RAG-Modulo: Solving Sequential Tasks using Experience, Critics, and Language Models
作者: Abhinav Jain, Chris Jermaine, Vaibhav Unhelkar
分类: cs.AI, cs.CL, cs.LG, cs.RO
发布日期: 2024-09-18
备注: 8 pages, 5 figures
💡 一句话要点
RAG-Modulo:利用经验、评论和语言模型解决序列任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器人 序列决策 经验学习 检索增强生成
📋 核心要点
- 现有基于LLM的机器人智能体缺乏从过去交互中学习的能力,限制了其在复杂任务中的表现。
- RAG-Modulo框架通过引入记忆模块,使智能体能够检索和利用相关历史经验进行决策,实现上下文感知的学习。
- 实验表明,RAG-Modulo在BabyAI和AlfWorld等任务中显著提升了成功率和效率,超越了现有技术水平。
📝 摘要(中文)
大型语言模型(LLMs)已成为解决复杂机器人任务的有力工具,即使在存在动作和观察不确定性的情况下也是如此。最近基于LLM的决策方法(也称为基于LLM的智能体),与适当的评论家结合使用时,已显示出解决复杂、长时程任务的潜力,且交互次数相对较少。然而,大多数现有的基于LLM的智能体缺乏保留和学习过去交互的能力——这是基于学习的机器人系统的基本特征。我们提出了RAG-Modulo,一个增强基于LLM的智能体的框架,使其具有过去交互的记忆,并结合评论家来评估智能体的决策。记忆组件允许智能体自动检索和整合相关的过去经验作为上下文示例,为更明智的决策提供上下文感知的反馈。此外,通过更新其记忆,智能体随着时间的推移提高其性能,从而表现出学习能力。通过在具有挑战性的BabyAI和AlfWorld领域中的实验,我们证明了任务成功率和效率的显着提高,表明所提出的RAG-Modulo框架优于最先进的基线。
🔬 方法详解
问题定义:论文旨在解决基于LLM的机器人智能体在序列决策任务中缺乏从历史经验中学习的问题。现有方法通常忽略了过去交互的信息,导致智能体无法根据环境变化和自身行为进行有效调整,从而限制了其在复杂、长时程任务中的表现。
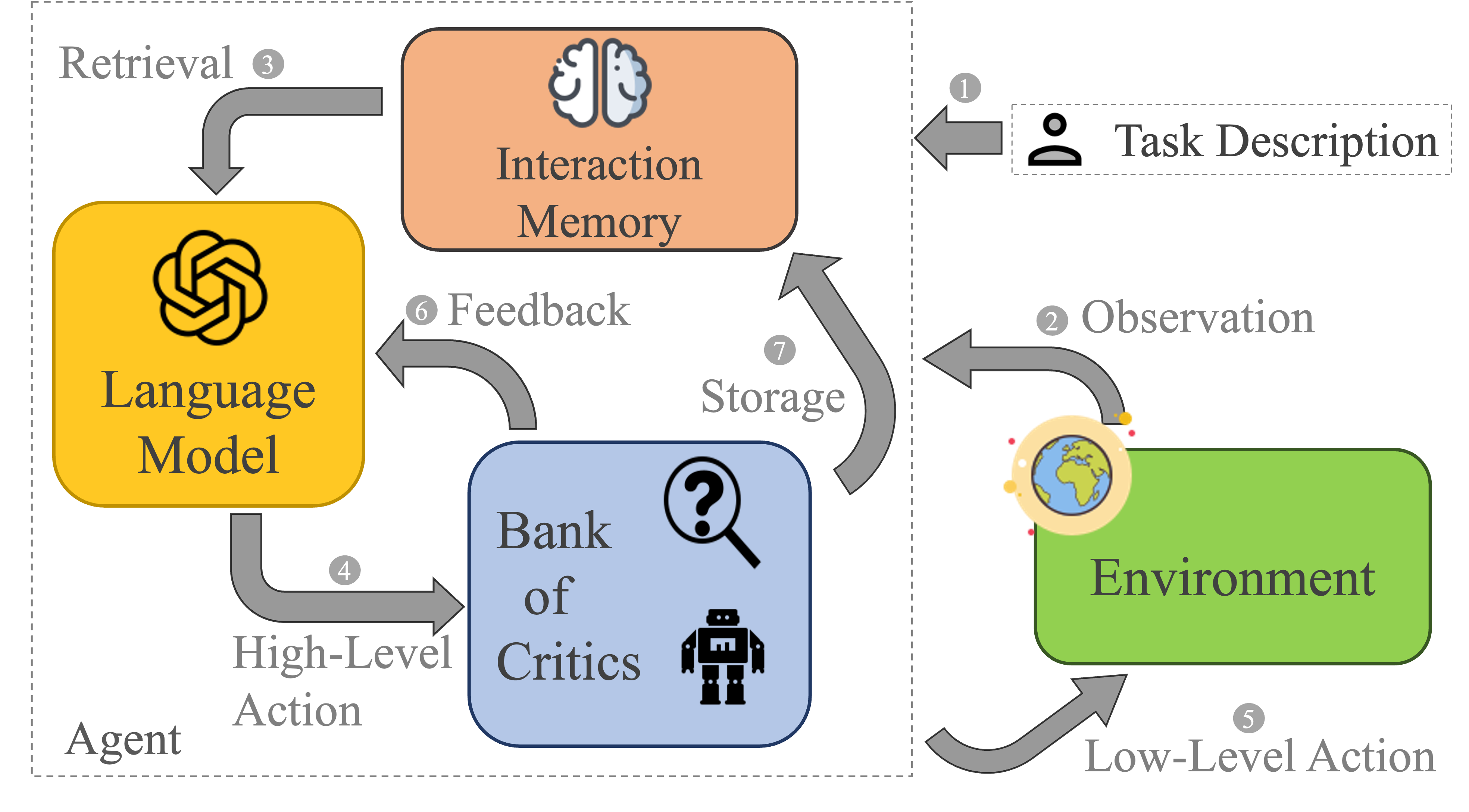
核心思路:RAG-Modulo的核心思路是为LLM智能体配备一个可更新的记忆模块,用于存储和检索过去的交互经验。通过将相关的历史经验作为上下文信息提供给LLM,智能体可以更好地理解当前状态,并做出更明智的决策。同时,利用评论家(Critic)对智能体的行为进行评估,进一步指导其学习过程。
技术框架:RAG-Modulo框架主要包含三个模块:LLM智能体、记忆模块和评论家。LLM智能体负责生成动作序列,记忆模块存储过去的交互经验,评论家评估智能体的行为。整体流程如下:1) 智能体根据当前状态生成动作;2) 执行动作并观察环境反馈;3) 将状态、动作和反馈存储到记忆模块中;4) 从记忆模块中检索相关的历史经验;5) 将检索到的经验作为上下文信息输入到LLM中,指导其生成下一个动作;6) 评论家评估智能体的行为,并提供反馈信号,用于更新LLM和记忆模块。
关键创新:RAG-Modulo的关键创新在于将检索增强生成(RAG)的思想引入到LLM机器人智能体中,使其能够利用历史经验进行决策。与传统的基于LLM的智能体相比,RAG-Modulo具有更强的适应性和学习能力。此外,通过结合评论家,可以更有效地指导智能体的学习过程。
