框架在博弈论场景的形式化任务中取得了显著的成果,实现了98%的语法正确性和88%的语义正确性。这些结果验证了该框架的有效性,并表明大语言模型在弥合现实战略互动与形式推理之间的差距方面具有巨大潜力。
🎯 应用场景
该研究成果可应用于自动化博弈论分析、智能决策支持系统、以及人机协作的战略规划等领域。通过自动将自然语言描述的战略场景转化为形式逻辑,可以帮助决策者更好地理解复杂局势,并利用形式推理工具进行优化决策。未来,该技术有望应用于国际关系、商业谈判、以及日常人际互动等领域。
📄 摘要(原文)
Game theory is a powerful framework for reasoning about strategic interactions, with applications in domains ranging from day-to-day life to international politics. However, applying formal reasoning tools in such contexts is challenging, as these scenarios are often expressed in natural language. To address this, we introduce a framework for the autoformalization of game-theoretic scenarios, which translates natural language descriptions into formal logic representations suitable for formal solvers. Our approach utilizes one-shot prompting and a solver that provides feedback on syntactic correctness to allow LLMs to refine the code. We evaluate the framework using GPT-4o and a dataset of natural language problem descriptions, achieving 98% syntactic correctness and 88% semantic correctness. These results show the potential of LLMs to bridge the gap between real-life strategic interactions and formal reasoning.