关键设计:记忆模块的设计至关重要,需要考虑如何存储和检索相关的历史经验。论文中可能采用了某种向量数据库或相似度搜索算法来实现高效的经验检索。评论家的设计也需要仔细考虑,需要能够准确评估智能体的行为,并提供有用的反馈信号。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有详细描述,但此处未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RAG-Modulo在BabyAI和AlfWorld两个具有挑战性的环境中,显著提高了任务成功率和效率。具体而言,RAG-Modulo在任务成功率方面超越了最先进的基线方法,并且在完成任务所需的交互次数方面也表现出明显的优势。这些结果证明了RAG-Modulo框架的有效性和优越性。
🎯 应用场景
RAG-Modulo框架具有广泛的应用前景,可应用于各种需要智能体进行序列决策的任务,例如机器人导航、任务规划、游戏AI等。通过利用历史经验进行学习,RAG-Modulo可以显著提高智能体的性能和效率,使其能够更好地适应复杂和动态的环境。该研究的未来影响在于推动了基于LLM的机器人智能体的发展,使其能够更好地解决实际问题。
📄 摘要(原文)
Large language models (LLMs) have recently emerged as promising tools for solving challenging robotic tasks, even in the presence of action and observation uncertainties. Recent LLM-based decision-making methods (also referred to as LLM-based agents), when paired with appropriate critics, have demonstrated potential in solving complex, long-horizon tasks with relatively few interactions. However, most existing LLM-based agents lack the ability to retain and learn from past interactions - an essential trait of learning-based robotic systems. We propose RAG-Modulo, a framework that enhances LLM-based agents with a memory of past interactions and incorporates critics to evaluate the agents' decisions. The memory component allows the agent to automatically retrieve and incorporate relevant past experiences as in-context examples, providing context-aware feedback for more informed decision-making. Further by updating its memory, the agent improves its performance over time, thereby exhibiting learning. Through experiments in the challenging BabyAI and AlfWorld domains, we demonstrate significant improvements in task success rates and efficiency, showing that the proposed RAG-Modulo framework outperforms state-of-the-art baselines.